 播面
播面 上游 MySQL 库中的上百张表通过 Flink CDC 一键整库同步(CDAS/CTAS)到 Paimon。在生产中,上游频繁对表执行 DROP COLUMN、RENAME COLUMN 和 ADD COLUMN 等 DDL 操作。请问 Paimon 的 Schema 演进机制是如何保障底层历史文件不损坏且跨计算引擎(Flink/Spark)查询兼容的?
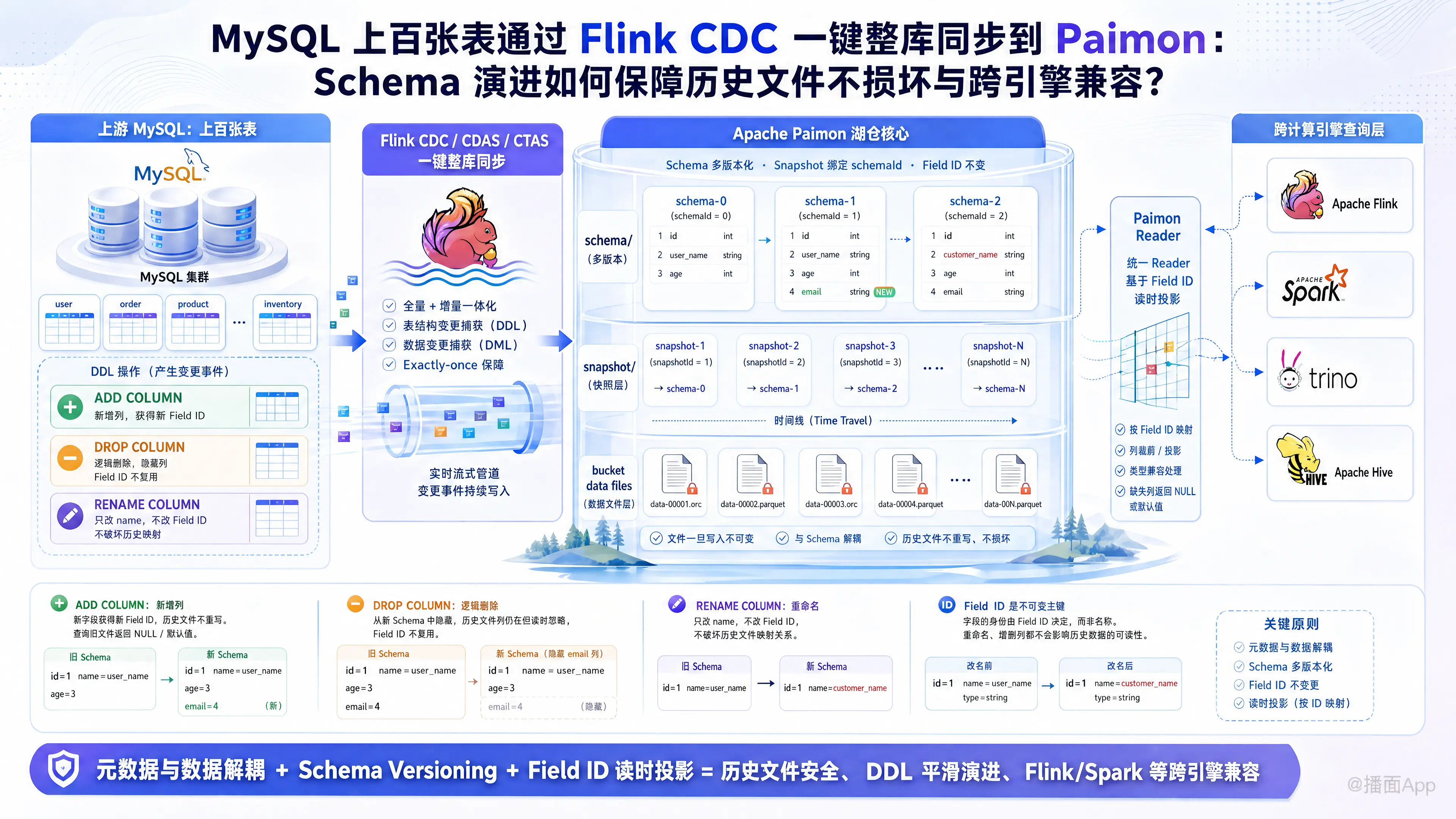
在生产环境中,使用 Flink CDC 的一键整库同步(CDAS/CTAS)将上游 MySQL 的上百张表实时同步到 Apache Paimon 是一种常见且高效的架构设计。在这种场景下,上游频繁的 DDL 操作(如 ADD COLUMN、DROP COLUMN、RENAME COLUMN)会对下游数仓的稳定性带来很大挑战。
Apache Paimon 能够保证底层历史数据文件不损坏,且支持跨计算引擎(Flink、Spark、Trino、Hive 等)进行兼容查询,这主要归功于其元数据与数据解耦的架构设计以及基于 Field ID 的读时投影机制。以下从底层原理和架构层面为您详细拆解其保障机制。
一、 Paimon Schema 演进的核心数据模型
要理解 Paimon 的 Schema 演变,首先需要了解其底层文件布局和元数据组织方式。Paimon 在文件系统(如 HDFS、S3)上的目录结构通常如下:
my_table/
├── schema/
│ ├── schema-0 (包含字段、主键、配置信息)
│ ├── schema-1 (表结构变更后生成的新版本)
│ └── schema-2
├── snapshot/
│ ├── snapshot-1 (指向 schema-0)
│ ├── snapshot-2 (指向 schema-1)
│ └── LATEST
└── bucket-0/
├── data-xxx.orc (底层实际列式数据文件)
└── data-yyy.orc1. 模式多版本化(Schema Versioning)
Paimon 不会直接修改原有的 Schema 文件,而是采用追加写、多版本共存的方式。每次发生 DDL 变更,Paimon 都会在 schema 目录下生成一个新的 schema-${version} JSON 文件(如 schema-1)。旧的 Schema 文件会被完整保留,因为历史数据文件仍然依赖它们来进行解析。
2. 逻辑字段 ID(Field ID)的唯一标识
这是 Schema 演进不损坏文件的最核心基石。在 Paimon 的 schema JSON 文件中,每个字段(Field)都包含三个核心属性:id(Field ID)、name(字段名)和 type(字段类型)。
- Field ID 是一个自增且不可变的整数(从 0 开始)。
- 无论字段名称如何修改、物理位置如何移动,只要它代表的是同一个物理含义的列,它的 Field ID 就永远保持不变。
- 即使某个字段被删除了,该 Field ID 也会被废弃,绝不会分配给后续新加的列。
3. 快照与模式的绑定(Snapshot to Schema Binding)
Paimon 所有的写入提交都会生成一个 Snapshot(快照)文件(如 snapshot-1)。每个快照文件中都记录了 schemaId 属性,明确指定了该版本数据所对应的 Schema 版本。
二、 三大经典 DDL 的底层应对策略与防损坏机制
在 Flink CDC 捕获到上游 DDL 并通过 Paimon Catalog 写入新 Schema 时,Paimon 处理 ADD、DROP、RENAME 的逻辑如下:
1. ADD COLUMN(增加新列)
- 元数据操作:Paimon 会读取当前最新 Schema(假设最高 Field ID 为 ),为新列分配一个新的 Field ID(),并将
highestFieldId递增,生成新版本的 Schema 文件。 - 数据文件处理:历史数据文件(在其对应的旧 Schema 中不包含 这个 ID)完全不需要重写。
- 查询保障:当计算引擎查询新列时,Paimon 的 Reader 发现历史文件里没有 ID 对应的列,会自动为该列填充
NULL(或指定的默认值),从而避免了读取历史文件时发生错位或报错。
2. DROP COLUMN(删除列)
- 元数据操作:生成新版本的 Schema JSON,将要删除的列从
fields列表中移除,但该列占用的 Field ID 被永久废弃,不会再复用。 - 数据文件处理:历史物理数据文件中依然保留着被删除列的数据,Paimon 不会发起高 I/O 损耗的物理擦除。
- 查询保障:计算引擎读取最新 Schema 时,解析出的投影列中不包含该 Field ID。因此,Paimon Reader 在读取底层历史文件时会主动跳过对应的列数据,实现了逻辑上的“秒级删除”。
3. RENAME COLUMN(重命名列)
- 元数据操作:在新的 Schema JSON 中,将对应 Field ID 的
name属性更新为新名称,而其id(Field ID)和type保持原样。 - 数据文件处理:历史物理数据文件完全保持不变(即便文件内部,如 Parquet/ORC 的元数据中,依然记录着旧列名)。
- 查询保障:由于 Paimon 的 Reader 在读取物理文件时是通过 Field ID 进行底层数据寻址和映射的,而不是依赖文件内部的列名字符串。因而重命名后,Reader 依然能精准对应到正确的物理列。
三、 跨计算引擎(Flink/Spark/Trino)查询兼容的保障机制
在生产中,通常是 Flink CDC 在实时写入并更新 Schema,而 Spark、Trino、Hive 等引擎在做离线或即席查询。Paimon 能够保障跨引擎兼容的关键在于其统一的 Reader 接口与“读时投影”机制。
1. 读时模式投影(Read-time Schema Projection)
当 Spark 或 Flink 提交一个 SELECT 查询时,执行流程如下:
- 加载元数据:计算引擎首先通过 Paimon 的统一 Catalog 读取表当前最新的 Schema(例如
schema-2),并构建好查询计划。 - 分析快照与文件模式:执行物理 Scan 时,计算引擎会获取到需要读取的数据文件列表。对于每个数据文件,Paimon 引擎会根据该文件写入时绑定的
schemaId(从快照中获取),找到其对应的原始 Schema(例如schema-0)。 - Field ID 动态投影:
- Paimon 内置的 Reader 会在内存中对 查询 schema (最新) 与 数据文件 schema (历史) 进行一次双向的比对与映射。
- 映射的标准是 Field ID。
- 建立映射关系后,底层列式读取器(Parquet/ORC Reader)会根据匹配到的 Field ID 提取物理列。如果某个 Field ID 仅在最新的 Schema 中存在,则在内存中直接生成
NULL向量;如果在物理文件中存在但最新 Schema 中已删除,则直接在 I/O 读取时过滤忽略。
2. 兼容主流列式文件格式(Parquet / ORC)
Paimon 默认使用 Parquet 或 ORC 作为底层存储格式。
- 这两种格式本身就支持列式存储和部分 Schema 演进。
- Paimon 会在向 Parquet/ORC 写入数据时,将 Paimon Field ID 写入到文件的 Metadata/Schema 中(例如,在 Parquet 的 Schema 元素中附带 Field ID 元数据,或在 ORC 的 Type 属性中记录)。
- 当 Spark/Trino 引擎通过 Paimon 提供的 Connector 读取这些文件时,Paimon 接口会直接解析这些嵌入在文件中的 Field ID,这使得即使底层文件格式对 DDL 的原生支持有差异,也能在 Paimon 抽象层被抹平。
3. 统一的 Catalog 与多引擎 Connector
Paimon 针对不同的引擎提供了专用的 Connector(如 paimon-spark-connector、paimon-flink-connector)。
- 这些 Connector 都会调用统一的
paimon-core读写核心包,使得无论是哪种计算引擎,在执行 Table Scan 时的“模式投影(Schema Projection)”算法和 Field ID 匹配规则都是完全一致的。 - 只要 Catalog(如 Hive Metastore 或其文件系统 Catalog)中的 Schema 版本 JSON 能够被正确同步和共享,所有引擎看到的都是一致且符合 DDL 演进预期的逻辑视图。
四、 生产实践中的边界与限制
尽管 Paimon 的 Schema 演变机制非常灵活,但在高频 DDL 的生产实践中,仍有几点技术局限和需要注意的事项:
- 类型拓宽(Type Promotion)的物理限制:Paimon 支持数据类型的升格(如
INT拓宽为BIGINT,或者VARCHAR长度变长)。但是,如果是不兼容的物理类型转换(如将VARCHAR强转为INT,或将DOUBLE改为MAP),在读取历史文件时可能会因为无法在内存中转换(Cast 失败)而报错。此类强转在 upstream DDL 变更时应当格外注意。 - 部分外部 Catalog(如 Hive Metastore)的不兼容性限制:
- 如果使用了 Paimon Hive Catalog,由于 Hive Metastore 自身可能会校验字段类型的兼容性,如果在 Hive 端开启了严格的 DDL 校验,可能会导致
DROP COLUMN等 DDL 写入元数据失败。 - 此时通常需要在 Hive Server 中关闭相关的不兼容变更限制(设置
hive.metastore.disallow.incompatible.col.type.changes=false)。
- 如果使用了 Paimon Hive Catalog,由于 Hive Metastore 自身可能会校验字段类型的兼容性,如果在 Hive 端开启了严格的 DDL 校验,可能会导致
- 一键同步时的 DDL 转换边界:在使用 Flink CDC 一键整库同步时,目前主要推荐使用专门的 Paimon CDC Action(如
mysql-sync-database)。只有通过这种 CDC 链路,上游 MySQL 的 DDL 变更才会作为 Stream DDL 事件在 Paimon Catalog 中被实时触发并应用到 Schema JSON 中。若直接在 Flink SQL 中书写普通的INSERT INTO paimon_table SELECT * FROM mysql_table,则通常无法直接享受自动 DDL 的热更新能力。