 播面
播面 讲讲Paimon 的Consumer Watermark传递机制?
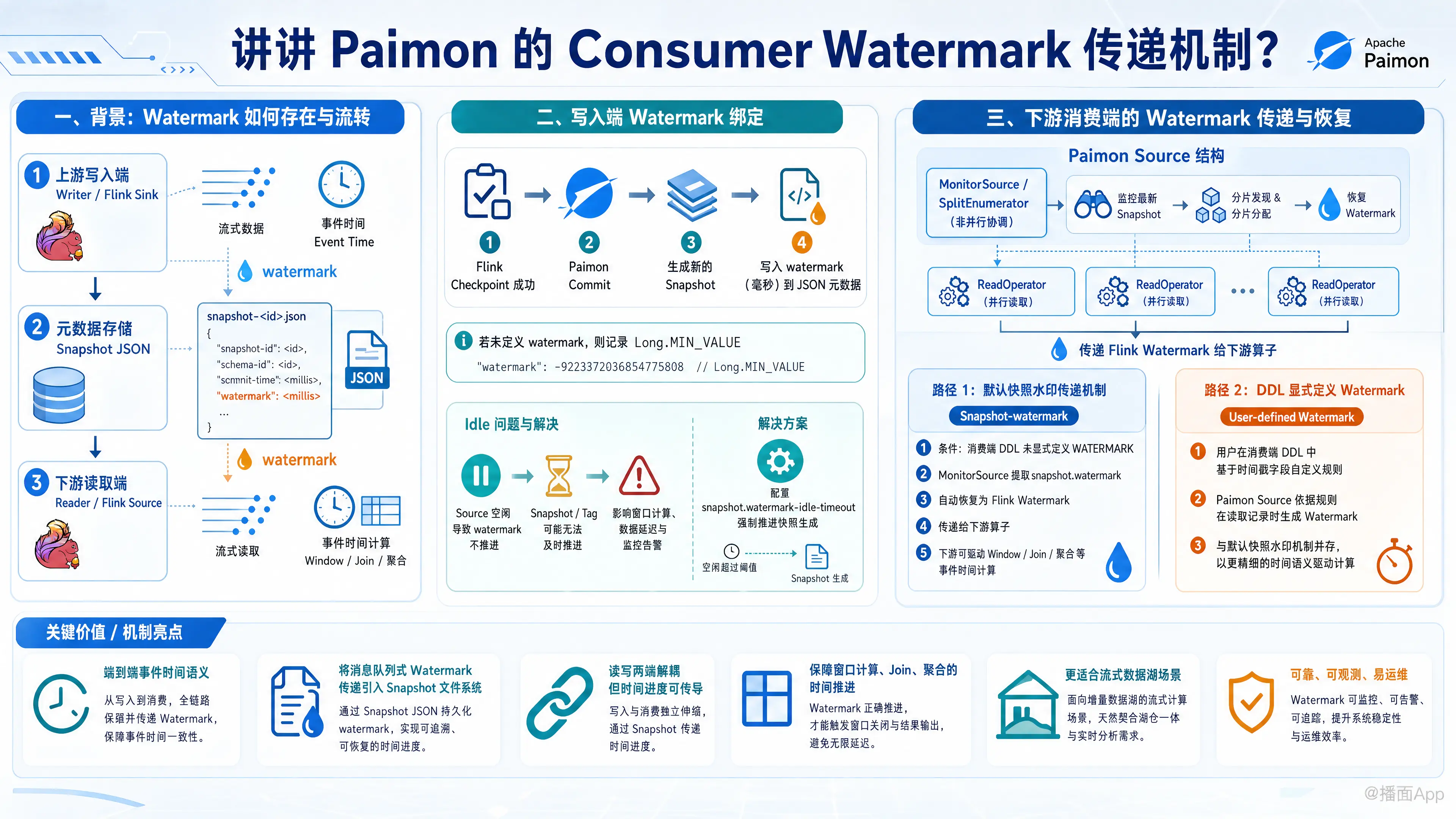
在 Apache Paimon 中,Consumer Watermark 传递与对齐机制是流式数据湖实现“端到端事件时间(Event Time)处理”的核心设计之一。在 Paimon 官方 Master 分支的文档及设计中,这一机制将传统消息队列(如 Kafka)的水印传递概念无缝引入到基于存储和快照(Snapshot)的文件系统上。
以下是 Paimon 的 Consumer Watermark 传递、对齐以及应用机制的详细拆解:
一、 背景:Paimon 中的 Watermark 是如何存在与流转的?
在 Paimon 架构中,Watermark 的生命周期主要分为三个阶段:
- 上游写入端(Writer):Flink Sink 在将数据提交(Commit)并生成 Snapshot 时,会将 Flink 引擎当时的 Watermark 值 记录到对应的快照元数据(JSON 文件,即
snapshot-<id>的watermark字段)中。 - 元数据存储:元数据中记录的
watermark代表“该快照中包含的数据,其事件时间进度已推进到了该时间戳”。 - 下游读取端(Reader):下游 Flink Source 流式读取 Paimon 时,会提取 Snapshot 中的 Watermark,并将其恢复为流中的 Watermark 信号向下游算子传递。
二、 核心机制之一:写入端的 Watermark 绑定
当使用 Flink 等引擎向 Paimon 写入数据时,Paimon 通过以下方式处理 Watermark:
- Snapshot 绑定:
每次 Flink Checkpoint 成功触发 Paimon 提交一个新的 Snapshot 时,Paimon 都会在 Snapshot 的 JSON 描述文件中记录下该 Checkpoint 对应时刻的全局 Watermark(单位:毫秒)。若上游未定义/未产生 Watermark,则该字段会默认记录为Long.MIN_VALUE。 - 解决数据源空闲(Idle)问题:
在流处理中,如果上游源表突然没有数据流入(处于 Idle 状态),可能导致 Watermark 无法推进,进而在 Paimon 侧无法顺利触发 Snapshot 提交或自动创建 Tag。- 解决方案:Paimon 提供了
snapshot.watermark-idle-timeout配置。如果 Flink Source 的某个 Subtask 空闲时间超过该指定时间,即使没有新数据,也会强制推进快照生成以传导 Watermark。
- 解决方案:Paimon 提供了
三、 核心机制之二:下游消费端的 Watermark 传递与恢复
当下游流式消费 Paimon 表时,Paimon 会通过其非并行的协调器/监控任务(MonitorSource / SplitEnumerator)监视最新的 Snapshot,并将分片分配给并行的 ReadOperator 任务进行读取。在这个过程中,Watermark 的恢复和传递有两种主要路径:
1. 默认快照水印传递机制(Snapshot-watermark)
如果下游消费者在读取 Paimon 表的 DDL 中没有显式定义 WATERMARK 规则,Paimon 默认会开启 Snapshot-watermark 传递机制。
- 工作方式:当
MonitorSource监控并读取 Snapshot 时,它会自动提取该快照中的watermark属性值。 - 作用:随着读取进度的推进,Paimon Source 会自动将这个快照的水印作为 Flink 的 Watermark 自动传递给下游系统。这使得下游算子(如 Window 聚合、开窗 Join 等)可以直接基于这个传递过来的 Watermark 来推进计算进度。
2. DDL 显式定义的 Watermark
用户也可以在消费端 DDL 中显式定义 Watermark 生成规则(例如基于某个时间戳字段进行延迟减免):
CREATE TABLE my_consumer_table (
user_id BIGINT,
behavior STRING,
event_time TIMESTAMP(3),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (...);此时下游任务不会直接使用 Snapshot 中的元数据水印,而是会由 Flink Source Reader 任务提取数据中该字段的值,并动态动态计算产生新的 Watermark。
四、 核心机制之三:消费者模式(Consumer Mode)与水印对齐
流式读取 Paimon 时,往往需要配置 consumer-id(相当于 Kafka 的 group.id)来记录消费进度、保护 Snapshot 不被过期删除。
而在多并行度消费、多 Split 分发时,各并行的 Reader 消费速度可能产生倾斜,导致部分并行的 Watermark 增长过快,导致下游积压大量未关闭的窗口状态(State)。对此,Paimon 支持以下对齐控制:
1. 消费者一致性模式的影响(consumer.mode)
consumer.mode 的设置极大地影响了消费端的水印传递与对齐行为:
exactly-once(默认):
Reader 必须在严格的 Snapshot 边界处对齐,在 Checkpoint 期间强行要求所有 Reader 必须刚好消费完某一完整的 Snapshot。该模式无法提供高自由度的 Watermark 对齐。at-least-once:
允许各并行的 Reader 以不同的速率自由消费 Snapshot,只记录最慢的那一个 Reader 的进度(即最慢的snapshot-id)到文件系统上。
只有启用at-least-once模式时,才能全面解锁 Flink 的 Watermark 自动对齐功能。
2. 启用 Flink Watermark 对齐(Watermark Alignment)
当使用了 consumer.mode = at-least-once 时,可以配置 Flink 的水印对齐规则:
Paimon 提供了以下控制参数,可防止消费速度过快的 Source Subtask 把其 Watermark 推得太靠前,从而强制在 Source 层面进行消费限速:
| 参数名称 | 默认值 | 类型 | 描述说明 |
|---|---|---|---|
scan.watermark.alignment.group |
(none) |
String | 参与水印对齐的 Source 组名称。 |
scan.watermark.alignment.max-drift |
(none) |
Duration | 允许不同 Source/Partition/Task 之间水印最大偏差。一旦某 Reader 水印超前了该值,便会暂停其消费,直到慢的 Reader 赶上。 |
scan.watermark.alignment.update-interval |
1 s |
Duration | Task 节点向 Coordinator(协调器)通报自身当前 Watermark 以及协调器全局下发对齐水印值的频率。 |
scan.watermark.emit.strategy |
on-event |
Enum | 水印向下游发送的策略: - on-periodic:周期性发射(配合 Flink 间隔设置);- on-event:每读到一条数据即计算更新水印。 |
五、 基于 Watermark 传递机制的重要应用场景
1. 有界流读取结束控制(Bounded Stream)
即使在 Streaming 模式下消费,你也可以将流式读取“有界化”。
通过指定表属性 'scan.bounded.watermark' = '<Long-timestamp>',下游流式消费任务在不断往后拉取 Snapshot 时,一旦遇到快照内记录的 watermark 大于你设定值的 Snapshot,该流式读取作业便会自动停止消费并安全退出。
2. 基于事件时间自动创建 Tag(Tag Auto-creation by Watermark)
为了长期归档和保留历史快照,Paimon 支持在写入时自动生成 Tag。其中 'tag.automatic-creation' = 'watermark' 是最常用的生成策略之一:
- 其机制:
Paimon 的 Writer 监视上游传递过来的 Watermark。一旦 Watermark 时间越过了你设定的周期(例如daily的 00:00)加上所设置的延迟(tag.creation-delay),Paimon 就会选取第一个水印超出该周期边界的快照自动创建一个 Tag。这保证了即使作业存在晚到或延迟数据,也能在水印真正越过边界后才生成对应的历史归档。