 播面
播面 Paimon 表实时接收 CDC 数据,下游另一个流式作业需要消费其增量变更做秒级指标聚合。默认的 none Changelog 模式无法提供旧值 -U,导致聚合结果错误。面临 lookup 和 full-compaction 两种 Changelog 产生器模式,你应该如何根据时延要求、内存限制以及 Merge Engine 的类型进行选型
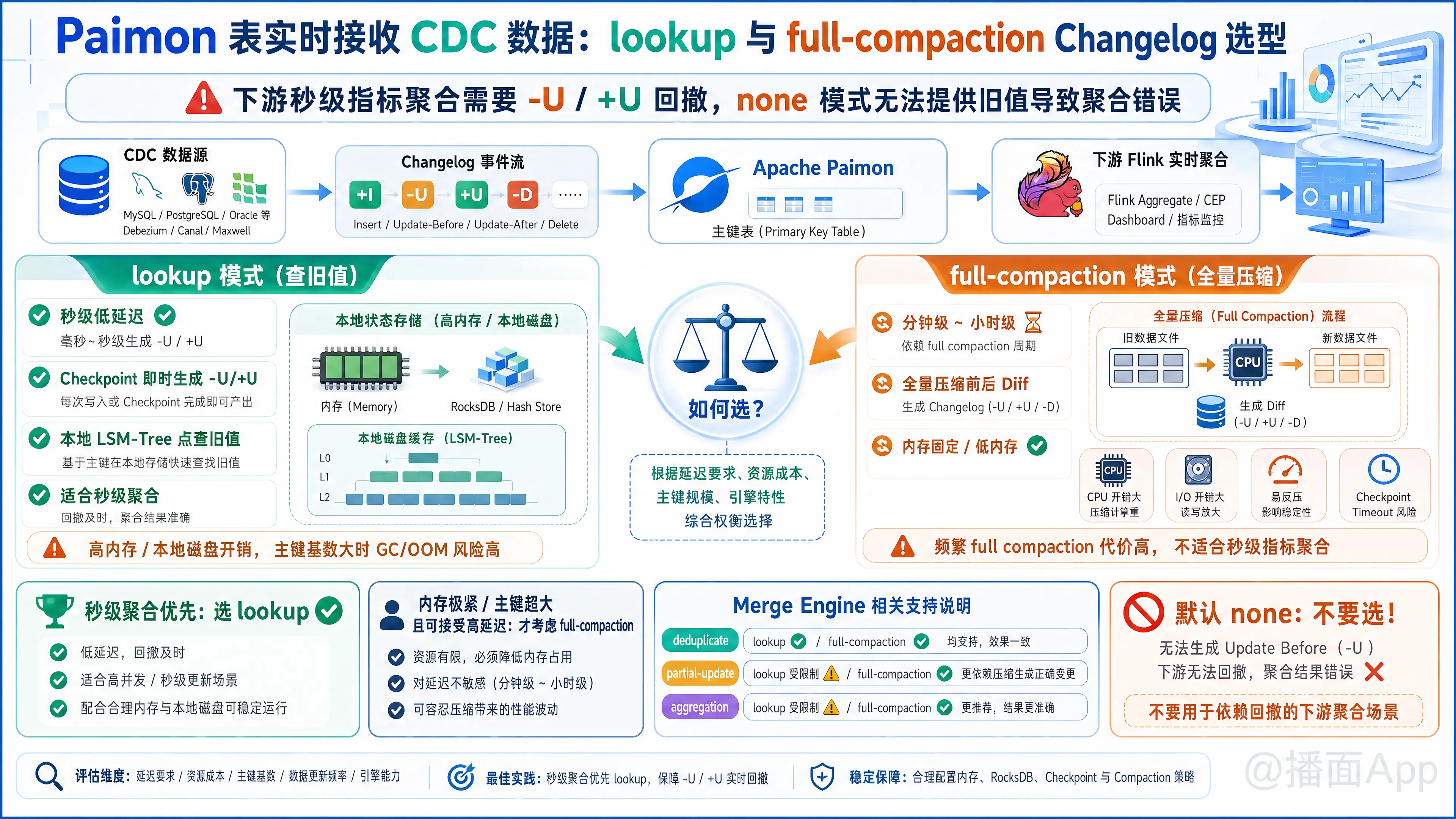
在 Apache Paimon 中,流式写入主键表并由下游进行实时消费时,Changelog 的生成机制是保障下游 Flink 等流式作业进行增量聚合(如 SUM, COUNT, AVG)结果正确性的核心。
下游流式聚合算子(如 Flink 的 Aggregate)需要依靠回撤机制(Retraction)工作,即在收到新值 +U(Update After)的同时,必须先收到旧值 -U(Update Before),以此完成“减去旧值,加上新值”的更新。默认的 none 模式不存储额外的数据变更日志,当下游流读时,Paimon 只能看到 Snapshot 级别的合并后结果,无法生成旧值 -U,从而导致下游聚合由于缺乏回撤而出现计算错误(如数值持续累加、结果偏大)。
面对下游的“秒级指标聚合”需求,在 lookup 和 full-compaction 两个 Changelog 产生器模式中进行选型,需从时延、内存限制、Merge Engine 三个维度进行深度权衡。
一、 核心维度对比:Lookup vs. Full-Compaction
1. 时延要求 (Latency)
lookup模式(秒级时延,完美匹配秒级聚合):- 机制:在数据提交写入前,通过在本地的 LSM-Tree 中进行点查(Lookup)来获取该主键对应的历史旧值,从而在 Checkpoint 提交时即时生成正确的
-U和+U变更数据。 - 时延:与 Checkpoint 周期(通常为秒级或数十秒级)完美对齐,满足秒级指标聚合的要求。
- 机制:在数据提交写入前,通过在本地的 LSM-Tree 中进行点查(Lookup)来获取该主键对应的历史旧值,从而在 Checkpoint 提交时即时生成正确的
full-compaction模式(分钟级至小时级,无法支撑秒级聚合):- 机制:通过对比全量压缩(Full Compaction)前后的差异来生成 Changelog。
- 时延:虽然可以通过设置
full-compaction.delta-commits = 1使得每次 Checkpoint 都触发一次 Full Compaction 以降低延迟,但在生产环境下,频繁触发 Full Compaction 会带来极高昂的 CPU 与 I/O 开销,导致严重反压,甚至使 Flink 作业由于 Checkpoint 超时而崩溃。 - 结论:在下游为“秒级指标聚合”的场景下,
full-compaction模式在性能上是无法落地的。
2. 内存限制 (Memory Limits)
lookup模式(高内存/本地磁盘开销):- 瓶颈:由于需要点查历史主键,Paimon 需要在 TaskManager 内存或本地磁盘中维护一个 KV 索引缓存(使用 Hash Store 或 RocksDB 缓存)。
- 影响:当表的主键基数(Unique Keys)极其庞大(例如数十亿级)且 TaskManager 堆内存有限时,过多的本地 Cache 会带来严重的 GC 压力或 OOM 风险。如果频繁发生 Cache 淘汰,还会引入大量的本地磁盘 I/O,拖慢写入效率。
full-compaction模式(低内存且内存大小固定):- 瓶颈:无需在内存中维护点查索引。它的 Compaction 是顺序读写、按需归并的过程,内存开销是受限且可预期的。
3. Merge Engine 类型的兼容性
Paimon 提供了 deduplicate(默认)、partial-update(部分更新)和 aggregation(预聚合)等合并引擎。
- Deduplicate(去重):
- 两种模式都支持。
lookup可以即时生成-U/+U。
- 两种模式都支持。
- Partial Update(部分更新)与 Aggregation(预聚合):
- 特殊性:当使用这两种引擎时,若将
changelog-producer设为input,下游流读只能拿到原始输入的局部列或局部变更,无法拿到 Paimon 内部合并/聚合后的宽表全量状态。 - 流读硬性要求:为了让下游看到拼接或聚合完备后的最新行以及对应的撤回消息,必须使用
lookup或full-compaction产生器。 - 秒级场景下的选择:同样,为了实现秒级输出,依然推荐且只能使用
lookup。
- 特殊性:当使用这两种引擎时,若将
二、 选型决策框架
针对你的业务场景:下游需要消费增量变更做秒级指标聚合,选型逻辑应遵循如下路径:
[下游秒级指标聚合]
│
是否存在极低时延(秒级)要求?
├─ YES ──> 只能选择 [lookup] 模式
└─ NO ──> (如果是分钟级/小时级时延)
│
是否存在海量主键导致内存/磁盘I/O吃紧?
├─ YES ──> 选择 [full-compaction]
└─ NO ──> 优先选择 [lookup]终极结论:你应当选择 lookup 模式。
因为 full-compaction 在分钟或小时级别延迟下工作良好,但只要下游有“秒级”硬性要求,任何生产环境都无法承受每几秒一次的 Full Compaction 物理开销。
三、 落地 lookup 模式的调优与避坑指南
由于 lookup 模式是唯一可行的方案,但它会带来写入性能衰退、内存压力、Checkpoint 变慢等副作用,因此在上线前必须进行以下调优:
1. 解决内存限制(防止 OOM)
- 限制本地缓存大小:通过以下配置限制 Lookup 缓存占用的最大内存和最大磁盘空间,超出部分将换出到磁盘中(建议本地使用 NVMe SSD 存储):sql
'lookup.cache-max-memory-size' = '256 mb' -- 视TM大小而定,不宜过大 'lookup.cache-max-disk-size' = '10 gb' -- 限制本地缓存占用磁盘,防止打爆磁盘 - 提高 Sink 并行度:利用 SQL Hint 或配置
sink.parallelism。提高并行度可以将主键 Hash 分散到多个并发 Subtask 中,从而稀释单个 TaskManager 的本地主键缓存规模。
2. 优化时延与写入性能(防止 Checkpoint 堵塞)
lookup 默认会在 Checkpoint 触发时强行进行 Level 0 文件的 Compaction 以完成查找,容易导致 Checkpoint 耗时增加甚至超时。
- 开启完全异步 Compaction:允许 Checkpoint 无需同步等待 Lookup 变更日志完全产生,将小文件合并完全异步化,极大地提升 CPU 效率和写吞吐:sql
'num-sorted-run.stop-trigger' = '2147483647', 'sort-spill-threshold' = '10', 'changelog-producer.lookup-wait' = 'false' - 规避重复无用 Changelog:若 CDC 进来的数据包含许多字段没有实际变化的重复记录,可开启行去重,防止向下游发送无谓的
-U/+U增加算子反压:sql'changelog-producer.row-deduplicate' = 'true'
3. 针对特定的 Merge Engine 配置
- 如果你的 Merge Engine 是
partial-update,并且接收-D(Delete)消息,请根据业务决定是否配置'partial-update.ignore-delete' = 'true'或基于 sequence-group 做撤回。 - 如果你的 Merge Engine 是
aggregation,请确保下游聚合列使用的函数支持 retraction(如sum,last_value支持;而max/min对回撤支持受限,可能需要借助额外的状态或忽略回撤配置'fields.${field_name}.ignore-retract'='true')。