 播面
播面 在使用 lookup 或 full-compaction 模式时,配置 changelog-producer.row-deduplicate 参数能够解决什么问题?
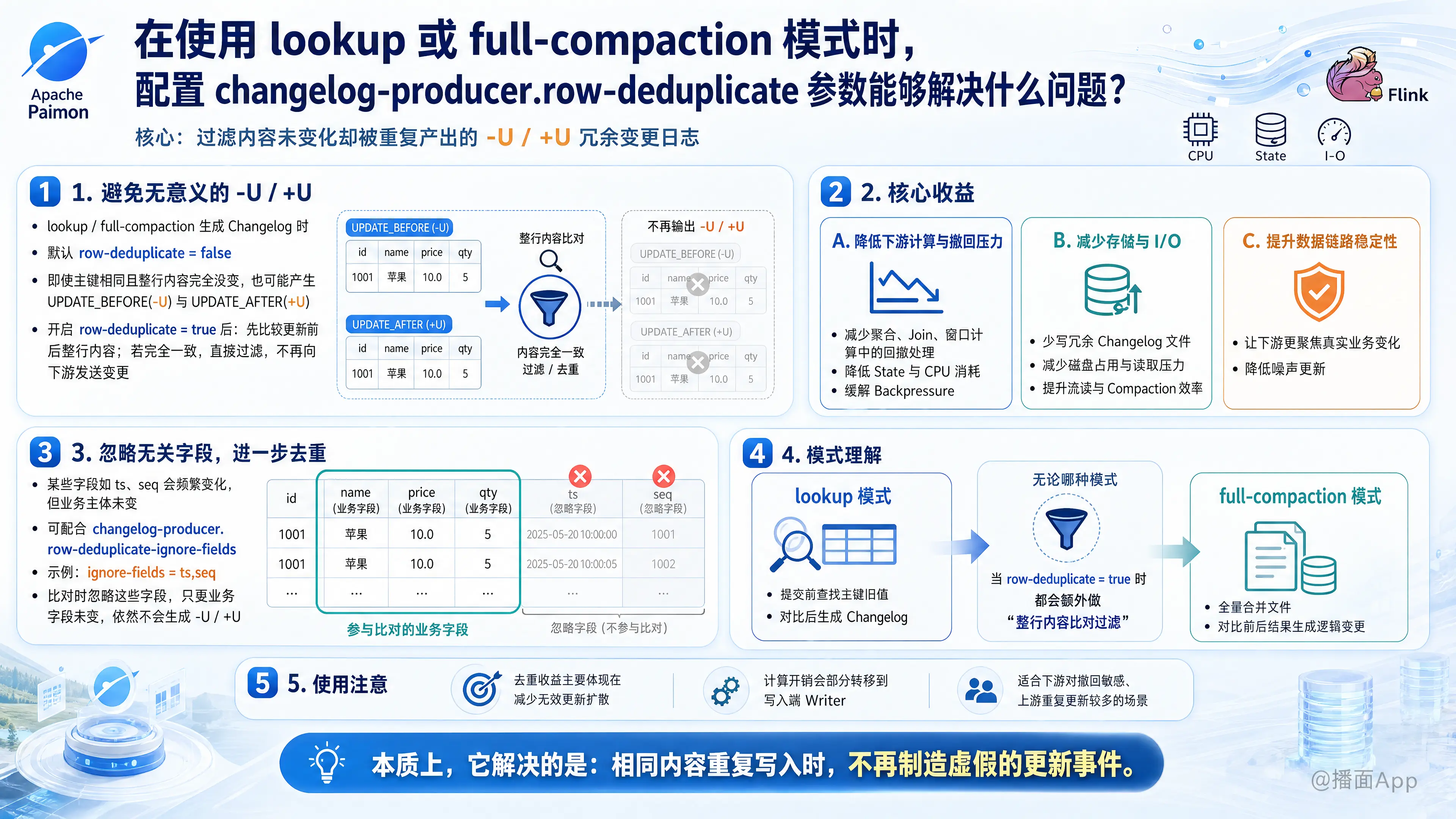
在 Apache Paimon 的官方文档中,参数 changelog-producer.row-deduplicate(默认值为 false)主要用于解决在配置了 lookup 或 full-compaction 变更日志生成器(Changelog Producer)时,因同一条记录未发生实际内容变化却产生冗余的撤回和更新日志(-U 和 +U)的问题。
具体而言,该参数的作用、解决的痛点及相关工作机制如下:
1. 解决的核心问题:避免生成“无意义”的变更日志(-U / +U)
在流式写入 Paimon 的主键表时,如果你启用了 lookup 或 full-compaction 模式来生成完整的 Changelog:
- Lookup 模式:在数据提交(Commit)之前,通过在本地缓存或磁盘中查找(Lookup)主键的旧值,进而对比生成 Changelog。
- Full-compaction 模式:通过对所有级别的文件进行全量合并,并对比前后两次 Full Compaction 的结果来产生逻辑变更差异。
默认情况(row-deduplicate = false)下的问题:
即使上游源源不断写入的记录中,某条数据的所有字段值(内容)与表中已有的历史记录完全一致,Paimon 在进行对比时,依然会默认针对该主键生成一对 UPDATE_BEFORE (-U) 和 UPDATE_AFTER (+U) 变更日志。
配置 row-deduplicate = true 后的效果:
Paimon 会在生成 Changelog 之前额外对比更新前后的整行数据内容。如果发现内容完全一致,它会直接过滤并丢弃这对无变化的 -U/+U 日志,从而不向外发送任何变更通知。
2. 带来的核心收益与应用场景
① 降低下游流式消费的计算和回撤压力
在实时数仓中,Paimon 表常常作为下游 Flink 任务的流式数据源(如进行窗口聚合、双流 Join 或多维指标计算)。
- 痛点:对于下游需要状态维护(Stateful)的聚合或连表算子,处理一个
-U和一个+U意味着需要进行撤回流计算,这会消耗大量的状态存储(State)和 CPU 算力。 - 解决:开启此参数过滤掉无实际内容变化的行,可以极大地减轻下游任务的性能瓶颈,避免不必要的回撤引发的反压(Backpressure)。
② 减少存储开销与 I/O 消耗
避免写入大量无实际业务变化的、冗余的 Changelog 数据,减少了磁盘上 Changelog 文件的生成数量和存储体积,提升了整体文件合并(Compaction)和流读的 I/O 效率。
3. 进阶搭配:排除特定字段的干扰
在实际生产场景中,数据往往带有一些高频更新但在业务比对中“不重要”的辅助字段。
- 比如数据的写入时间戳(
ts)或版本号/序列号(seq),这些字段在每次数据输入时都会变化,但业务主体数据(如订单状态、商品价格)并没有变。 - 如果直接启用
row-deduplicate = true,由于时间戳发生了改变,Paimon 依然会判定整行数据已发生变化,从而无法触发去重。
为了彻底解决此问题,Paimon 提供了配套参数:
changelog-producer.row-deduplicate-ignore-fields(默认无)。- 解决办法:你可以指定忽略这些时间戳、版本号等字段(例如配置为
ts,seq)。在进行重复性比对时,Paimon 会排除这些字段。只要其余的业务字段没有变化,哪怕时间戳变了,依然能够成功规避生成-U/+U日志。
4. 权衡与使用注意事项
虽然该参数能够很好地优化下游消费,但在使用时官方文档也提到了相关开销和配置建议:
- 计算开销转移:由于开启该参数后,Paimon 在写入端(Writer)需要进行额外的字段值逐一对比计算,会消耗一定的 CPU 资源。因此,官方推荐仅在预期存在大量无效、重复写入的业务场景中开启此参数。
- Flink 资源配置提示:官方文档在介绍此功能时特别备注,如果使用
lookup配合行去重,请务必调大 Flink 的最大并发检查点配置,即:这对于保障 Lookup Changelog 阶段的写入和检查点性能至关重要。plaintextexecution.checkpointing.max-concurrent-checkpoints