 播面
播面 IoT 传感器实时上报环境温度,由于网络延迟,数据严重乱序(例如 12:05 产生的数据在 12:10 接收到,而 12:08 产生的数据早已入库)。为了确保 Paimon 表中始终保留传感器最新的状态值,应该如何配置 sequence.field?
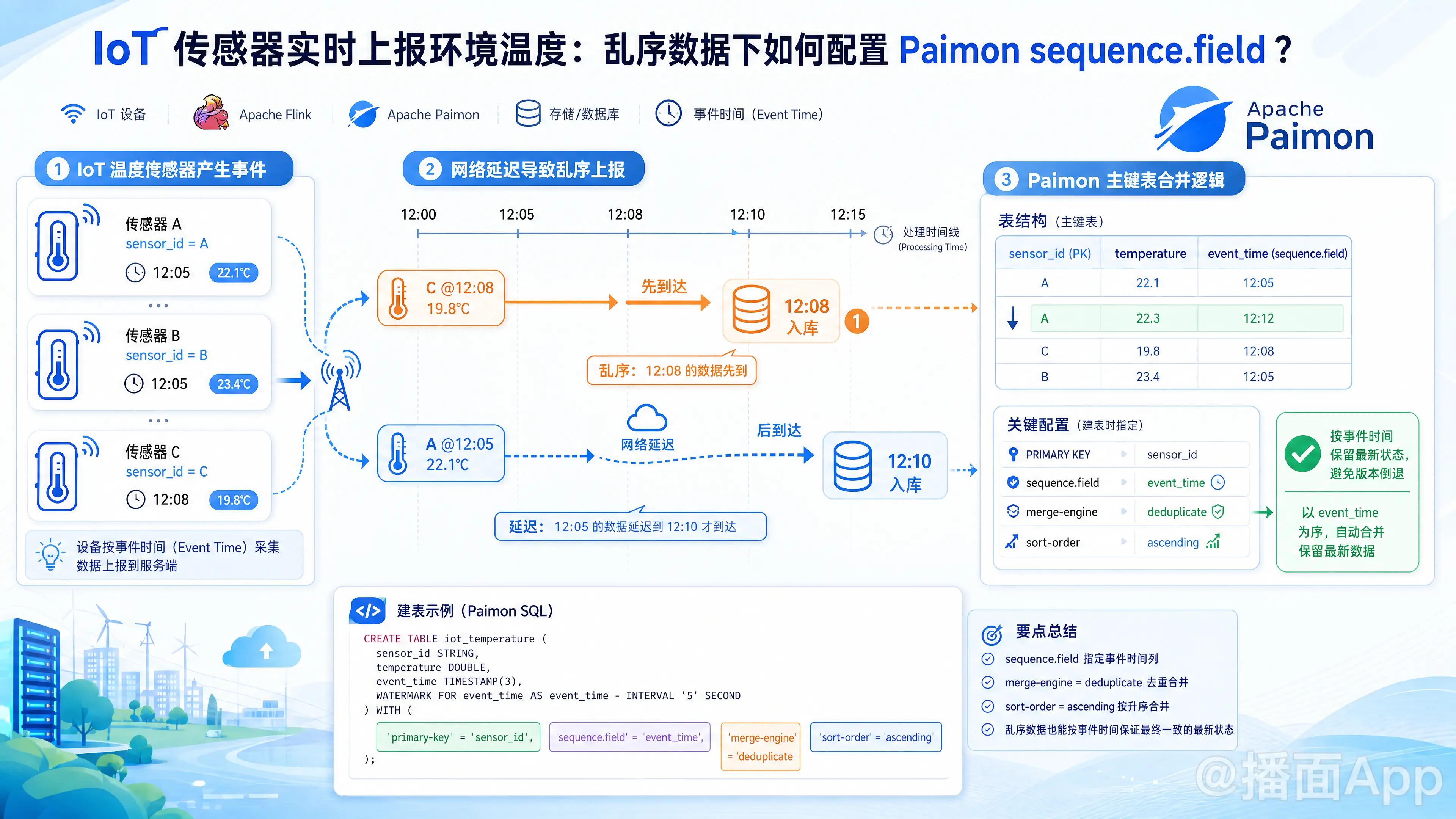
在物联网(IoT)场景中,由于网络延迟、边缘计算节点缓存或重传机制,数据乱序上报是非常常见的问题。为了确保 Apache Paimon 主键表(Primary Key Table)中始终保留传感器基于事件时间(Event Time)的最新状态,我们需要利用 Paimon 提供的 sequence.field 配置。
以下结合 Apache Paimon 的官方文档(Master 分支)及实际生产经验,为您详细介绍如何配置和使用 sequence.field 来解决该乱序问题。
一、 乱序问题的根源与 Paimon 的默认机制
默认机制(按写入顺序,Last-Write-Wins)
如果不配置sequence.field,Paimon 的主键表在合并数据(Merge)时,默认会采用输入/写入顺序(Input Order)。也就是说,物理上最后到达 Paimon 的数据会覆盖之前的数据。- 在您的场景中: 12:05 产生的数据在 12:10 迟到入库,而 12:08 产生的数据在 12:08 就已入库。由于 12:05 的数据后到达,它会无情地覆盖掉 12:08 的最新状态,导致数据产生“版本倒退”。
解决思路:引入“版本号”或“事件时间”
为了防止倒退,我们需要告诉 Paimon:合并数据时不要看谁物理上先到,而要看数据内含的“事件产生时间”(即数据版本)谁更大。这就是sequence.field的核心作用。
二、 如何配置 sequence.field?
为了保证 sensor(传感器)的温度始终处于最新状态,我们需要进行如下配置:
- 指定主键(Primary Key): 设置为传感器的唯一标识(如
sensor_id)。 - 指定
sequence.field: 设置为传感器的实际数据产生时间(如event_time)。 - 选择 Merge Engine: 使用默认的
deduplicate(去重引擎),它会根据sequence.field的比较结果,仅保留最新的一条完整记录。
Flink SQL 建表配置示例:
CREATE TABLE iot_sensor_temp (
sensor_id STRING,
temperature DOUBLE,
event_time TIMESTAMP(3), -- 传感器产生数据的时间(12:05、12:08等)
PRIMARY KEY (sensor_id) NOT ENFORCED
) WITH (
'connector' = 'paimon',
-- 1. 指定用于判断顺序的字段(此处使用事件时间字段)
'sequence.field' = 'event_time',
-- 2. 显式指定合并引擎为去重(如果不配,默认也是 deduplicate)
'merge-engine' = 'deduplicate'
);注意:
- 在 Paimon 中,
sequence.field.sort-order默认值为'ascending'(升序)。这意味着sequence.field值越大(即时间越新)的数据越会被保留,完全符合我们保留最新温度状态的要求。
三、 详细的工作机制与运行示例
在配置了 'sequence.field' = 'event_time' 之后,Paimon 的处理逻辑如下:
场景模拟:
- 数据 A(新):
(sensor_01, 25.0, 12:08)。于 12:08 正常上报并入库。 - 数据 B(旧/延迟):
(sensor_01, 22.0, 12:05)。由于网络延迟,在 12:10 才到达并尝试写入。
Paimon 内部处理流程:
- 数据 A 入库: Paimon 写入
sensor_01的数据,此时sequence.field(event_time)的值为12:08。 - 数据 B 延迟到达: 12:10 时,写入任务接收到数据 B。
- 触发 Merge(合并):
- Paimon 检测到主键
sensor_01冲突。 - 提取当前已存记录的数据 A 的
sequence.field(即12:08),与新输入的数据 B 的sequence.field(即12:05)进行对比。 - 比较结果:
12:08>12:05(既存数据的版本更新)。 - 决策: Paimon 判定输入的数据 B 是“过期”的迟到数据,因此丢弃数据 B(或者说不覆盖已有记录),继续在表中保留数据 A 的状态。
- Paimon 检测到主键
- 查询结果: 此时用户查询该表,得到的仍然是
(sensor_01, 25.0, 12:08),避免了数据状态被老数据污染。
四、 进阶与注意事项
根据 Paimon 文档和实践经验,在生产环境中应用 sequence.field 时还有以下细节需要注意:
支持的数据类型
sequence.field支持几乎所有主流数据类型(包括TIMESTAMP、TIMESTAMP_LTZ、BIGINT(毫秒时间戳)、INT等)。通常推荐使用高精度时间戳(如TIMESTAMP(3))或递增的BIGINT序列号。多字段联合排序(Master 分支特性)
如果单一的时间戳字段无法满足复杂的业务场景(例如同一毫秒内可能产生多条数据,需要通过另外的自增 ID 辅助去重),Paimon 支持定义多个字段作为 sequence,字段之间用逗号分隔:sql'sequence.field' = 'event_time, seq_id'Paimon 将会依次对比这些字段的值来决定谁是最新数据。
Flink 客户端的特殊配置
官方特别提示,为了防止 Flink 引擎在 Upsert 优化阶段引入不可预测的乱序行为,在向 Paimon 写入主键表时,强烈建议在 Flink SQL TableConfig 中将table.exec.sink.upsert-materialize设置为NONE:sqlSET 'table.exec.sink.upsert-materialize' = 'NONE';Merge Engine 为
partial-update时的特例
若您未来将合并引擎修改为了partial-update(多流拼接宽表场景),单凭sequence.field可能无法彻底解决多流写入的乱序问题。在这种情况下,应参考官方文档改用sequence-group(序列组) 机制,为各个字段组独立指定版本字段。