 播面
播面 Paimon 是如何支持跨分区主键更新这一特性的?
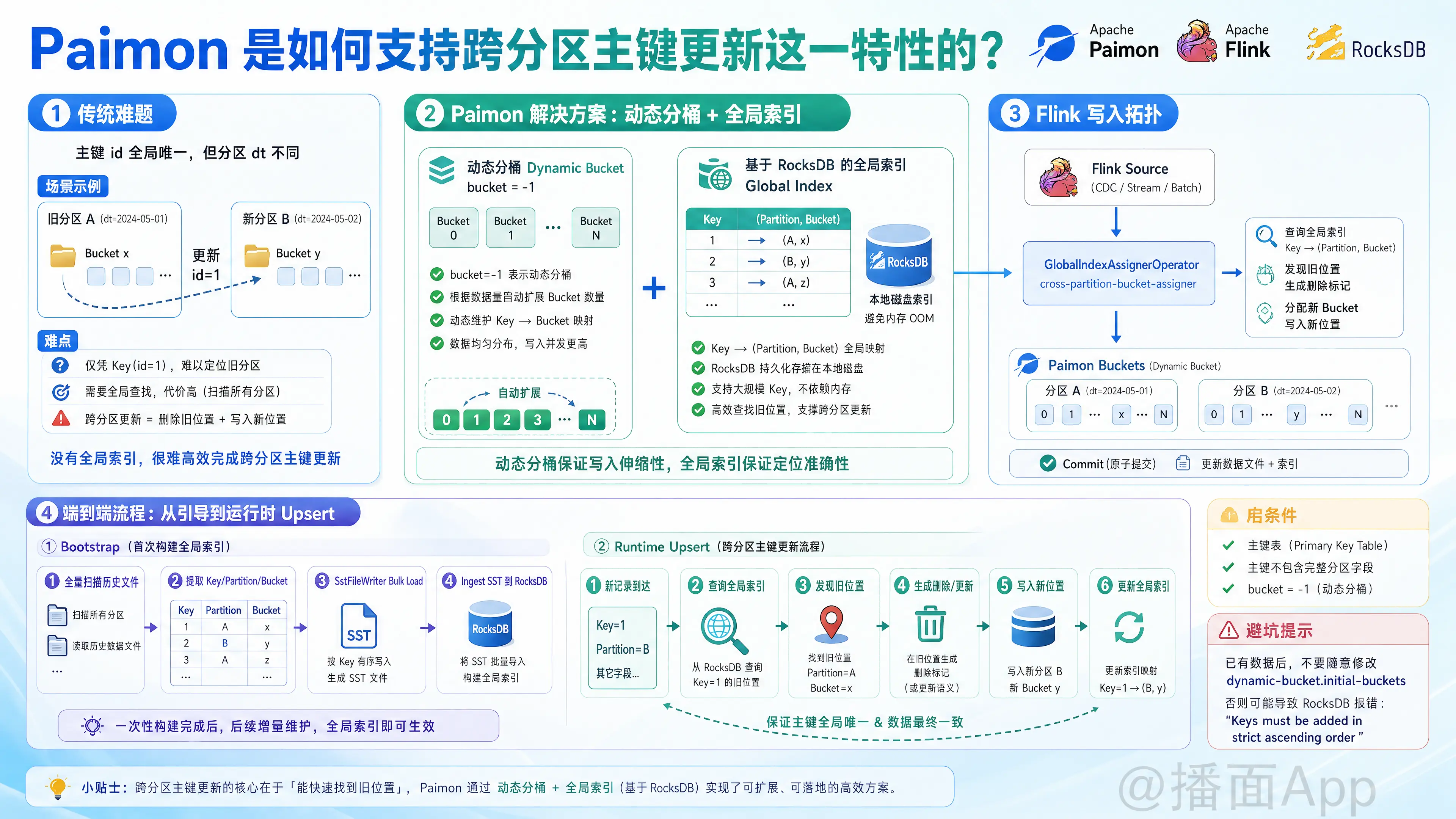
在 Apache Paimon 中,跨分区主键更新(Cross Partition Upsert)是一个非常核心且强大的特性。
在传统的数据湖或分布式存储中,如果一张表定义了分区,且主键(Primary Key)未包含所有的分区字段(即主键是全局唯一的,而分区键只是其中一部分或完全不相关),当一条带有新分区的新记录写入时,系统很难仅凭主键高效地定位到该数据之前存在于哪个旧分区中,从而无法完成“跨分区”的更新和去重。
Apache Paimon 通过动态分桶(Dynamic Bucket)机制与基于 RocksDB 的全局索引(Global Index),优雅地解决了这一难题。以下是该特性的详细实现原理、运行机制及相关配置。
一、 跨分区更新的启用条件
在 Paimon 中,要使用跨分区主键更新功能,通常需要满足以下表结构配置:
- 主键表:必须定义主键(Primary Key)。
- 未包含完整分区字段:主键列中不包含所有的分区列(例如:分区字段是
dt,而主键只有id)。 - 动态分桶模式(Dynamic Bucket):必须设置
'bucket' = '-1'(主键表的默认配置),此时 Paimon 会动态维护索引并自动扩展 Bucket。
二、 底层核心机制:全局索引(Global Index)
跨分区主键更新的核心在于全局索引。
- 非跨分区更新(主键包含所有分区字段):Paimon 在每个分区内使用内存 HASH 索引来维护
Key -> Bucket的映射,因为更新永远不会跑出当前分区,内存消耗较低。 - 跨分区更新:由于需要全局去重,Paimon 必须维护一个全局的
Key -> (Partition, Bucket)映射关系。如果将如此庞大的映射全部放在内存中,会导致严重的 OOM。因此,Paimon 选择利用本地磁盘,基于 RocksDB 来存储和维护这个全局索引。
在 Flink 写入作业中,Paimon 会引入一个名为 GlobalIndexAssignerOperator 的算子(在 Flink 拓扑中表现为 cross-partition-bucket-assigner),负责全局索引的维护和 Bucket 的分配。
三、 写入与更新的生命周期
跨分区主键更新的实现,主要分为初始化(Bootstrap)和运行时(Runtime)两个阶段:
1. 初始化引导阶段(Bootstrap)
当 Flink 流式写入作业启动或从 Checkpoint 恢复时,本地磁盘上的 RocksDB 索引可能并不完整(或是首次启动为空)。
- 全量扫描历史主键:Paimon 会在启动时,读取整个表中所有已存在的历史文件,提取出所有的
Key以及它们所属的Partition和Bucket。 - RocksDB 快速导入(Bulk Load):
- 为了在启动时能够快速构建数十亿级别的数据索引,Paimon 使用了 RocksDB 的 SstFileWriter 进行 Bulk Load(大批量导入)。它会将扫描出的主键有序排列,直接生成 SST 文件并 Ingest 到 RocksDB 中。
- 技术细节与避坑:由于
SstFileWriter强制要求写入的 Key 必须是严格升序的,在生产中切勿在表已有数据后修改'dynamic-bucket.initial-buckets'等分桶初始化参数。如果修改了该参数,会导致历史数据的 Bucket 映射计算逻辑发生改变,在 Bootstrap 阶段进行 Bulk Load 时会因顺序错乱而触发Keys must be added in strict ascending order的 RocksDB 异常。
2. 运行时 Upsert 处理阶段(Runtime)
当一条新数据 (Key=1, Partition=B, Value=New) 写入 Flink Sink 时,GlobalIndexAssignerOperator 会拦截这条数据,并在本地 RocksDB 索引中查找 Key=1:
若索引中不存在该 Key:
表明这是一条全新的数据。Paimon 将会根据动态分桶规则为其分配一个新 Bucket(例如Bucket=Y),在 RocksDB 中记录下Key=1 -> (Partition=B, Bucket=Y)的映射,并将数据正常写入 Partition B 的 Bucket Y 中。若索引中已存在该 Key(假设原纪录在
Partition=A, Bucket=X):
说明发生了跨分区的更新,此时 Paimon 会根据表配置的 Merge Engine(合并引擎) 采取不同的行为:Deduplicate(默认去重引擎):
Paimon 需要保证全局只有一个该主键的值。由于新旧数据分区不同,Paimon 会:- 自动下发一条 DELETE(撤回)物理记录到旧位置:
Partition=A, Bucket=X。 - 自动下发一条 INSERT 物理记录到新位置:
Partition=B, Bucket=Y。 - 更新本地 RocksDB 索引,将映射修改为
Key=1 -> (Partition=B, Bucket=Y)。
通过这种“先删旧、后建新”的机制,实现了物理层面和逻辑层面完美的全局唯一性。
- 自动下发一条 DELETE(撤回)物理记录到旧位置:
PartialUpdate(部分列更新)与 Aggregation(预聚合引擎):
这类引擎通常需要将新旧数据进行合并或累加。因为无法在不同的分区之间进行跨文件合并,Paimon 在这种情况下会妥协分区一致性,选择将新数据强行写入到旧的分区中(即写入Partition=A, Bucket=X),以保证 Merge 逻辑可以正常在同一个 Bucket 内的 LSM-Tree 中触发。FirstRow(首行保留引擎):
如果索引中已经存在该 Key,Paimon 会直接忽略并丢弃这条新写入的数据,保持原有分区和数据不变。
四、 性能调优与核心参数
跨分区主键更新虽然功能强大,但由于需要维护全局索引,会带来一定的启动延迟和运行时磁盘 I/O 损耗。Paimon 提供了以下关键参数来进行性能调优:
cross-partition-upsert.bootstrap-parallelism- 默认值:
10 - 作用:控制作业启动时,单个 Task 进行 Bootstrap(扫描历史 Key 并构建 RocksDB 索引)的并发度。如果历史数据量非常庞大(例如百亿级),可以调大此参数以显著缩短 Flink 作业启动的等待时间。
- 默认值:
cross-partition-upsert.index-ttl- 默认值:无
- 作用:RocksDB 索引的过期时间。对于许多业务场景(如订单、物流),跨分区更新往往只发生在近期(例如最近 30 天的数据会被修改,再往前的数据属于历史归档,绝不会被修改)。
- 优化效果:配置此 TTL 后,过期的历史 Key 会从本地 RocksDB 索引中清除,极大地减小了索引的体积和维护成本,并加快作业恢复速度。需要注意的是,如果确实有超过 TTL 的旧 Key 再次流入,系统由于索引已失效,会将其当作新 Key 处理,从而可能导致跨分区的数据重复。
五、 核心限制
在架构设计和生产落地时,需要注意跨分区主键更新的以下限制:
- 仅支持单作业写入:使用动态分桶(Dynamic Bucket)的表只能有一个 Flink 写入作业。如果有多个独立的 Flink Job 同时往同一个表/分区写数据,它们各自在本地 TM 维护的 RocksDB 全局索引无法共享与同步,从而会彻底破坏主键的唯一性约束,产生大量重复数据。