 播面
播面 如何配置 Nginx 以支持后端服务器的被动健康检查和主动健康检查?
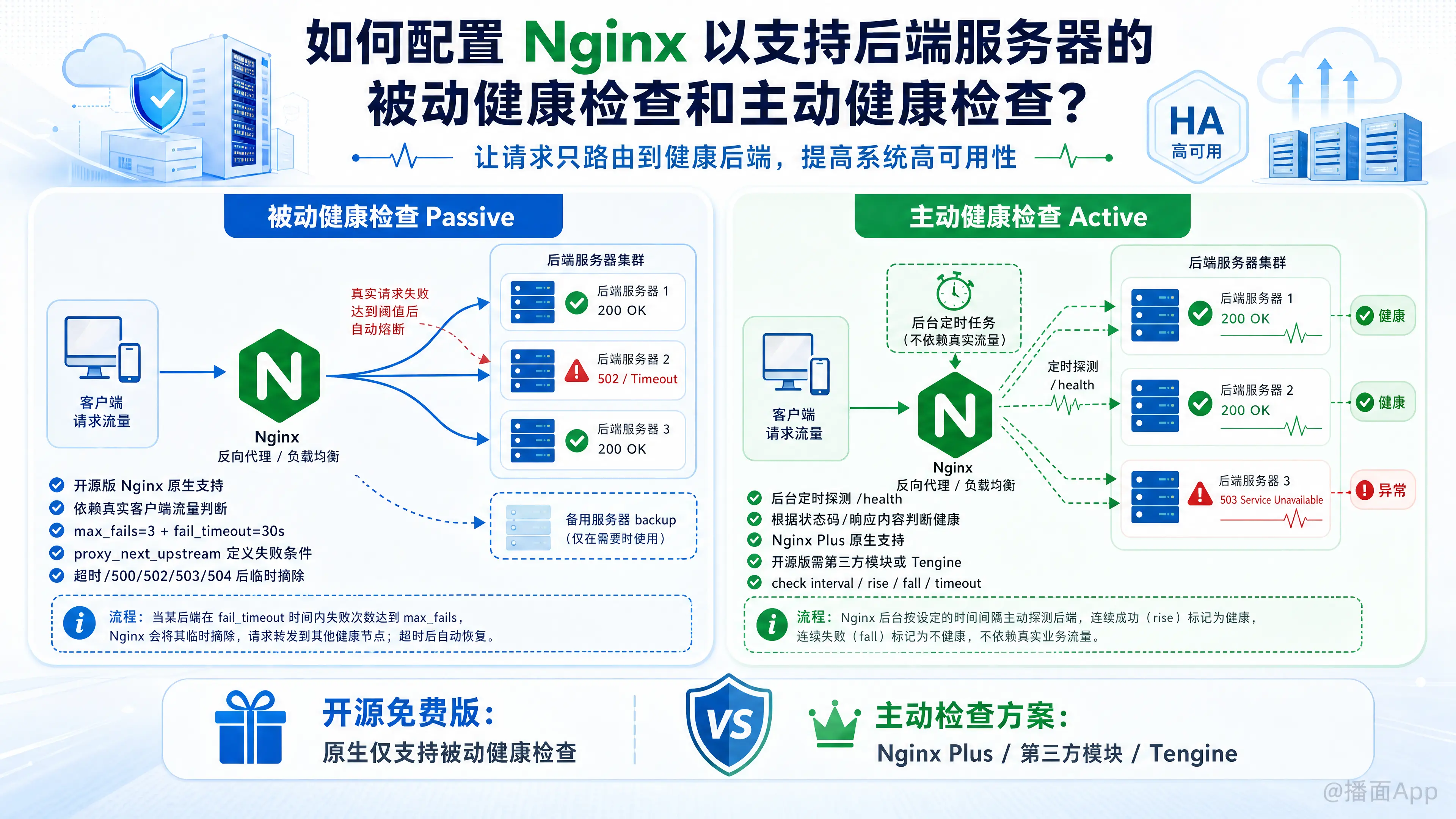
在 Nginx 中配置健康检查可以确保请求只会被路由到健康的后端服务器,从而提高整个系统的高可用性。
Nginx 的健康检查分为被动健康检查(Passive Health Checks)和主动健康检查(Active Health Checks)。
需要特别注意的是:开源免费版的 Nginx 原生只支持被动健康检查。如果要使用主动健康检查,可以通过使用商业版(Nginx Plus)、重新编译加入第三方模块,或者使用基于 Nginx 的分支(如 Tengine)。
下面是具体的配置方法:
一、 被动健康检查(Passive Health Checks)
适用版本:所有版本(开源版 Nginx 和 Nginx Plus 均支持)。
工作原理:Nginx 依靠真实的客户端流量来判断后端状态。如果 Nginx 转发请求给某台后端服务器失败达到一定次数,Nginx 会将该服务器标记为“不可用”一段时间,在此期间不再将请求转发给它。
配置示例:
修改 nginx.conf 中的 upstream 模块:
plaintext
http {
upstream backend_servers {
# max_fails: 允许请求失败的次数,默认为 1。
# fail_timeout: 在此时间内发生 max_fails 次失败,则认为服务器宕机;且宕机后的恢复等待时间也是这个值。默认为 10s。
server 192.168.1.10:8080 max_fails=3 fail_timeout=30s;
server 192.168.1.11:8080 max_fails=3 fail_timeout=30s;
# 备用服务器,只有当上面两台都 down 掉时,才会使用这一台
server 192.168.1.12:8080 backup;
}
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://backend_servers;
# 定义什么样的情况算作“失败”(配合 max_fails 使用)
proxy_next_upstream error timeout http_500 http_502 http_503 http_504;
}
}
}参数解析:
- 当
192.168.1.10在 30秒内 发生 3次 失败(失败的定义由proxy_next_upstream决定,如超时或502错误)时,Nginx 会将其标记为 down。 - 在接下来的 30秒 内,Nginx 不会发送任何请求给这台服务器。
- 30秒过后,Nginx 会尝试将一个客户端请求转发给它。如果成功,则认为它恢复健康;如果再次失败,则继续标记为 down 30秒。
二、 主动健康检查(Active Health Checks)
工作原理:Nginx 在后台定时向后端服务器发送探测请求(如 HTTP GET /health),根据服务器的响应(如状态码是否为 200)来判断其是否健康,而不依赖于真实的客户端流量。
因为开源版和商业版的实现方式不同,这里分两种情况:
情况 A:使用开源版 Nginx + 第三方模块(最常用)
开源版 Nginx 需要重新编译并添加淘宝开源的 nginx_upstream_check_module 模块,或者直接使用自带该模块的 Tengine。
配置示例(基于 nginx_upstream_check_module):
plaintext
http {
upstream backend_servers {
server 192.168.1.10:8080;
server 192.168.1.11:8080;
# 主动健康检查配置
# interval: 检查间隔,单位为毫秒(这里是3秒)
# rise: 连续成功多少次认为服务器是健康的(这里是2次)
# fall: 连续失败多少次认为服务器宕机(这里是3次)
# timeout: 健康检查的超时时间,单位为毫秒(这里是2秒)
# type: 检查类型(支持 tcp, http, ssl_hello, mysql 等)
check interval=3000 rise=2 fall=3 timeout=2000 type=http;
# 发送的 HTTP 探针请求内容
check_http_send "HEAD /health_check HTTP/1.0\r\n\r\n";
# 期望返回的 HTTP 状态码
check_http_expect_alive http_2xx http_3xx;
}
server {
listen 80;
location / {
proxy_pass http://backend_servers;
}
# 可选:提供一个健康检查状态的监控页面
location /status {
check_status;
access_log off;
# 建议加上访问控制
# allow 127.0.0.1;
# allow 192.168.1.0/24;
# deny all;
}
}
}情况 B:使用 Nginx Plus(官方商业版)
如果你使用的是商业版的 Nginx Plus,可以直接使用原生的 health_check 指令。
配置示例(Nginx Plus):
plaintext
http {
upstream backend_servers {
# 必须配置 zone,用于在所有 worker 进程间共享状态
zone backend 64k;
server 192.168.1.10:8080;
server 192.168.1.11:8080;
}
# 定义健康检查的匹配规则
match conditions {
status 200;
header Content-Type = text/html;
body ~ "OK";
}
server {
listen 80;
location / {
proxy_pass http://backend_servers;
# 开启主动健康检查
# interval: 检查间隔
# passes: 连续成功多少次算健康
# fails: 连续失败多少次算不健康
# uri: 检查的接口路径
# match: 匹配上面定义的 conditions
health_check interval=5s passes=2 fails=3 uri=/health match=conditions;
}
}
}总结与建议
- 基本场景:如果没有特殊需求,开源版的 被动健康检查 (
max_fails) 已经能满足 80% 的需求。 - 高要求场景:如果后端服务器启动较慢,或者希望在请求到达前就剔除故障节点,必须使用主动健康检查。
- 技术选型:
- 预算充足:直接购买 Nginx Plus。
- 零预算且不想折腾:更换为 Tengine (阿里开源),内置了主动健康检查。
- 零预算且技术能力强:在现有的 Nginx 源码上打补丁并编译
nginx_upstream_check_module。