 播面
播面 如何在 Netty 中自定义编解码器?
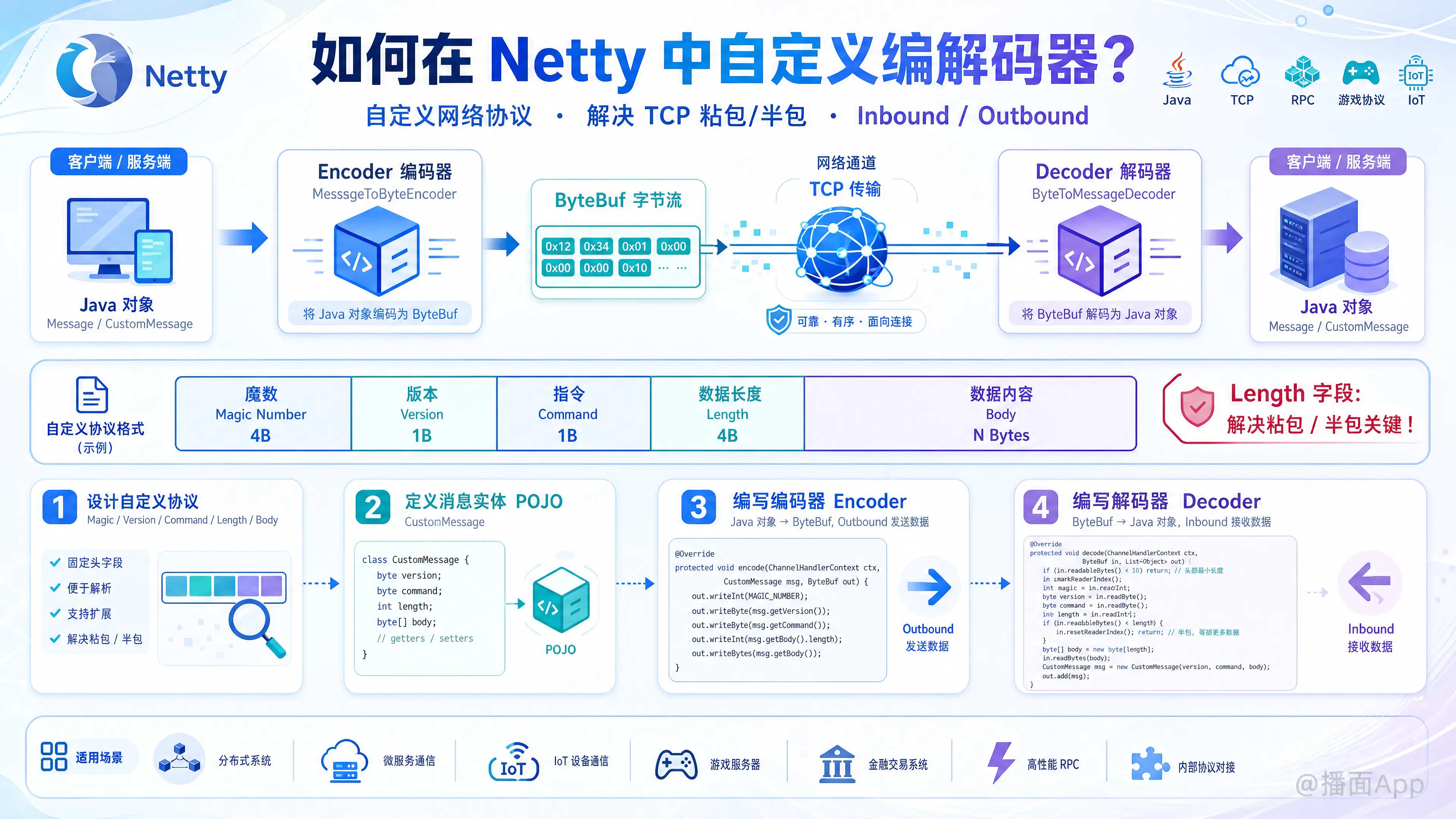
在 Netty 中自定义编解码器(Codec)是开发自定义网络协议(如 RPC 框架、游戏协议、物联网协议等)的核心步骤。
Netty 提供了强大的基础类来实现这一功能。编解码主要分为两部分:
- 编码器(Encoder): 将 Java 对象(Message)转换为字节流(ByteBuf),用于发送数据(Outbound)。
- 解码器(Decoder): 将字节流(ByteBuf)转换为 Java 对象(Message),用于接收数据(Inbound)。
下面我将通过一个完整的实战例子,带你一步步在 Netty 中自定义编解码器。
第一步:设计自定义协议
在编写代码之前,必须先明确你的协议格式。为了解决 TCP 的“粘包”和“半包”问题,通常需要在协议中包含长度字段。
假设我们设计如下一个简单的自定义协议:
plaintext
+--------------+-----------+------------+---------------+-------------+
| 魔数 (4字节) | 版本(1字节)| 指令(1字节) | 数据长度(4字节) | 数据内容(N字节)|
+--------------+-----------+------------+---------------+-------------+- 魔数 (Magic Number):用于快速识别是否是我们的协议(例如
0xCAFEBABE)。 - 版本号 (Version):用于后续协议升级。
- 指令 (Command):表示这条消息的作用(如登录、心跳、业务请求等)。
- 数据长度 (Length):标识后面“数据内容”的字节数,这是解决粘包/半包的关键。
- 数据内容 (Body):实际的业务数据(通常是 JSON、Protobuf 等序列化后的字节数组)。
第二步:定义消息实体类(POJO)
根据协议,定义一个 Java 类来在内存中表示这条消息。
java
public class CustomMessage {
private int magicNumber;
private byte version;
private byte command;
private int length;
private byte[] body;
// 省略 Getter、Setter 和 构造方法
// toString() 方法
}第三步:编写编码器(Encoder)
编码器负责把 CustomMessage 转换成 ByteBuf。我们通常继承 MessageToByteEncoder<T>。
java
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.MessageToByteEncoder;
public class CustomEncoder extends MessageToByteEncoder<CustomMessage> {
@Override
protected void encode(ChannelHandlerContext ctx, CustomMessage msg, ByteBuf out) throws Exception {
// 1. 写入魔数 (4字节)
out.writeInt(msg.getMagicNumber());
// 2. 写入版本号 (1字节)
out.writeByte(msg.getVersion());
// 3. 写入指令 (1字节)
out.writeByte(msg.getCommand());
// 4. 写入数据内容及长度
byte[] body = msg.getBody();
if (body != null && body.length > 0) {
out.writeInt(body.length); // 写入长度 (4字节)
out.writeBytes(body); // 写入实际数据
} else {
out.writeInt(0); // 如果没有数据,长度为0
}
}
}第四步:编写解码器(Decoder)
解码器负责把接收到的 ByteBuf 转换成 CustomMessage。通常继承 ByteToMessageDecoder。
注意: 在这里处理粘包和半包非常繁琐。Netty 强烈建议使用内置的 LengthFieldBasedFrameDecoder 先进行长度截断,然后再用我们自定义的解码器。这样自定义解码器只需要关心一个完整的数据包即可。
方案 A:手写解码器(包含处理半包逻辑 - 了解原理)
java
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.ByteToMessageDecoder;
import java.util.List;
public class CustomDecoder extends ByteToMessageDecoder {
// 协议头部的固定长度:魔数(4) + 版本(1) + 指令(1) + 长度(4) = 10字节
private static final int HEADER_LENGTH = 10;
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
// 1. 检查是否有足够的字节来读取协议头 (解决半包)
if (in.readableBytes() < HEADER_LENGTH) {
return;
}
// 2. 标记当前读取位置,如果后面发现数据不够,可以回退到这里
in.markReaderIndex();
// 3. 读取并校验魔数
int magic = in.readInt();
if (magic != 0xCAFEBABE) {
// 魔数不对,直接关闭连接或抛出异常
ctx.close();
return;
}
// 4. 读取版本和指令
byte version = in.readByte();
byte command = in.readByte();
// 5. 读取数据长度
int length = in.readInt();
// 6. 检查是否有足够的数据体 (解决半包)
if (in.readableBytes() < length) {
// 数据不够,回退到标记位置,等待下一次数据到达
in.resetReaderIndex();
return;
}
// 7. 读取数据体
byte[] body = new byte[length];
in.readBytes(body);
// 8. 组装成对象,传递给下一个 Handler
CustomMessage msg = new CustomMessage();
msg.setMagicNumber(magic);
msg.setVersion(version);
msg.setCommand(command);
msg.setLength(length);
msg.setBody(body);
out.add(msg);
}
}方案 B:最佳实践(LengthFieldBasedFrameDecoder + MessageToMessageDecoder)
不要自己去写 markReaderIndex 和 resetReaderIndex,让 Netty 帮你做!
二次解码器:
java
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.MessageToMessageDecoder;
import java.util.List;
// 注意这里继承的是 MessageToMessageDecoder,因为上一步传过来的是完整的 ByteBuf Frame
public class CustomMessageDecoder extends MessageToMessageDecoder<ByteBuf> {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
// 走到这里时,in 绝对是一个完整的数据包,直接无脑读即可
int magic = in.readInt();
byte version = in.readByte();
byte command = in.readByte();
int length = in.readInt();
byte[] body = new byte[length];
in.readBytes(body);
CustomMessage msg = new CustomMessage();
msg.setMagicNumber(magic);
msg.setVersion(version);
msg.setCommand(command);
msg.setLength(length);
msg.setBody(body);
out.add(msg);
}
}第五步:在 Pipeline 中注册编解码器
最后,我们需要在 ChannelInitializer 中把这些 Handler 加入到 Pipeline 中。顺序非常重要!
java
import io.netty.channel.ChannelInitializer;
import io.netty.channel.socket.SocketChannel;
import io.netty.handler.codec.LengthFieldBasedFrameDecoder;
public class CustomChannelInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
// ====== 入站 (Inbound) 处理顺序:1 -> 2 -> 3 ======
// ====== 出站 (Outbound) 处理顺序:倒序 ======
// 1. 拆包器:解决粘包/半包(推荐用法)
// 参数:最大包长,长度字段偏移量(魔数4+版本1+指令1=6),长度字段占几字节(4)
ch.pipeline().addLast(new LengthFieldBasedFrameDecoder(1024 * 1024, 6, 4));
// 2. 自定义解码器 (ByteBuf -> CustomMessage)
ch.pipeline().addLast(new CustomMessageDecoder());
// 3. 自定义编码器 (CustomMessage -> ByteBuf)
ch.pipeline().addLast(new CustomEncoder());
// 4. 业务处理器 (处理 CustomMessage)
ch.pipeline().addLast(new CustomBusinessHandler());
}
}总结与避坑指南
- 粘包和半包: 永远不要假设你一次
read()操作能读到一个完整的数据包。强烈建议使用 Netty 自带的LengthFieldBasedFrameDecoder配合自定义的二次解码器。 - Pipeline 的顺序: 解码器(Decoder)通常放在 Inbound 的最前面;编码器(Encoder)属于 Outbound,只要放在业务 Handler 的前面即可(Outbound 是从后往前执行的)。
@Sharable注解:- 继承了
ByteToMessageDecoder的解码器绝对不能标注@Sharable,因为它是有状态的(里面保存了半包的累加数据),必须每个 Channel new 一个实例。 - 如果你的
MessageToByteEncoder中没有成员变量(无状态),可以标记@Sharable,在所有 Channel 间复用一个实例。
- 继承了
- 内存泄漏: 继承
ByteToMessageDecoder或是MessageToMessageDecoder时,Netty 框架通常会自动帮你release()输入的 ByteBuf,不需要手动释放。但如果你在解码过程中自己创建了新的 ByteBuf 并丢弃,请记得释放。