 播面
播面 什么是 Paimon 的 Tag(标签)和 Branch(分支)功能?
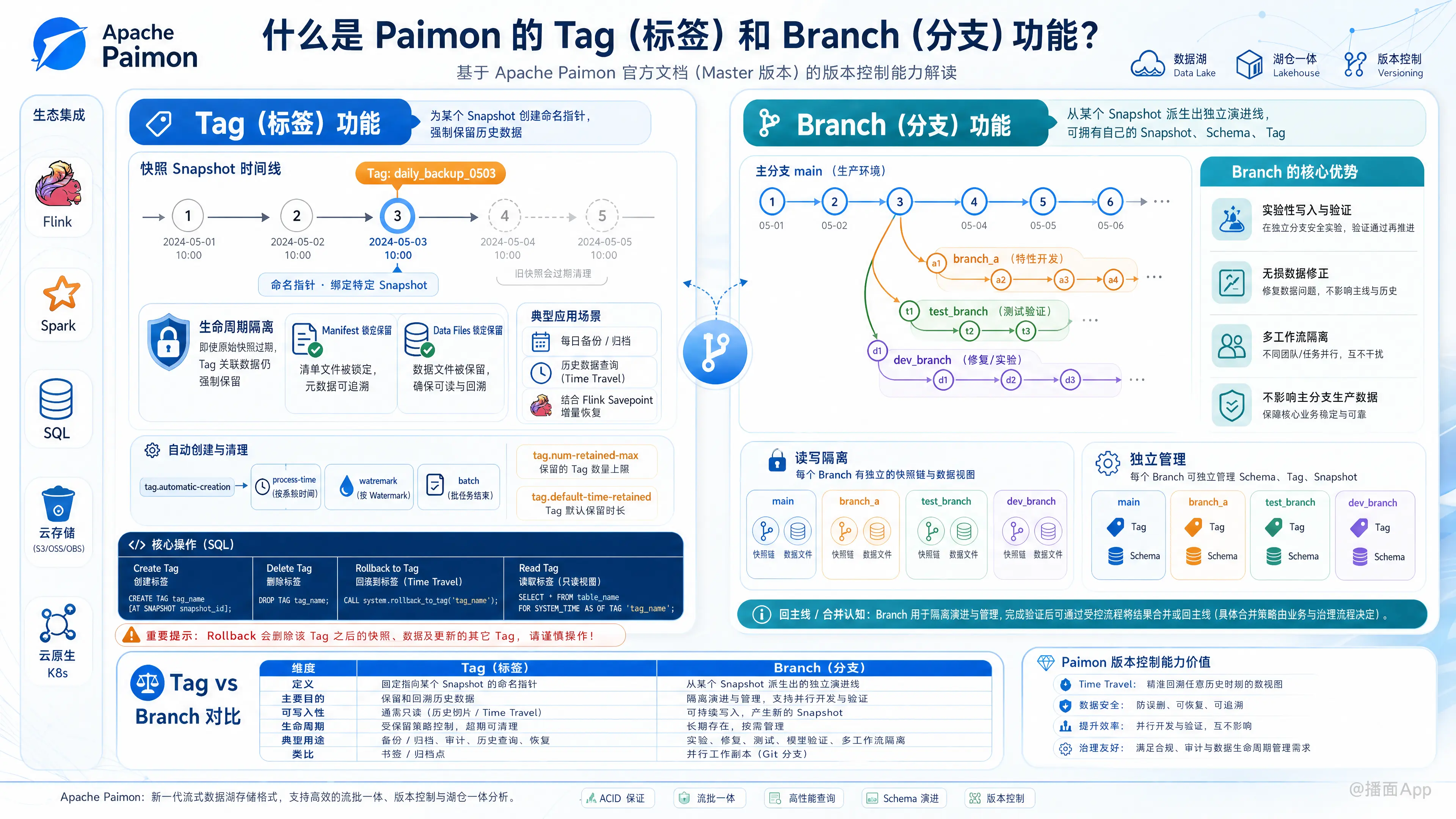
基于 Apache Paimon 官方文档(Master 版本),Paimon 提供了类似 Git 的版本控制功能,其中包括 Tag(标签) 和 Branch(分支)。这两个功能为数据湖上的数据回溯、历史归档、实验性数据写入、无损数据修正以及多工作流隔离提供了强大的支持。
以下是关于 Paimon 的 Tag 和 Branch 功能的详细解读:
一、 Paimon Tag(标签)功能
在流式数据写入中,Paimon 会频繁地生成快照(Snapshot)。虽然快照可以提供历史数据的查询通道,但在常规场景下,由于保留过多快照会占用海量存储,Paimon 默认会根据配置定期清理过期的快照及底层关联的数据文件(Snapshot Expiration)。一旦快照过期,历史数据就无法再被查询。
为了解决这个问题,Paimon 引入了 Tag(标签) 功能。
1. 什么是 Tag?
Tag 是绑定在某个特定 Snapshot(快照)上的命名指针。
- 生命周期隔离: 创建 Tag 后,该 Tag 对应快照中所关联的 Manifest(清单文件)和 Data Files(数据文件)将被强制保留,即使原始快照在主分支过期被清理,Tag 对应的数据也不会被物理删除。
- 典型应用: 每日数据备份/归档(如每天生成一个以日期命名的 Tag,供离线批计算读取历史某天的数据)、与 Flink Savepoint 结合进行作业的增量恢复。
2. Tag 的自动创建与清理
除了手动创建,Paimon 还支持在写入作业中自动创建 Tag,通过配置表参数 tag.automatic-creation 开启:
process-time: 基于机器系统时间定期创建 Tag。watermark: 基于 Sink 输入的 Watermark 创建 Tag。batch: 在批处理场景下,当前任务运行结束时自动生成一个 Tag。
为了防止 Tag 无限增长,可以使用 tag.num-retained-max 或 tag.default-time-retained 配置自动删除或控制最大保留数量。
3. 核心操作
在 Flink SQL、Spark SQL 或 Java/Python API 中,你可以方便地管理 Tag:
创建 Tag (Create Tag):
sql-- 基于最新的快照创建名为 'tag_name' 的标签 CALL sys.create_tag('mydb.my_table', 'tag_name'); -- 基于指定快照 ID (如 id=2) 创建标签 CALL sys.create_tag('mydb.my_table', 'tag_name', 2);删除 Tag (Delete Tag):
sqlCALL sys.delete_tag('mydb.my_table', 'tag_name');回滚到 Tag (Rollback to Tag):
当由于程序异常等原因导致数据污染时,可以通过 Flink Action 将表回滚到某个安全 Tag:bash<FLINK_HOME>/bin/flink run \ /path/to/paimon-flink-action.jar \ rollback_to \ --warehouse <warehouse-path> \ --database <database-name> \ --table <table-name> \ --version <tag-name>注意:回滚操作会删除此 Tag 之后产生的全部快照、数据以及比它更新的其它 Tag。
读取 Tag 数据 (Read Tag):
在 Flink/Spark 中使用 Time Travel 读取该标签对应的历史切片:sql-- 查询特定 Tag 下的数据 SELECT * FROM my_table /*+ OPTIONS('scan.tag-name'='tag_name') */;
二、 Paimon Branch(分支)功能
在传统的数据管道中,如果发现历史流数据有误,直接在主工作流上进行数据修正是非常困难且危险的,因为这会破坏当前正在运行的读写任务,并且下游用户会看到不一致的临时结果。
Branch(分支) 功能正是为了解决数据湖的多版本管理和数据隔离修正问题而设计的。
1. 什么是 Branch?
Paimon 默认将现有的主力读写流程运行在 main(主)分支上。通过创建自定义的数据分支(Custom Branch),用户可以:
- 零拷贝实验: 启动新的分支不需要拷贝真实的物理数据,直接基于某个 Tag(即历史快照点)创建,实现对现有数据的复用。
- 读写隔离: 新的测试任务或数据修正任务可以在自定义分支上单独运行,不会干扰
main分支上正在进行的流式读写。 - 合并回主线: 在分支中完成实验、测试或数据校验后,可以通过合并(Merge/Replace)操作将修正后的数据无缝替换到
main分支中。
2. 核心操作与使用
创建分支 (Create Branch):
Paimon 支持从某个指定的 Tag 创建分支,或者创建一个空分支(即初始状态为空表)。sql-- 基于 tag1 创建名为 branch1 的分支 CALL sys.create_branch('default.my_table', 'branch1', 'tag1'); -- 创建一个空的初始分支 branch1 CALL sys.create_branch('default.my_table', 'branch1');删除分支 (Delete Branch):
删除分支只会删除它的分支元数据(Metadata),底层的共享物理数据不会被删除。sqlCALL sys.delete_branch('default.my_table', 'branch1');对分支进行读写 (Read / Write with Branch):
Paimon 使用系统表的特殊命名格式table$branch_<branch_name>来指定特定分支的数据:sql-- 从分支 branch1 中读取数据 SELECT * FROM `my_table$branch_branch1`; -- 向分支 branch1 中写入数据 INSERT INTO `my_table$branch_branch1` SELECT ...;快速向前合并 (Fast Forward):
当你在自定义分支branch1上完成了数据修整或 schema 结构改造,并验证无误后,可以使用fast_forward将其合并回main分支。sqlCALL sys.fast_forward('default.my_table', 'branch1');- 底层原理: 该操作会删除
main分支中在“分支初始 Tag”之后创建的所有快照、Tag 和 Schema,并将自定义分支中的对应快照、Tag 和 Schema 复制并覆盖到main分支中,从而实现无损的高效数据重构。
- 底层原理: 该操作会删除
3. 典型高级用法:回退分支批量读取 (Batch Reading from Fallback Branch)
这是 Branch 功能中非常实用的一项特性。通过设置表参数 scan.fallback-branch,可以巧妙地结合实时流与离线修正批流。
应用场景:
假设在 Paimon 中建了一张按日期分区的表:- 有一个长期运行的流处理作业(Streaming Job)正在源源不断地把今天最新的数据写入自定义的
streaming_branch分支,以满足实时查询需求。 - 每天晚上,会启动一个离线批处理作业(Batch Job),将经过逻辑校准和修正后的“昨日历史分区数据”写入
main分支,以保证最终数据的准确性。 - 当用户通过批任务查询表时,他们希望首选读取
main分支(获取已校准的昨日分区数据);但如果某个分区在main中不存在(例如“今天的分区”),用户希望能直接从实时写入的streaming_branch分支中“兜底”读取。
- 有一个长期运行的流处理作业(Streaming Job)正在源源不断地把今天最新的数据写入自定义的
如何配置:
在读取时设置scan.fallback-branch为streaming_branch即可:sql-- 配置 fallback-branch SELECT * FROM my_table /*+ OPTIONS('scan.fallback-branch'='streaming_branch') */;在此模式下,Reader 在遇到主分支不存在的分区时,会回退到指定的
fallback-branch中寻找该分区,并将两者拼接返回。
三、 总结
在 Apache Paimon 中,Tag 类似于数据在某一时刻的“只读快照保护锁”,确保历史切片不被过期清理;而 Branch 则是“可写的沙盒环境”,支持用户在隔离的维度下进行各种实验、数据订正,并可以通过 Fast-forward 合并回主线。
通过将 Tag 和 Branch 联合使用,Paimon 为流式数据湖仓带来了极高的数据灵活性与安全保障,极大降低了在生产环境中维护和修复流式数据的难度。