 播面
播面 Paimon 针对对象存储设计了哪些专门的优化策略(如 Object Storage Optimization)?
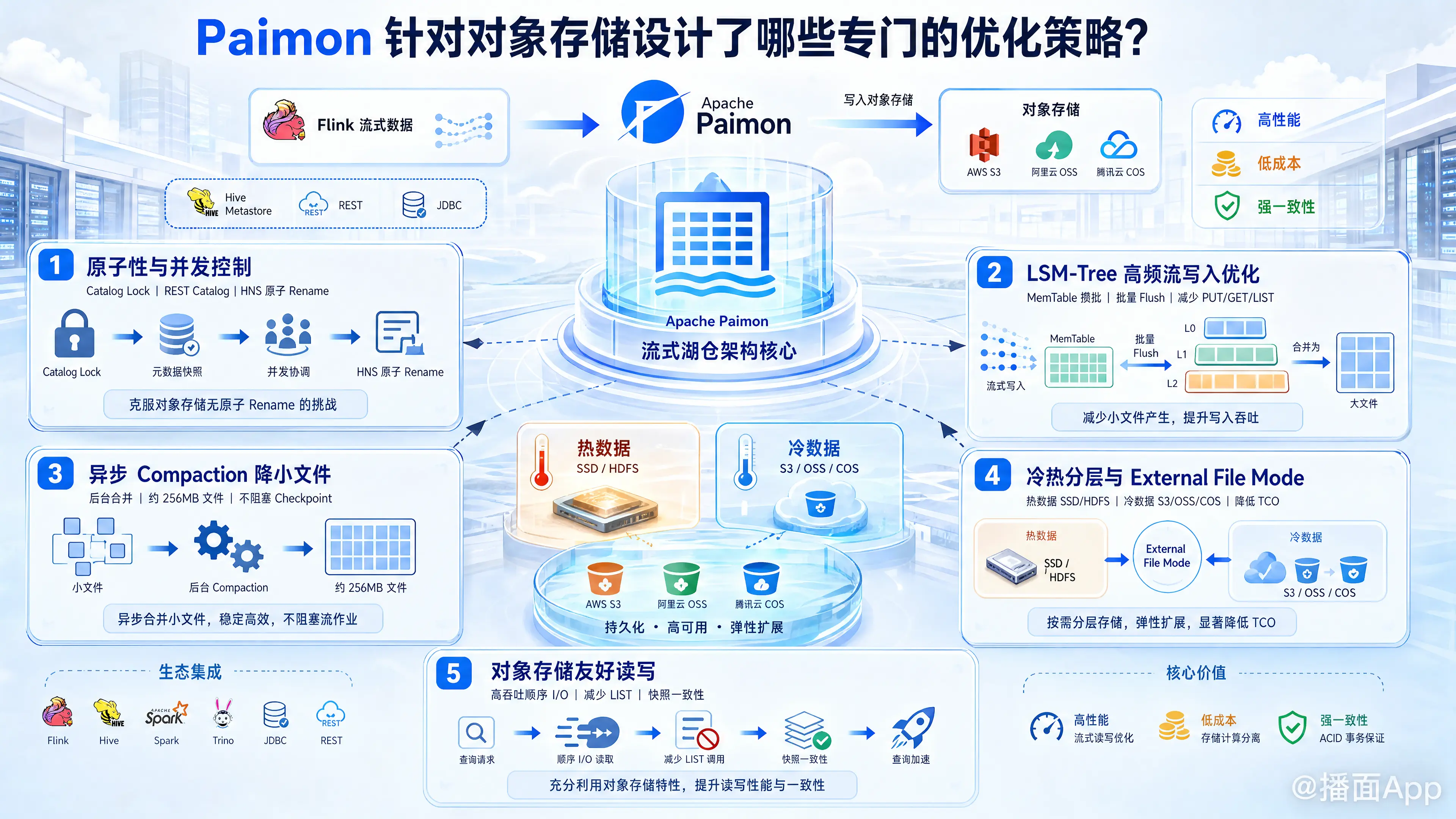
Apache Paimon 是专门针对流式湖仓(Streaming Lakehouse)设计的存储格式。由于大部分企业和用户都会选择将数据湖构建在低成本、高弹性的云对象存储(如 AWS S3、阿里云 OSS、腾讯云 COS 等)之上,Paimon 针对对象存储在性能、成本和强一致性等方面的局限性(例如缺乏真正的原子 Rename 语义、高频写入产生的小文件导致 API 费用暴增、网络 I/O 延迟高等),在架构上设计了多项专门的优化策略。
以下是 Paimon 针对对象存储设计的核心优化策略和相关机制的详细解析:
1. 解决原子性与并发冲突问题(克服对象存储无原子 Rename 缺陷)
在传统的 HDFS 分布式文件系统中,事务提交和快照(Snapshot)的原子写入高度依赖文件系统的原子 rename(重命名)操作。然而,绝大多数标准的云对象存储(如扁平结构的 S3 或 OSS)其 rename 并不是原子操作,而是通过“复制(Copy)+ 删除(Delete)”来模拟实现的,不仅耗时而且在高并发下容易发生部分成功、部分失败的异常情况。
为此,Paimon 提供了以下并发控制和提交优化:
- 外部目录锁协调(Catalog Lock):
当使用 S3 或 OSS 扁平桶作为底层存储时,Paimon 支持结合 Hive Metastore 或 JDBC Metastore,并开启'lock.enabled' = 'true'选项。这样多并发写入作业在提交 Snapshot 时,可以通过外部数据库提供的分布式锁进行协调,避免了因对象存储模拟 Rename 导致的冲突或快照丢失。 - 轻量级 REST Catalog:
Paimon 支持 REST Catalog。该机制将客户端对文件系统的 Rename 原语依赖剥离,交由统一的 Catalog 服务端(REST Server)进行协调,从而在对象存储架构下实现更为优雅、高解耦的元数据并发控制。 - 云原生分层桶机制集成(如 HNS):
针对支持“分层命名空间”(Hierarchical Namespace, 如火山引擎 TOS HNS、部分并行文件系统)的对象存储,Paimon 能够透明地直接利用其真正的目录级 mv/rename 原子语义,无需再额外配置数据库外部锁机制即可保证并发写入的强一致性。
2. 基于 LSM-Tree 的高频流写入与自适应合并(降低 API 请求成本)
对象存储在计费上对于 API 请求次数(如 PUT/GET/LIST 等请求)非常敏感。如果 Flink 等流计算引擎以秒级/分钟级的频率不断向对象存储写入小文件,将引发两大痛点:一是小文件过多导致下游 OLAP 查询性能雪崩;二是高频 API 调用带来的巨大成本开销。
- LSM-Tree 的天然缓冲:
Paimon 底层采用 LSM-Tree (Log-Structured Merge-Tree) 的存储结构。数据首先写入本地内存缓冲区(MemTable),达到阈值或攒批后,才批量、有序地刷写(Flush)成较大的数据文件。这种机制大幅减少了直接写入对象存储的频次,降低了 PUT 请求的数量。 - 完全异步合并(Asynchronous Compaction):
Paimon 提供了完全异步的文件合并机制。小文件写入后,后台异步服务会对其进行合并排序(Compaction),合并后的文件通常推荐控制在 256MB 左右,这正是对象存储(如 S3/OSS)读取带宽的最佳实践块大小。由于合并完全在后台平滑进行,不会阻塞流作业的 Checkpoint,既提升了写入吞吐,又避免了小文件引起的元数据膨胀。
3. 多级存储与冷热分层(External File Mode 降低 TCO)
为了实现更极致的降本增效,用户通常希望将近期需要高频读写或需要流式消费的“热数据”保存在高性能的存储介质上(如 SSD 或本地 HDFS),而将历史“冷数据”无缝迁移到更便宜的对象存储中。
- 外部路径写入策略(External File Mode):
Paimon 提供了data-file.external-paths(外部数据文件路径)和data-file.external-paths.strategy(路径选择策略)参数。 - 存储布局隔离:
以前 Paimon 的元数据(Manifest)与数据文件只能存放在同一个表根目录下。启用外部路径模式后,Paimon 允许元数据保留在高性能的物理位置,而将部分分区或部分历史文件在写入时,通过策略(如specific-fs指向s3或oss)定向输出到远端对象存储中,极大地节约了存储成本(TCO)。
4. 针对非结构化数据管理的 Object Table(对象表优化)
云对象存储不仅常用来存放表格等结构化数据,也是图片、音视频、PDF、雷达点云等海量非结构化数据的首选归宿。AI 时代为了打破“结构化”与“非结构化”的数据壁垒,Paimon 引入了 Object Table 功能。
- 文件元数据索引化:
Object Table 允许用户指定一个对象存储(OSS/S3/COS等)目录,Paimon 会在后台自动为其中的非结构化数据对象创建并维护“元数据索引”。它会将文件的名称、路径、大小、最近修改时间、甚至图片的分辨率、音频时长等结构化属性抽取并组织成一张表。 - 多模态与 AI 工作流融合:
用户可以直接在 SQL/Python 中像查询普通表一样检索这些存储在对象存储中的原始文件,然后通过 AI 模型或预测函数(例如向量化模型、图像分类等),直接对表中的文件路径进行点对点读取、推理和查询改写。
5. 读性能提升:异步 I/O 与高吞吐拉取
在数据读取和消费阶段,对象存储通常由于网络和协议限制存在较高的初始读取延迟。Paimon 进行了多方面的读写侧软硬件适配:
- 异步文件写入(
async-file-write):
默认为true,利用异步线程将本地数据块输出到对象存储中,最大限度消除对象存储的高写入延迟对流式摄入(Sink)造成的背压风险。 - 精准的数据 Skipping(裁剪):
由于扫描对象存储的代价非常昂贵,Paimon 在 Manifest 文件、File Index 等层面上提供了丰富的 min/max 过滤以及增强的 Bitmap Index(如 V2 升级版)。查询计划在生成阶段就能直接“裁剪”掉不符合条件的分区和物理文件,极大减少了对对象存储发送的 GET 请求数。 - 与 OLAP 引擎协同的 Data Cache & Merge I/O:
下游查询引擎(如 StarRocks、Apache Doris 等)在读取 Paimon 湖数据时,可以通过其规整的 LSM-Tree 文件布局,将频繁访问的远端对象存储数据块缓存至本地 SSD/内存(Data Cache)中。同时,通过 Merge I/O 技术将相邻的、微小的读取操作合并为单次的大请求读取,在降低对象存储 I/O 次数的同时,提高整体的吞吐表现。