 播面
播面 在 Partial-Update 场景下,Stream A 和 Stream B 分别更新同一主键的不同列。由于网络抖动,Stream B 发送的旧版数据迟到了,反而覆盖了已落盘的最新版本数据。请问如何利用 Paimon 的“Sequence Group(序列组)”机制来防止乱序带来的旧值覆盖新值问题
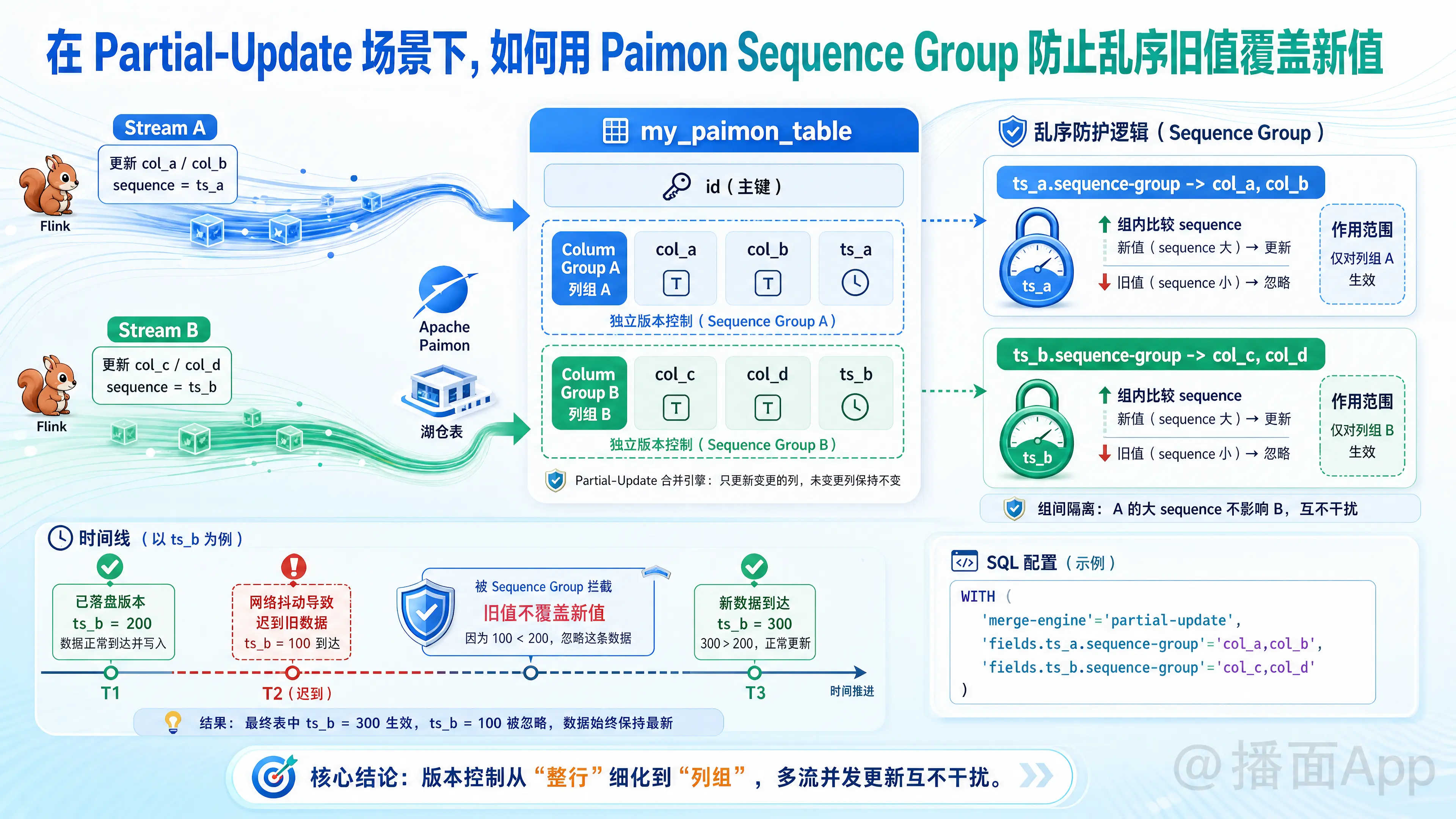
在 Apache Paimon 的 partial-update(部分更新)合并引擎中,当多个 Flink 流任务(如 Stream A 和 Stream B)并发更新同一张表的不同列时,乱序和旧值覆盖新值是一个非常经典且棘手的问题。
在默认情况下,仅靠一个全局的 sequence.field 是无法解决这个问题的。因为如果 Stream A 的进度较快,写入了非常大的全局 sequence 值,那么 Stream B 即使发送了其内部最新的数据,也会因为其 sequence 值小于 Stream A 写入的值而被 Paimon 丢弃;如果不设置 sequence,则无法防止 Stream B 自身内部因网络抖动产生的“旧数据迟到并覆盖新数据”的问题。
为了优雅地解决多流并发更新时的乱序问题,Paimon 引入了 Sequence Group(序列组) 机制。以下是该机制的详细工作原理、配置方法以及具体运行过程的解析。
一、 Sequence Group(序列组)的核心原理
Sequence Group 的核心思想是将“版本控制”的粒度从“整行”细化到“列组(Column Group)”。
你可以将表中的列划分为不同的组,并为每个组指定一个独立的 sequence 字段(通常是各流数据源中的时间戳或版本号)。
- 组内控制:每个列组只根据自己绑定的 sequence 字段来判断数据的新旧。如果新到数据中该组的 sequence 值大于已落盘的 sequence 值,则更新该组的列,并更新该组的 sequence;如果小于,则直接忽略该组的更新。
- 组间隔离:不同列组之间的 sequence 互不干扰。Stream A 的 sequence 值再大,也不会导致 Stream B 正常更新的数据被过滤。
二、 DDL 配置示例
假设我们有一张大宽表,主键为 id:
- Stream A 负责更新
col_a和col_b,其业务时间戳为ts_a。 - Stream B 负责更新
col_c和col_d,其业务时间戳为ts_b。
我们可以在建表时通过 WITH 参数这样配置:
CREATE TABLE my_paimon_table (
id INT,
-- Stream A 相关的列和其 sequence 字段
col_a STRING,
col_b STRING,
ts_a BIGINT,
-- Stream B 相关的列和其 sequence 字段
col_c STRING,
col_d STRING,
ts_b BIGINT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'merge-engine' = 'partial-update', -- 启用部分列更新引擎
'fields.ts_a.sequence-group' = 'col_a,col_b', -- ts_a 控制 col_a 和 col_b
'fields.ts_b.sequence-group' = 'col_c,col_d' -- ts_b 控制 col_c 和 col_d
);语法说明:
配置格式为'fields.<sequence_field_name>.sequence-group' = '<col1>,<col2>,...'。
绑定的 sequence 字段类型支持TINYINT,INT,BIGINT,TIMESTAMP,TIMESTAMP_LTZ等多种可比较类型。
三、 实战:乱序场景下的数据合并过程
让我们通过一个具体的场景,来看看 Sequence Group 是如何阻断旧数据覆盖新数据的。
1. 初始状态
当前磁盘上已经合并了 Stream A 和 Stream B 的最新数据:
id = 1- Stream A 最新数据:
col_a = 'A2',col_b = 'B2',ts_a = 100 - Stream B 最新数据:
col_c = 'C2',col_d = 'D2',ts_b = 200 - 落盘的数据行状态:
(id=1, col_a='A2', col_b='B2', ts_a=100, col_c='C2', col_d='D2', ts_b=200)
2. 乱序发生(Stream B 的旧数据迟到)
假设 Stream B 之前发送过一条生成于 ts_b = 150 的旧数据,因为网络抖动在此时才到达 Paimon。
- 迟到的数据行:
(id=1, col_a=null, col_b=null, ts_a=null, col_c='C1', col_d='D1', ts_b=150)
3. Paimon 的合并决策过程
当 Paimon 接收到这条迟到的记录并与磁盘上的已有记录进行 merge 时:
- 识别更新列:Paimon 发现传入的记录只包含
col_c、col_d和ts_b。 - 定位序列组:通过 DDL 配置,Paimon 知道
col_c和col_d的更新归属ts_b这个序列组管辖。 - 版本对比:
- 传入的 sequence 值
ts_b_incoming = 150。 - 磁盘已存的 sequence 值
ts_b_stored = 200。 - 比较:
150 < 200(传入版本旧于已存版本)。
- 传入的 sequence 值
- 执行决策:Paimon 拒绝用传入的
'C1'和'D1'覆盖原有的'C2'和'D2',同时保持ts_b为200。对于未传入的 Stream A 相关的列(col_a,col_b,ts_a),由于它们不由ts_b管辖,因此完全不参与此次比对。 - 合并后最终结果:
(id=1, col_a='A2', col_b='B2', ts_a=100, col_c='C2', col_d='D2', ts_b=200)(旧值成功被阻断,新值得以保留)。
四、 更多进阶特性
除了解决基础的乱序问题外,Paimon 围绕 Sequence Group 还提供了以下特性来应对复杂的生产环境:
- 支持多字段联合排序(Multiple sorted fields):
如果你无法用单个字段(如时间戳)完全决定先后顺序,你可以在一个序列组中配置多个排序字段。例如:'fields.ts_b,sub_seq_b.sequence-group' = 'col_c,col_d'
Paimon 会依次对比ts_b和sub_seq_b来判定版本新旧。 - 局部回撤/物理删除(Retract & Delete):
- 在双流 Join 的替代场景中,如果 Stream B 发生了数据撤回(Delete 消息),你可以利用序列组来实现局部回撤(即只把
col_c和col_d置空,而不影响 Stream A 写入的col_a和col_b)。 - 如果你希望在特定序列组收到删除信号时,直接删除整行,可以配置:
'partial-update.remove-record-on-sequence-group' = 'ts_b'。
- 在双流 Join 的替代场景中,如果 Stream B 发生了数据撤回(Delete 消息),你可以利用序列组来实现局部回撤(即只把
- 结合聚合函数(Aggregation):
自 Paimon 0.6 版本起,在带有序列组的partial-update表中,你还可以为特定列配置聚合函数(如sum,max,listagg等)。- 不带聚合函数时:序列组字段作为“版本过滤器”(旧数据直接被丢弃)。
- 带聚合函数时:序列组字段作为“排序键”。即使迟到的数据版本较低,它也会参与聚合计算,但 Paimon 会根据 sequence 字段的值来精准决定谁是最后/最先的值(例如在
last_non_null_value函数中)。