 播面
播面 为什么流式消费 Paimon 表时,通常需要配置 changelog-producer?
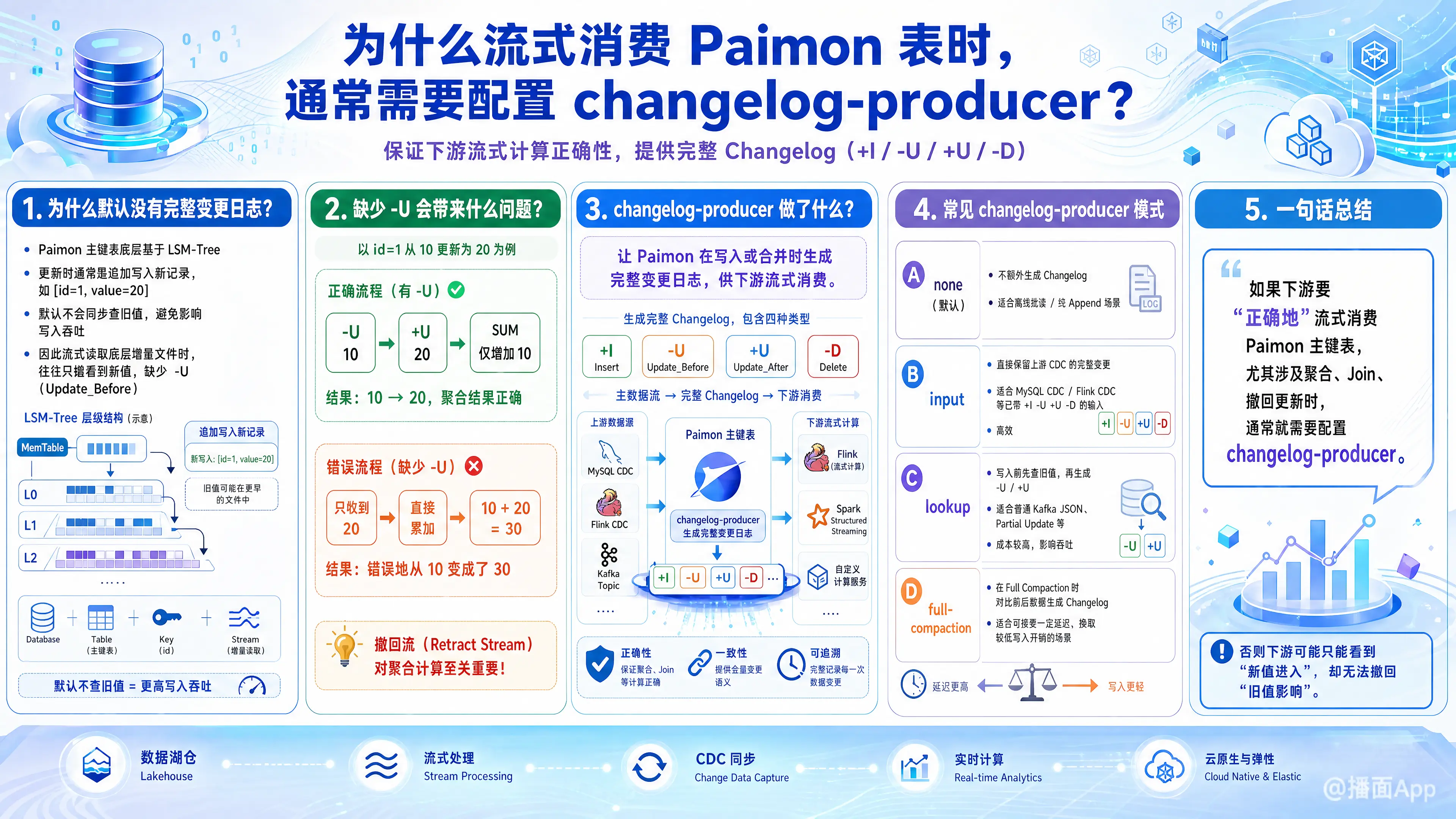
在流式消费 Paimon 表(特别是带有主键的表)时,通常必须配置 changelog-producer,其核心原因是为了保证下游流式计算的数据正确性,提供完整的变更日志(Changelog:包含 +I, -U, +U, -D)。
下面为您详细拆解背后的原理和原因:
1. 核心痛点:为什么默认情况下没有完整的变更日志?
Paimon 的主键表底层使用的是 LSM-Tree(Log-Structured Merge-Tree) 架构。
- 当你向 Paimon 写入一条更新数据(例如将主键
id=1的行的value从10改为20)时,Paimon 底层实际上是追加写入了一条新记录[id=1, value=20]。 - Paimon 存储层在没有特殊配置的情况下,不知道旧的值是什么(它不会在每次写入时去同步查找旧值,因为这会严重影响写入吞吐)。
- 如果下游 Flink 任务直接流式读取这种底层的追加文件,它只能看到一条新数据进入(
+I或+U),而无法获取到更新前的值(-U,即 Update_Before)。
2. 缺少 -U(更新前的值)会导致什么后果?
在 Flink 流处理中,完整的撤回流(Retract Stream)对于聚合计算至关重要。
假设下游任务是对 value 进行求和(SUM(value)):
- 正确的 Changelog 处理流程:
收到-U 10(减去旧值 10) -> 收到+U 20(加上新值 20)。最终 SUM 增加了 10。结果正确。 - 没有 Changelog Producer 的错误流程:
下游只收到新数据20。它不知道之前有过 10,直接把 20 累加进去。最终数据严重错误(变成了 10 + 20 = 30)。
3. changelog-producer 的作用
配置 changelog-producer 就是告诉 Paimon:“请你负责在写入或者合并数据时,帮我把完整的变更日志(Insert, Update_Before, Update_After, Delete)生成出来,以便下游流式消费。”
4. 常见的 changelog-producer 模式及其适用场景
Paimon 提供了几种不同的机制来生成 Changelog,你需要根据业务的输入源和延迟/吞吐要求来选择:
none(默认值)- 行为:不额外生成 Changelog。下游只能看到增量写入的文件。
- 适用场景:只做离线批量读取,或者下游流读不需要撤回机制(如纯 Append 场景)。
input- 行为:直接信任并保留输入流的数据作为 Changelog。如果你的上游本来就是 Flink CDC(已经包含了完整的 +I, -U, +U, -D),Paimon 会把这些变更原封不动地保存到特定的 Changelog 文件中供下游消费。
- 适用场景:上游是 CDC 数据源(如 MySQL CDC),且 Paimon 表没有配置让数据产生额外变更的机制(如 Partial Update / 聚合引擎)。这是最高效的方式。
lookup- 行为:在写入数据之前,Paimon 会先去底层存储中“查找(Lookup)”出旧的值,通过对比旧值和新值,实时生成完整的
-U和+U记录。 - 适用场景:上游输入只有
+I或+U(例如从 Kafka 读入的普通 JSON,没有变更类型),或者使用了 Partial Update(部分列更新),下游又必须流读的场景。 - 代价:由于写入前需要点查(Lookup),会消耗较多资源并降低写入吞吐。
- 行为:在写入数据之前,Paimon 会先去底层存储中“查找(Lookup)”出旧的值,通过对比旧值和新值,实时生成完整的
full-compaction- 行为:不在写入时生成 Changelog,而是在 Paimon 执行 Full Compaction(全量合并) 时,通过对比合并前后的数据差异来生成 Changelog。
- 适用场景:对写入吞吐要求极高,且下游流读可以容忍较高延迟(分钟级甚至更长)的场景。
总结
一句话解释:流式消费 Paimon 表配置 changelog-producer,是因为数据湖的列式存储和 LSM 架构默认无法提供流处理聚合所需的“更新前状态(Update_Before)”,必须通过该配置强制 Paimon 在存储侧生成并提供完整的变更流(CDC 流),从而保证下游流计算结果的绝对准确。
*(注:如果你的 Paimon 表是 Append-Only 表(没有主键),每次写入都是新增,不存在更新和删除,那么不需要配置 changelog-producer,直接流读即可。)*