 播面
播面 广告点击流中,同一个用户在 24 小时内可能有数万条点击,但业务仅需要保留该用户的“首次点击”(First-Row)行为。为什么说 Paimon 的 First-row 合并引擎在 Flink 状态控制和磁盘读写性能上,远优于 Flink SQL 自带的有状态去重(Deduplicate)?它的底层拦截机制是怎样的?
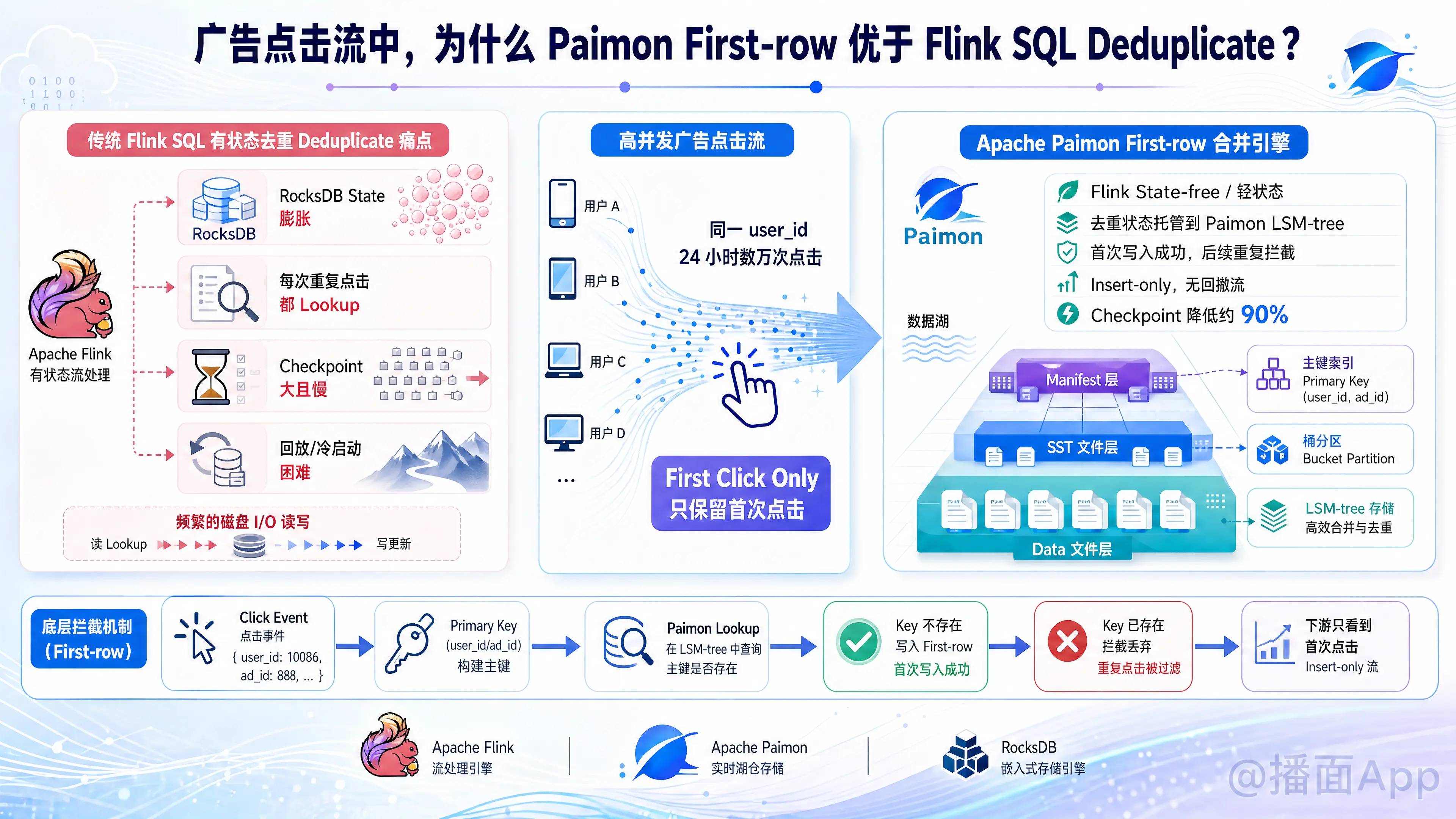
在广告点击流分析等高并发实时场景中,针对同一个用户在短时间内(如 24 小时内)产生数万次重复点击,但业务仅需要保留该用户的“首次点击”(First-Row)行为,Flink 传统的有状态去重(Deduplicate)确实会面临巨大的性能和存储痛点。
下面结合 Apache Paimon 官方文档与业界实践方案,为您详细剖析为什么 Paimon 的 First-row 合并引擎在 Flink 状态控制和磁盘 R/W 性能上表现更佳,以及其底层的拦截机制是如何运作的。
一、 传统 Flink SQL 有状态去重(Deduplicate)的痛点
在 Flink SQL 中,获取首次点击通常使用类似于以下的 ROW_NUMBER() 窗口去重语法:
SELECT * FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY click_time ASC) as row_num
FROM click_stream
) WHERE row_num = 1对于拥有数千万乃至上亿活跃用户、且单个用户频繁点击的广告流场景,这种实现方式存在以下主要瓶颈:
- Flink 状态(State)极度膨胀:
为了判断某个用户在 24 小时内是否已经点击过,Flink 必须在本地状态后端(通常是 RocksDB State Backend)中,以user_id(或user_id + ad_id)作为 Key 缓存所有已见过的用户标记。这意味着 Flink 需要在本地 SSD 磁盘中维护一个庞大的状态库,随着活跃用户量的增加,状态大小呈线性暴增。 - Checkpoint 延迟与吞吐受限:
由于 RocksDB 状态体积过大,Flink 在执行 Checkpoint 时的快照文件会变得非常臃肿,导致备份时间拉长、网络 I/O 开销飙升。一旦遇到状态对齐延迟或长尾效应,极易产生反压,使实时任务出现性能波动。 - 极高的本地磁盘 I/O 读写压力:
一个用户一天点击数万次,意味着 Flink 必须对该用户的状态执行数万次 RocksDB 的 Lookup(读)操作。即使第一次点击已经在状态中打上了标记,后续几万次点击依然需要不断去检索 RocksDB 的 SST 文件,从而引发严重的磁盘读取和缓存失效问题。 - 历史数据回放与冷启动困难:
如果任务由于业务变更需要“回刷”过去一段时间的数据,Flink 难以在短时间内重建如此庞大的本地 State,甚至无法直接通过外部静态表进行初始化,导致重算效率非常低下。
二、 为什么 Paimon 的 First-row 合并引擎远优于 Flink SQL
通过在 Paimon 表中指定 'merge-engine' = 'first-row' 并配合 'changelog-producer' = 'lookup',上述痛点可以得到针对性的解决:
- Flink 任务彻底“去状态化”(State-free):
Flink 作业本身不再需要通过本地的 RocksDB 状态去记录“哪些用户已点击过”,这些“去重状态”全部被托管到了数据湖存储层(Paimon 的 LSM-tree 结构)中。Flink 实时作业变成了一个几乎无状态(或仅有极轻量级状态)的纯写入任务,大幅释放了 Flink TaskManager 的内存和 CPU 资源。 - 大幅优化 Checkpoint 耗时与任务鲁棒性:
在实际生产案例(如蚂蚁集团双十一大促等场景)中,引入 Paimon First-row 方案后,Flink 任务的 CPU 使用率可下降约 60%,内存消耗降低 35%,Checkpoint 大小和耗时降幅可达 90%,任务回放与重置效率提升了数倍。 - 轻量级、无回撤的 Insert-Only 变更流:
普通的去重引擎(如 Deduplicate)在处理数据更新时,由于保留最新值,往往会向后发送-U(Update Before)和+U(Update After)的撤回消息。而 Paimon First-row 引擎由于仅保留最早的那一条,后续的点击直接被静默丢弃,只会向下游生成+I(Insert-only)的增量数据。这使得下游的 OLAP 引擎(如 StarRocks/Doris)或下游聚合任务可以以极低的成本直接处理追加流,无需承担回撤计算的巨大开销。
三、 Paimon First-row 的底层拦截机制
Paimon 是一个基于 LSM-tree(日志结构合并树)架构的数据湖存储系统。First-row 引擎能够做到如此高效的去重,核心在于其在写入/合并阶段的主键 Lookup 拦截机制:
┌──────────────────────────────┐
│ Flink Stream Input │ (包含同一个 Key 的数万次点击)
└──────────────┬───────────────┘
│
▼
┌──────────────────────────────┐
│ Paimon MemTable (Memory Buffer)
└──────────────┬───────────────┘
│ (Flush / Compaction)
▼
┌──────────────────────────────────────────────┐
│ Trigger Lookup & Compaction │
└──────────────────────┬───────────────────────┘
│
├─────────────────────────────┐
[Key K exists in high-level SST?] │ (No - First Click)
│ ▼
│ (Yes - Duplicate Click) ┌────────────────────────┐
▼ │ Write K to LSM Tree │
┌─────────────────────┐ │ Produce +I Changelog │
│ Intercept & Discard │ └────────────────────────┘
│ (不落盘,不写文件) │
└─────────────────────┘1. 内存缓冲(MemTable)阶段
Flink 算子将上游的点击数据写入 Paimon 时,首先会缓冲在内存的 MemTable(通常是基于堆的 LSM 内存树结构)中。
2. 触发后台 Lookup 查询
当 MemTable 满触发 Flush 写入 Level 0 数据文件,或者发生小文件 Compaction 时,为了实现 First-row 机制并向下游产生正确的 Insert-only 变化日志,Paimon 必须开启 changelog-producer = 'lookup'。
此时,Paimon 的 Writer 会在后台触发 Lookup 检索进程。
3. 极速的索引过滤与本地 SSD 缓存
为防止每次 Lookup 都去分布式文件系统(DFS)中遍历读取数据而引发严重的性能崩溃,Paimon 设计了多级过滤与缓存机制:
- Min-Max 与 Bloom Filter 粗筛:每个高层级的数据文件都自带 min/max 统计及 Bloom Filter 索引,这部分元数据长驻内存。Paimon 能够以接近 0 开销的方式直接判定:目标 Key 是否可能存在于该文件中。
- 本地磁盘 Lookup Cache 索引:Paimon 会在 TaskManager 的本地磁盘(通常是高性能本地 SSD)以及内存中建立 Key 与对应文件的映射缓存(利用 RocksDB 格式缓存)。Lookup 流程几乎所有的检索都会在极高速的本地缓存中完成,而不必请求 DFS。
4. 底层硬拦截与静默丢弃(Core Interception)
在进行 Lookup 检索时,底层的判断逻辑非常直接:
- 若 Key 已存在(非首次点击):Paimon 判定该点击行为为重复数据,直接在内存或 Compaction 节点中将其丢弃(Discard)。该数据既不会写入高层级的 SST 文件中导致存储膨胀,也不会向下游下发任何 Changelog。这也是为什么“数万次无用点击”不会导致 Paimon 磁盘 I/O 负载崩溃的根本原因。
- 若 Key 不存在(首次点击):判定为该用户的 First-row 行为,允许将该记录正常向下游发出一条
+I的 Changelog,并写入 LSM 树的文件中。
5. 可见性保证与 Radical Compaction
在 Paimon 的 First-row 引擎中,有一个底层限制:Level 0 层的临时文件在未被 Compaction 合并到高层级之前,对 Lookup 查找是不可见的。
为了保障实时去重的正确性(防止同一个 Key 在极短时间内多次流入、尚未完成 Compaction 导致 Lookup 查不到),Paimon 针对 First-row 和 Lookup 启用了更激进的 Radical Compaction 策略,强制将 Level 0 文件立即与高层级进行合并,以此确保首次写入的数据能够立即可见,被后续到来的重复 Key 成功检索并拦截。
四、 方案对比总结
| 对比维度 | Flink SQL 状态去重 (Deduplicate) | Paimon First-row 合并引擎 |
|---|---|---|
| 状态存储位置 | Flink 算子本地 RocksDB 状态 | Paimon 存储层内部(LSM-tree + 本地 Lookup Cache) |
| Flink Checkpoint 大小 | 随活跃用户规模(Key)呈线性暴增 | 极小,Flink 作业几乎无状态 |
| 大规模点击 I/O 开销 | 极高(每次点击都要频繁读写 RocksDB State) | 极低(后续的重复点击在 LSM 写入端直接被检索拦截和静默丢弃) |
| 下流 Changelog 类型 | 通常产生回撤流(-U, +U),下游计算成本高 |
仅产生追加流(+I),对下游计算和存储极其友好 |
| 历史数据回放与冷启动 | 状态重建极难,效率很低 | 极为简单,数据湖存储天然支持回溯与批读写 |