 播面
播面 lookup 模式的 Changelog Producer 的工作机制
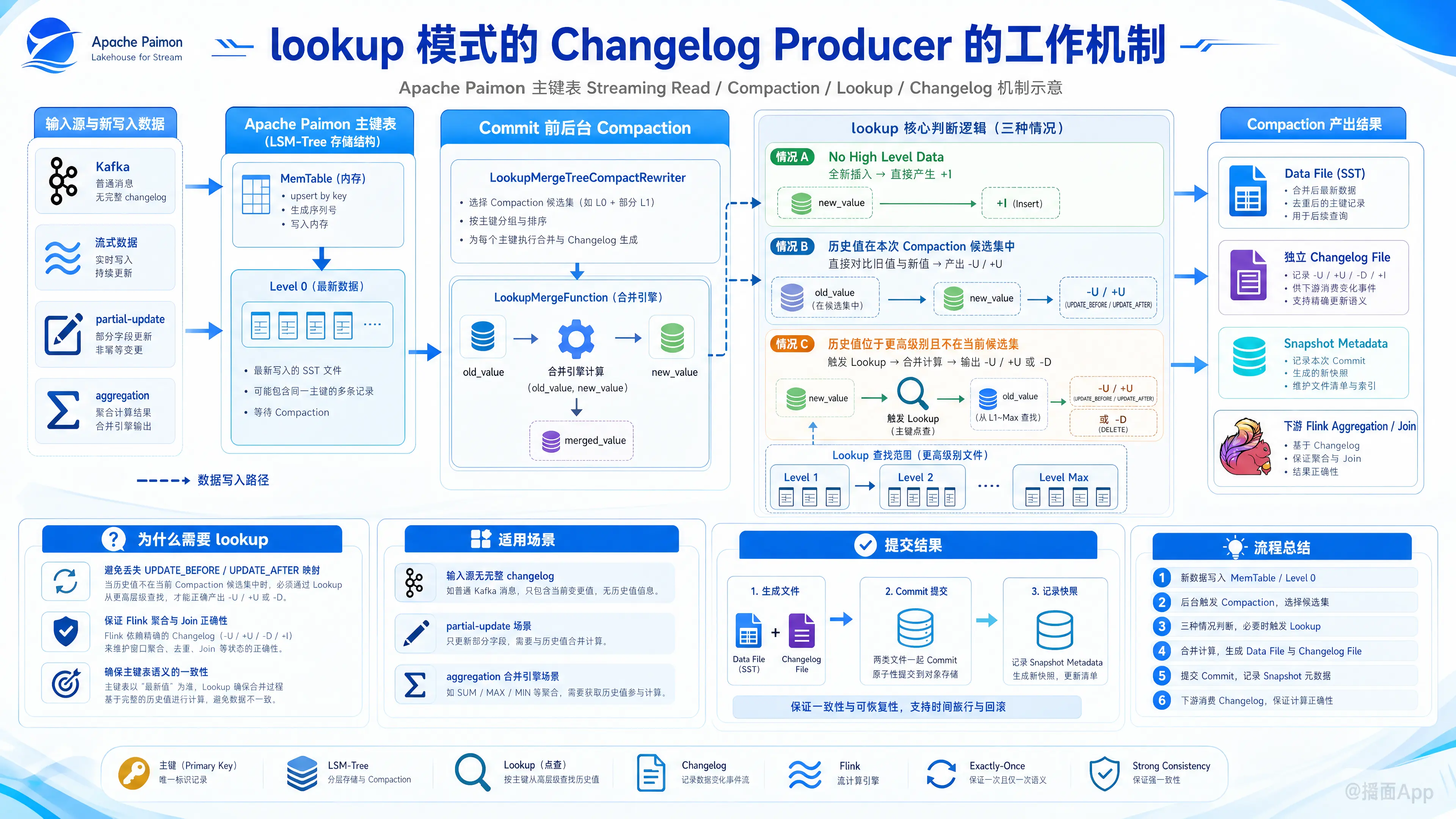
在 Apache Paimon(主键表)的设计中,流式读取(Streaming Read)通常需要准确的变更日志(Changelog)来保证下游计算(如 Flink 的聚合、Join 操作)的正确性。如果输入源本身无法提供完整的 Changelog(例如普通的 Kafka 消息,或者在使用 partial-update 或 aggregation 合并引擎时,输入数据仅是局部的片段),那么直接读取 LSM-Tree 产生的数据可能会丢失 UPDATE_BEFORE(-U)和 UPDATE_AFTER(+U)的完整映射关系。
为了解决这个问题,Paimon 提供了 lookup 模式的 Changelog Producer。以下结合 Paimon master 分支的设计与源码架构,详细剖析其工作机制:
一、 lookup 模式的核心工作流程
lookup 模式的基本思想是:在数据提交(Commit)之前,通过在本地或远程“点查(Lookup)”主键的旧值,在 Compaction 阶段实时拼装并产出完整的 Changelog。
其详细生成机制可以分为以下几个步骤:
1. 触发时机:后台 Compaction(合并)
lookup 模式的 Changelog 并不是在数据一写入内存(MemTable)时就立即产生的,而是在 Compaction(合并) 阶段。
- 默认情况下,Paimon 会在每次 Commit 前对新写入的 Level 0 文件进行 Compaction。
- 此时,系统会使用专门的重写器
LookupMergeTreeCompactRewriter和合并函数LookupMergeFunction来处理合并逻辑。
2. 判断是否需要点查(Lookup)
在进行 LSM-Tree 文件的合并时,以主键(Key)为维度进行遍历:
- 情况 A:无更高级别数据(No High Level Data)
如果合并的 Key 只存在于 Level 0 中,且更高级别(High Levels,即历史已提交的数据层)中没有该 Key,说明这是全新插入的数据。此时直接产生一条+I(INSERT) 的 Changelog。 - 情况 B:历史数据已在当前的合并候选集中
如果该 Key 在更高级别的数据正好也在本次参与 Compaction 的文件列表中(可以直接在内存中拿到旧值),系统将直接利用该旧值与新值合并,计算并写出-U和+U变更日志。 - 情况 C:历史数据在更高级别,且不在当前合并候选集中
此时,内存中只有新值,没有该 Key 先前的历史值。Paimon 此时会触发点查(Lookup)机制:通过主键去更高级别(Level 1 至 Level )的文件中查找该 Key 对应的最新历史值(old_value)。
3. 执行点查与 Changelog 生成
- 点查历史值:利用 Paimon 的
LookupLevels结构向更高级别发起点查,获取old_value。 - 应用合并引擎:将获取到的
old_value与本次写入的new_value传入对应的合并引擎(如deduplicate、partial-update或aggregation)进行合并,得到最终的merged_value。 - 输出 Changelog:
- 写入
-U(UPDATE_BEFORE) 文件,其内容为old_value。 - 写入
+U(UPDATE_AFTER) 文件,其内容为merged_value。 - 如果合并后的结果判定为删除(DELETE),则会生成
-D(DELETE) 变更日志。 - 这些变更数据会被写入到独立的 Changelog File 中,在 Commit 期间与 Data File 一起提交,并记录在 Snapshot 的元数据内。
- 写入
二、 本地 Lookup Store 缓存机制(如何高效点查)
在分布式文件系统(如 HDFS 或 S3)上直接进行点查,其 I/O 延迟是不可接受的。为了保证点查效率,Paimon 设计了高效的 本地 Lookup Store 缓存机制:
- 格式转换:Paimon 会把远程 DFS 上的列存数据文件(ORC/Parquet)拉取到本地,并转换为适合高并发 KV 点查的本地索引文件(Lookup Store)(基于 Block 结构、支持 Bloom Filter 的本地 SST 格式文件)。
- 多级缓存控制:
- 内存缓存:通过
lookup.cache-max-memory-size(默认 256 MB)限制点查索引在内存中的占用。 - 本地磁盘缓存:未命中的索引会从远程拉取并缓存在本地磁盘上,避免重复的远程 I/O。通过
lookup.cache-max-disk-size可以限制本地磁盘占用的上限。 - 生命周期管理:通过
lookup.cache-file-retention(默认 1 小时)控制本地缓存文件的有效期。过期后如需再次访问,会重新从 DFS 读取并构建本地索引。
- 内存缓存:通过
三、 激进的 Compaction 策略:Lookup Compaction
因为 Lookup 机制极其依赖于快速定位高级别(High Levels)的文件,如果 Level 0 的小文件过多,点查范围扩大,会导致 Lookup 性能急剧恶化。
为此,当启用 changelog-producer = lookup 时,Paimon 会默认采用非常激进的 Lookup Compaction 策略:
- RADICAL 模式(默认值):每次触发 Compaction 时,Paimon 会尽最大可能(使用
ForceUpLevel0Compaction策略)强制将 Level 0 的文件合并到更高级别。 - 这样能保证 Level 0 文件的数量始终维持在极低的水平,从而将点查范围控制在极小、极确定的文件集内。
- 相关的调优参数包括
lookup-compact(可选RADICAL或GENTLE)以及在温和模式下的最大强制合并间隔lookup-compact.max-interval。
四、 关键配置项与高级特性
在应用 lookup 模式时,还可以结合以下高级配置来优化性能:
| 配置项 | 默认值 | 类型 | 说明 |
|---|---|---|---|
changelog-producer |
none |
Enum | 设为 lookup 以启用此模式。 |
changelog-producer.row-deduplicate |
false |
Boolean | 行去重。若设为 true,当点查出的旧值与合并后的新值完全一致时(意味着没有实质改变),将不生成 -U和+U 日志,从而大大减少对下游的流量压力。 |
changelog-producer.row-deduplicate-ignore-fields |
(none) |
String | 进行行去重对比时,可以指定忽略某些字段(例如更新时间戳 update_time),避免因无意义的字段变更产生多余的 Changelog。 |
lookup-wait |
true |
Boolean | 是否在写入线程中同步等待 Lookup 结束。在高吞吐写入时,可以考虑调优此参数。 |
五、 lookup 模式的优缺点分析与调优建议
1. 优势
- 极佳的时效性:与
full-compaction(通常需要 30 分钟以上的大延迟)相比,lookup可以在每次 Commit 前或异步近实时地产生完整的 Changelog,延迟通常在分钟级以内。 - 避免下游 Flink 状态过大:因为 Paimon 产生了完美的 Changelog(包含旧值),下游 Flink 任务无需再使用极其沉重的
normalize状态算子来保留历史状态,从而大幅降低下游 Flink 任务的内存开销。
2. 缺点与系统开销
- 计算与 I/O 资源消耗极大:由于需要将远程文件拉取到本地进行转码,并在合并时频繁进行 KV 点查,该模式会消耗较多的本地 CPU、内存以及本地磁盘 I/O 资源。
- 可能影响写入吞吐:由于 Lookup 伴随着激进的 Compaction,如果本地磁盘或 CPU 成为瓶颈,可能会导致 Writer 的写入被反压。
3. 生产实践建议
- Flink 检查点调优:在 Flink 任务中,强烈建议将
execution.checkpointing.max-concurrent-checkpoints调大至3。因为 Lookup 阶段的 Compaction 可能会由于 I/O 阻塞导致 Checkpoint 耗时增加,多并发 Checkpoint 可以防止写入线程频繁被挂起。 - 合理分配本地磁盘空间:请确保 Flink TaskManager 容器挂载了高性能的本地 SSD 磁盘,并预留足够的磁盘空间作为 Paimon 的本地 Lookup 缓存,否则可能会发生因本地磁盘满或 I/O 瓶颈导致的写入失败。