 播面
播面 利用 Paimon 的 Aggregation(聚合)引擎构建实时汇总表。上游频繁产生同一个用户在不同时间点的消费额和登录次数,需要将其进行累加。请问 Aggregation 引擎支持哪些聚合函数?在面对非幂等操作(例如 SUM)时,一旦发生上游重试导致数据重复写入,应该如何设计来保证数据的绝对准确?
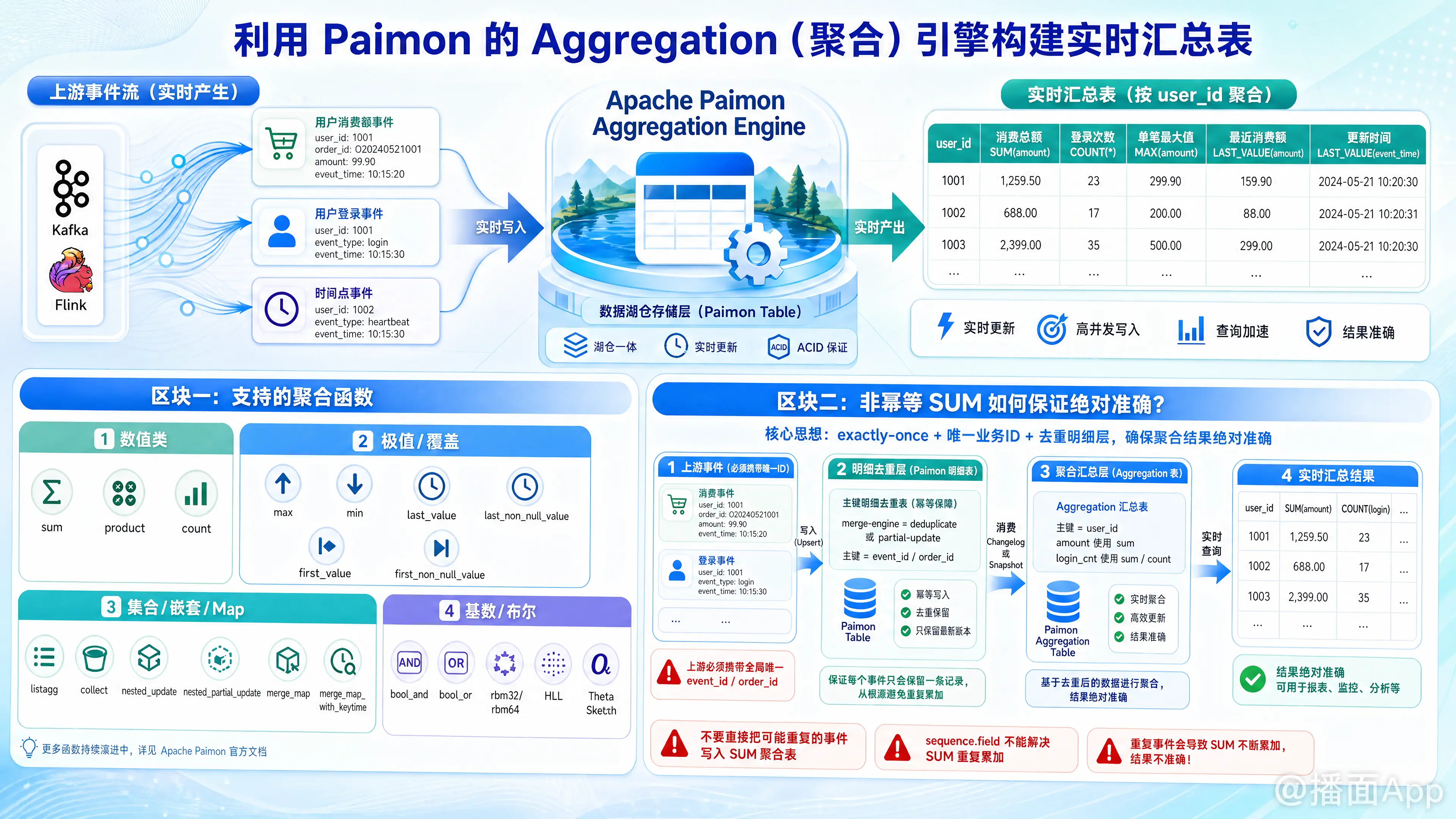
在实时数据湖建设中,使用 Apache Paimon 的 Aggregation(聚合) 引擎构建实时汇总表是一种非常高效的设计。它能够将本需在计算引擎(如 Flink)状态中进行的聚合计算下推至存储层,极端减轻 Flink 状态(State)的压力。
下面将详细梳理 Paimon Aggregation 引擎支持的聚合函数,并针对上游重试导致非幂等操作(如 SUM)数据重复的问题,给出端到端的架构设计方案。
一、 Aggregation 引擎支持的聚合函数
在 Paimon 中,当表定义为 'merge-engine' = 'aggregation' 时,除了主键之外的每个字段都可以通过指定 'fields.<field-name>.aggregate-function' 来决定其合并策略。当前 Paimon 支持的聚合函数主要包括以下几类:
数值累加/乘积类:
sum:累加数值。支持 DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT 和 DOUBLE 等。这是唯一原生支持数据回撤(Retract)和删除的聚合函数。product:计算乘积值。count:统计行数(也可通过sum(CASE WHEN ... THEN 1 ELSE 0 END)实现)。
极值与极值覆盖类:
max/min:保留最大/最小值。last_value/last_non_null_value:用最新导入的值(或最新的非空值)覆盖旧值。first_value/first_non_null_value:保留第一次导入的值(或第一次非空值)。
集合与拼接类:
listagg:将多个字符串拼接。支持通过'fields.<field-name>.list-agg-delimiter'指定分隔符(默认,),并支持'fields.<field-name>.distinct' = 'true'进行去重。collect:将元素收集为 ARRAY。支持通过设置 distinct 参数去重。nested_update/nested_partial_update:用于处理嵌套表(Row 类型的 Array)。可指定行级主键实现嵌套数据的部分更新与去重。merge_map/merge_map_with_keytime:合并 Map 类型的数据。with_keytime版本支持基于时间戳保留 Key 维度的最新 Value。
基数估算与布尔类:
bool_and/bool_or:对布尔值执行与/或操作。rbm32/rbm64:利用 Roaring Bitmap 进行精确的去重计数。- HLL (HyperLogLog) / Theta Sketch:基于 Apache DataSketches 实现的基数估算,用于大宽表下的模糊去重计数(Theta 支持集合交并差运算)。
二、 面对非幂等操作(如 SUM),如何保证数据绝对准确?
1. 为什么常规设计无法应对上游重试?
如果上游(例如 Kafka 生产者或源头业务系统)由于网络抖动发生重试,导致同一条消费明细数据被重复写入 Paimon 的 Aggregation 表:
SUM是非幂等的:每次写入都会执行累加操作,导致汇总值偏大。sequence.field无法防重:有用户尝试使用 Paimon 的sequence.field(如事件时间戳)来防止重复。然而在 Aggregation 引擎中,sequence-group仅作为“排序键”。对于像sum、max、min这样与顺序无关的函数,所有传入的非空记录无论版本新旧,都会参与聚合计算。因此,它无法过滤掉物理上重复写入的行。
2. 绝对准确的架构设计方案
要保障数据的绝对准确(Exactly-Once),必须在数据进入 Aggregation 引擎之前将其幂等化(去重)。以下是工业界常用的两种设计方案。
方案 A:双阶段 Paimon 表设计(明细去重表 + 聚合表)—— 推荐方案
这是最健壮、最契合数据湖特性的标准设计。我们将整个链路分为两步:
- DWD 阶段(明细表):使用 Paimon
deduplicate引擎,根据事件的“唯一标识”进行去重。 - DWS 阶段(聚合表):读取明细表的 Changelog(变更流),写入到
aggregation表进行累加。
[Kafka 数据源] ──(包含重试数据)──> [Flink 任务 1] ──> [Paimon 明细去重表 (DWD)]
│
(输出标准变更流: -U / +U)
│
▼
[Paimon 聚合汇总表 (DWS)] <── [Flink 任务 2] ───────────────────┘步骤一:创建明细去重表 (DWD)
定义一张以“用户ID + 消费流水号/事件ID”联合为主键的明细表,默认使用 deduplicate 合并引擎。
CREATE TABLE paimon_dwd.user_consume_detail (
user_id BIGINT,
event_id STRING, -- 业务全局唯一的事件或流水 ID
consume_amount DECIMAL(10, 2),
login_count INT,
event_time TIMESTAMP(3),
PRIMARY KEY (user_id, event_id) NOT ENFORCED
) WITH (
'merge-engine' = 'deduplicate', -- 相同 event_id 的重试数据在此阶段被合并
'changelog-producer' = 'lookup' -- 生成精确的 -U (旧值) 和 +U (新值) 变更流
);步骤二:创建聚合汇总表 (DWS)
定义一张以“用户ID”为主键的聚合表,对消费额和登录次数使用 sum 函数。
CREATE TABLE paimon_dws.user_aggregation (
user_id BIGINT,
total_consume_amount DECIMAL(18, 2),
total_login_count BIGINT,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'merge-engine' = 'aggregation',
'fields.total_consume_amount.aggregate-function' = 'sum',
'fields.total_login_count.aggregate-function' = 'sum'
);步骤三:串联逻辑(Flink 流式消费明细表写入聚合表)
-- Flink 配置:在 Aggregation 场景下务必关闭 upsert-materialize
SET 'table.exec.sink.upsert-materialize' = 'NONE';
INSERT INTO paimon_dws.user_aggregation
SELECT
user_id,
consume_amount,
login_count
FROM paimon_dwd.user_consume_detail;💡 为什么该方案能保证绝对准确?
- 数据完全重复时:如果上游重试发送了完全相同的
event_id数据,DWD 明细表的deduplicate引擎在合并后发现数据未发生任何实质变更,因此不会向下游发送新的 Changelog。DWS 聚合表自然不会重复累加。 - 数据部分更新时:如果重试时事件的数据有所修正,DWD 表会通过
lookup生成-U(回撤旧值)和+U(累加新值)两条消息。Paimon 聚合表的sum字段原生支持回撤,它会先扣减旧的consume_amount,再加回新的consume_amount,从而确保最终聚合结果完全正确。
方案 B:Flink 状态层去重(单表设计)
如果不想维护两张 Paimon 表,可以将去重逻辑放在 Flink 内存/状态(State)中完成,直接输出去重后的流写入 Paimon 聚合表。
步骤一:创建聚合汇总表
CREATE TABLE paimon_dws.user_aggregation_direct (
user_id BIGINT,
total_consume_amount DECIMAL(18, 2),
total_login_count BIGINT,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'merge-engine' = 'aggregation',
'fields.total_consume_amount.aggregate-function' = 'sum',
'fields.total_login_count.aggregate-function' = 'sum'
);步骤二:Flink SQL 利用 RowNumber 进行窗口/窗口外去重
SET 'table.exec.sink.upsert-materialize' = 'NONE';
INSERT INTO paimon_dws.user_aggregation_direct
SELECT
user_id,
consume_amount,
login_count
FROM (
SELECT
user_id,
consume_amount,
login_count,
ROW_NUMBER() OVER (PARTITION BY event_id ORDER BY event_time DESC) as rn
FROM kafka_source_table
)
WHERE rn = 1; -- 仅保留首次到达或最新到达的事件💡 该方案的优缺点:
- 优点:结构简单,只需要维护一张 Paimon 聚合表。
- 缺点:Flink 必须在内存/RocksDB 状态中维护所有
event_id以供去重,这需要设置合理的 State TTL(状态生存时间)。如果重试的数据在 TTL 清理之后才到达,依然会出现重复计算;若 TTL 设置过长,则会导致 Flink 状态爆炸。
三、 总结与最佳实践
- Flink 核心配置:在使用 Flink 写入 Paimon 聚合表时,务必在 TableConfig 中设置
'table.exec.sink.upsert-materialize' = 'NONE',否则 Flink 自动生成的物化算子可能会干扰 Paimon 的聚合行为,引发非预期的计算结果。 - 端到端 Exactly-Once:
- 确保 Flink 任务开启了 Checkpoint(Paimon 依赖 Checkpoint 提交 Snapshot 事务)。
- 选用 方案 A(双表设计),将数据去重下推至 Paimon 存储层,既规避了 Flink 状态膨胀的隐患,又通过 Paimon 的 Retract 机制完美解决了非幂等聚合重试的数据失真问题。