 播面
播面 如果 Bucket 数量设置过小或过大,分别会对读写性能和状态产生什么不利影响?
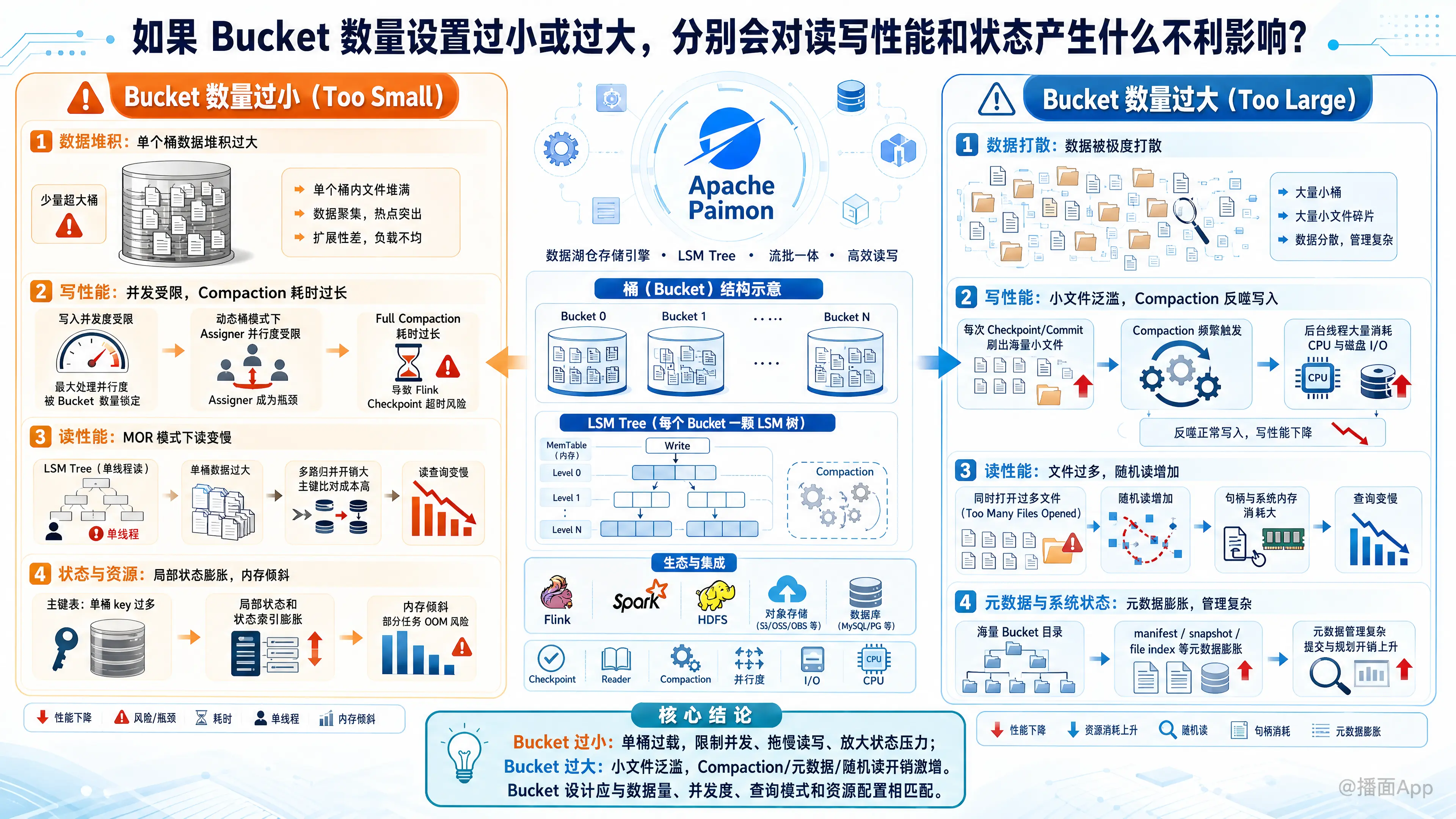
在 Apache Paimon 中,Bucket(桶) 是数据读写、LSM 树存储以及并行度的最小物理组织单元。基于 Apache Paimon(master 分支)的官方文档,如果 Bucket 数量设置得过小或过大,都会从多个维度对读写性能、系统状态、元数据以及资源消耗产生不利影响。
以下是具体的对比与深入分析:
一、 Bucket 数量设置过小(Too Small)的不利影响
当 Bucket 数量相对于实际数据量或写入规模设置得过小时,直接后果是单个桶内积压的数据量过于庞大(超量)。这会对系统产生以下不利影响:
1. 对写性能的影响
- 写入并发度受限,导致写吞吐不足: Bucket 是 Paimon 进行并发读写的基本存储单元。每一个 Bucket 内部都包含独立的 LSM 树。因此,Bucket 的数量直接锁定了写入任务(如 Flink/Spark Sink)能实现的最大处理并行度(maximum processing parallelism)。桶数设置过少,即使分布式集群资源充沛,也无法通过增加并发来提升整体写入吞吐。
- 动态桶模式下的 Assigner 算子瓶颈: 在动态桶(Dynamic Bucket)模式下,如果是初始化桶数(
dynamic-bucket.initial-buckets)设置过小,会限制 Assigner 算子的并行度,导致在高流量写入初期该算子处理速度跟不上,从而成为整条链路的写入瓶颈。 - Compaction 导致的 Checkpoint 超时风险: 当单桶数据过多时,LSM 树中的文件体积庞大。在触发 Full Compaction 时,后台合并任务需要消耗大量的 CPU 和磁盘 I/O 运行极长时间。如果写入任务资源不足,这非常容易导致 Flink Checkpoint 频繁超时(Flink 默认超时通常为 10 分钟)。
2. 对读性能的影响
- MOR(Merge On Read)模式下读性能急剧劣化: 在主键表默认的 MOR 模式中,每次读取都必须将该桶内所有的 Sorted Runs 文件在内存中进行多路归并(包含主键的比对计算)。由于单个 LSM 树(即单个 Bucket)只能通过单线程进行读取,当 Bucket 设置过少、单桶数据量严重超标时,读取线程需要处理巨大的 I/O 和计算量,导致读查询性能极其低下。
3. 对状态与系统资源的消耗
- 如果是主键表,单桶内巨大的 key 分布在进行数据更新和去重(Upsert/Deduplicate)时,会导致单个 Task 在内存中维护大范围的局部状态和状态索引,容易造成局部的内存倾斜。
二、 Bucket 数量设置过大(Too Large)的不利影响
当 Bucket 数量设置得过大时,数据会被极度稀疏地打散在各个 Bucket 目录中,直接后果是物理上产生海量的小文件。这会对系统产生以下不利影响:
1. 对写性能的影响
- 产生海量小文件,导致 Compaction 压力过载: Paimon 在进行流式写入(如 Flink Checkpoint 刷新)时,每次 Commit 都会对有数据写入的 Bucket 溢写(Flush)出新文件。当桶数极多时,单个桶分配的数据量很小,这会在每次 Checkpoint 结束后在 HDFS/对象存储上刷出成百上千个微小的碎片文件。
- Compaction 消耗大量 CPU 和 I/O,反噬正常写入: 为了维持 LSM 树合理的 Sorted Run 数量,系统必须频繁对这些海量小文件进行 Compaction 压缩与合并。这会导致后台的 Compaction 线程长时间抢占集群的 CPU 算力和存储写 I/O,严重拖慢正常的实时数据写入速度。
2. 对读性能的影响
- 同时打开文件过多(Too Many Files Opened)与随机读瓶颈: 由于桶数过多产生的大量小文件,在执行查询(Read)时,Reader 需要同时打开巨量的数据文件。这不仅会消耗客户端的系统级内存与文件句柄,还会引发频繁的随机读取(random reading),由于寻道和连接开销大增,导致读性能大幅度下滑。
- 降低基于元数据过滤(Data Skipping)的效率: 小文件过多意味着元数据索引文件(manifest 等)条目庞大,查询规划(Query Planning)的解析时间变长,数据块过滤机制在海量微小文件面前的效率也大打折扣。
3. 对状态、元数据与内存的消耗
- 写入缓冲区(Write Buffer)内存被极度稀释: 每一个写入通道中的活跃 Bucket 都需要在堆内存中维护一定的写入缓冲区(Write Buffer)以缓冲数据。在桶数过多时,每个桶分配到的实际 Buffer 极小,这会导致即便数据只来了几条,Buffer 就已达到上限触发强制溢写(Flush),进一步加剧了小文件的生成。若维持较大的 Buffer,又极易导致系统堆内存超限发生 OOM。
- HDFS NameNode 元数据压力巨大: 在 HDFS 等分布式文件系统上,每一个 Bucket 都是一个单独的物理文件夹。桶数设置过多(加上分区数),会在 HDFS 上产生海量的目录和极多的小文件。这会使 NameNode 的内存负载急剧上升,危及整个大数据集群的存储系统稳定性。
- 动态桶模式下的 HASH 索引内存激增: 如果在动态桶(Dynamic Bucket)下通过不当的参数配置导致自动扩容出了过多的 Bucket,Paimon 需要维护更大规模的 HASH 索引来映射主键 Key 与 Bucket 的对应关系,这将显著增加额外的内存消耗(通常非活跃分区不消耗,但大流量分区的索引内存开销不可忽视,例如单个分区内每 1 亿个 Key 约额外占用 1GB 内存)。
三、 官方提供的最佳实践建议
针对 Bucket 数量过大或过小引起的各类问题,Apache Paimon 官方文档中给出了