 播面
播面 Paimon 支持哪些流式消费启动模式(如 latest、latest-full、from-timestamp 等)?
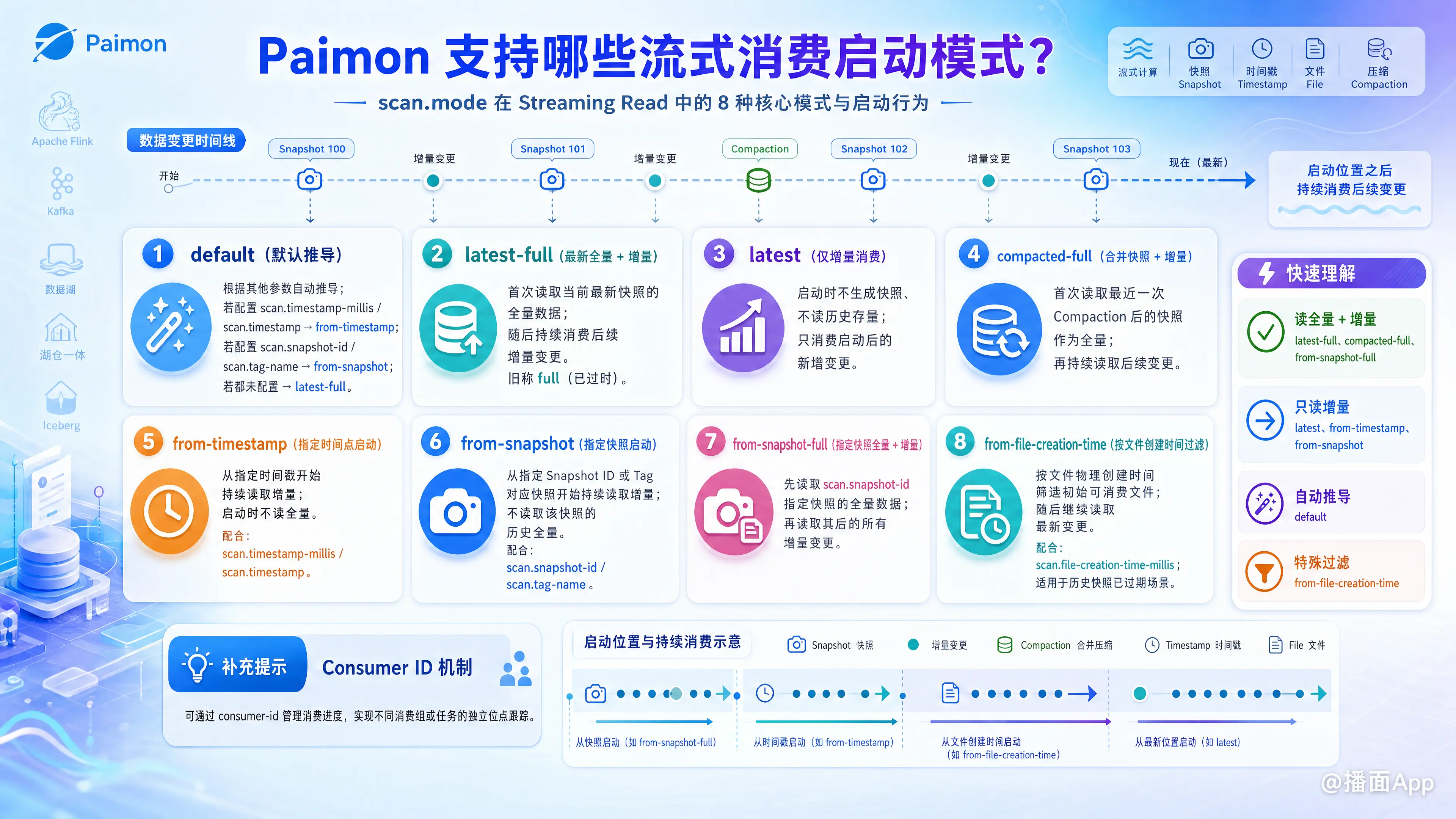
根据 Apache Paimon 官方文档中关于 scan.mode(扫描/读取模式)的核心配置,Paimon 在流式消费(Streaming Read)时支持以下几种主要的启动模式:
1. default(默认推导模式)
- 行为:Paimon 会根据用户配置的其他表属性来自动推导实际的流式启动模式。
- 具体推导规则:
- 如果指定了
scan.timestamp-millis(或scan.timestamp),则实际启动模式推导为from-timestamp。 - 如果指定了
scan.snapshot-id或scan.tag-name,则实际启动模式推导为from-snapshot。 - 若上述相关属性均未指定,则默认采用
latest-full模式。
- 如果指定了
2. latest-full(最新全量 + 增量)
- 行为:在流式作业首次启动时,读取当前表的最新快照(Latest Snapshot)作为全量初始化数据,然后持续增量地消费该快照之后产生的最新变更数据。
- 说明:该模式在部分早期版本中被称为
full(现已被标记为过时,但其行为与latest-full完全相同)。
3. latest(仅增量消费)
- 行为:流式消费启动时不生成快照,也不读取历史存量数据,而是只持续消费启动之后新写入、新产生的变更数据。
4. compacted-full(合并快照 + 增量)
- 行为:首次启动时读取表上最近一次 Compaction(合并压缩)之后生成的快照作为初始化全量数据,此后持续读取后续新产生的变更数据。
- 适用场景:有助于跳过中间未合并的小文件或历史临时状态,直接基于合并后的最新稳定快照启动流式计算。
5. from-timestamp(指定时间点启动)
- 行为:持续读取从指定时间戳开始的增量变更数据,启动时不产生全量快照。
- 配合参数:
scan.timestamp-millis:指定 Unix 毫秒时间戳。若表中没有比该时间戳更早的快照,则系统会默认退化到选择最早的快照启动。scan.timestamp:指定本地时区的时间戳字符串(如'2023-01-01 00:00:00'),系统会自动将其转换为 Unix 毫秒数。
6. from-snapshot(指定快照启动)
- 行为:持续读取自指定快照 ID 开始的增量变更数据,在启动阶段不读取该快照的存量历史数据。
- 配合参数:
scan.snapshot-id:指定需要开始消费的 Snapshot ID。scan.tag-name:也可以通过指定一个 Tag 名称来定位其对应的起始快照。
7. from-snapshot-full(指定快照全量 + 增量)
- 行为:在首次启动时,首先生成并读取由
scan.snapshot-id指定快照的全量数据,然后再持续读取该快照之后发生的所有增量变更。 - 配合参数:
scan.snapshot-id(必须配置)。
8. from-file-creation-time(文件创建时间过滤)
- 行为:生成快照并按照文件的物理创建时间进行过滤。对于流式数据源,首次启动时会根据文件创建时间筛选出符合条件的文件进行消费,随后继续读取最新的变更。
- 配合参数:
scan.file-creation-time-millis。 - 适用场景:当历史快照因过期机制而被清理(无法使用 Time Travel 的精确快照)时,该模式提供了一种大致的物理级别时间过滤方案。
💡 补充提示:Consumer ID 机制
在配置流式消费时,Paimon 官方还支持通过 consumer-id 参数(如配置为 myid)来管理消费进度。启用后,Paimon 会将读取进度持久化记录在文件系统中,以便在流作业异常重启、未从 Flink 状态恢复或更换作业时,能自动寻找下一个对应的 Snapshot 继续进行增量消费,避免数据重复或遗漏。