 播面
播面 讲讲input 模式的 Changelog Producer 的工作原理?
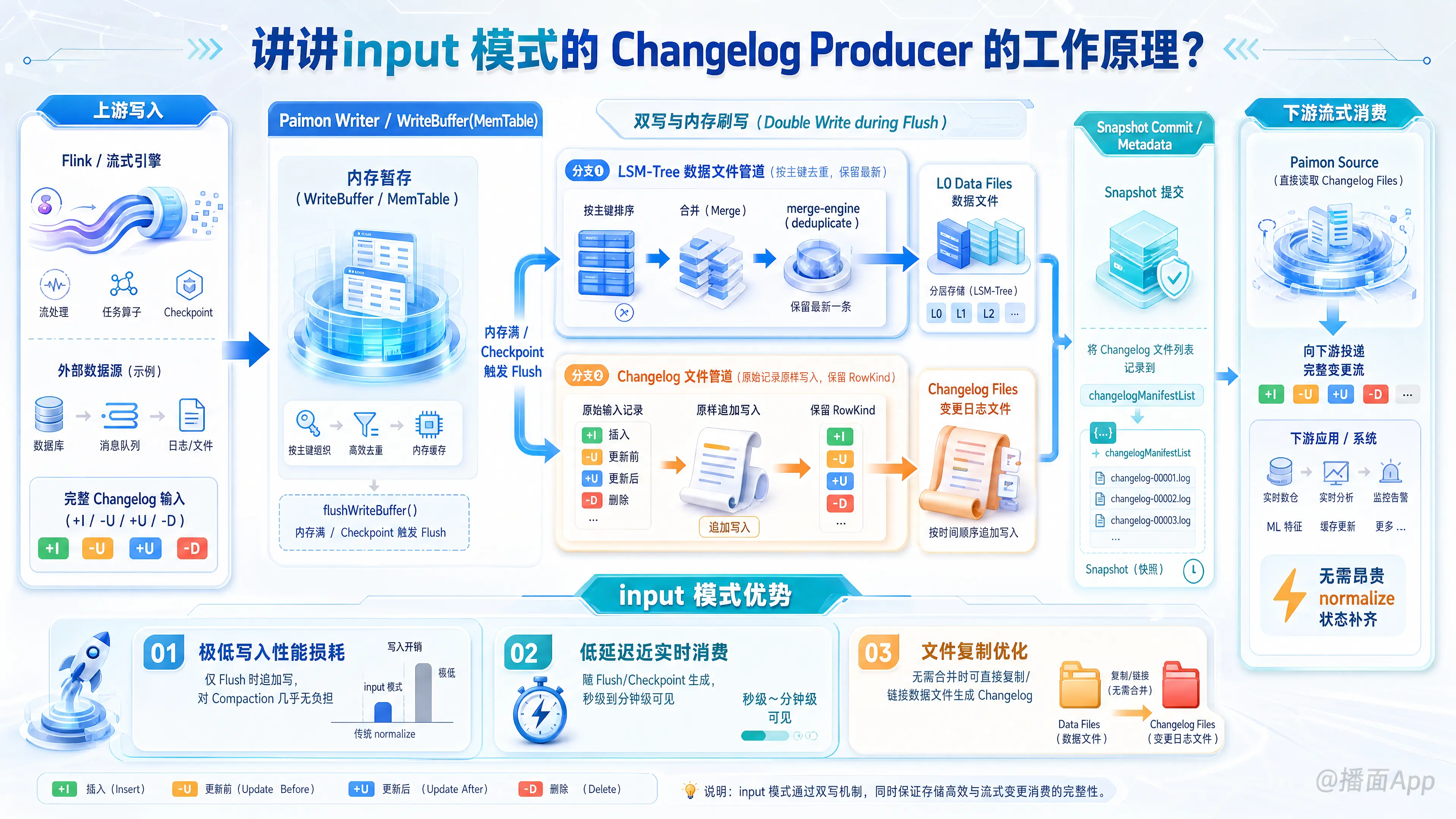
在 Apache Paimon 中,Changelog Producer(变更日志生产者)主要用于在主键表(Primary Key Table)流式读取的场景下生成完整的变更流(包含 INSERT +I、UPDATE_BEFORE -U、UPDATE_AFTER +U 以及 DELETE -D)。
在 Paimon 提供的几种 Changelog Producer 模式(none、input、lookup、full-compaction)中,input 模式是最轻量、写入性能损耗最小的一种。以下是根据 Apache Paimon 最新文档(master 分支)整理的 input 模式详细工作原理:
1. 核心工作原理:双写与内存刷写(Double Write during Flush)
input 模式的核心思想是:完全信任并依赖上游写入 Paimon 的输入数据流本身就是一套完整的 Changelog。Paimon 自身不进行任何复杂的历史数据对比,而是将输入的数据直接“复制”一份保存下来。
具体工作流程如下:
- 内存暂存 (Write Buffer):
当 Flink 等计算引擎向 Paimon 写入数据时,数据首先会进入内存中的WriteBuffer(MemTable)进行缓存。 - 双写刷盘 (Double Write during Flush):
当内存满了或者触发 Checkpoint 时,Paimon 写入器(Writer)会执行flushWriteBuffer操作将数据刷写到磁盘中。此时,写入器会同时启动两个写入管道:- LSM-Tree 数据文件管道:将内存中的数据按照主键进行排序、合并(根据指定的
merge-engine,如deduplicate仅保留最新一条),然后输出为 L0 层的普通 数据文件(Data Files)。 - Changelog 文件管道:直接将内存中未经过 LSM 合并的原始输入记录(保留它们原有的
RowKind,例如带有-U、+U、-D等标识的记录),以原样写入到完全独立的 Changelog 文件(Changelog Files) 中。
- LSM-Tree 数据文件管道:将内存中的数据按照主键进行排序、合并(根据指定的
- 元数据提交 (Commit):
在 Snapshot 提交阶段,新生成的 Changelog 文件列表会被记录在 Snapshot 元数据的changelogManifestList中。 - 下游流读消费 (Consumption):
当下游流式作业读取该 Paimon 表时,Paimon Source 会直接定位并读取这些单独的 Changelog 文件,将完整的变更直接投递给下游,而无需像none模式那样在 Flink 端生成昂贵的normalize(状态物化)算子来补齐-U消息。
2. input 模式的优势
- 极低的写入性能损耗:与
lookup模式(需要在 Compaction 时点查高层 LSM 树以获取旧值)和full-compaction模式(需要高延迟、高 CPU/IO 消耗的全局合并)相比,input仅在内存 Flush 时进行了一次追加写(Append)操作,对 Compaction 的性能几乎没有任何负面影响。 - 低延迟的近实时消费:由于 Changelog 文件是随着每次内存 Flush(伴随 Flink Checkpoint)实时生成的,下游可以在分钟级甚至秒级(取决于 Checkpoint 间隔)消费到增量变更。
- 文件复制优化(Copy Optimization):Paimon 内部有一项优化:当检测到输入的数据不需要在内存中进行任何合并(例如全量同步阶段,且输入记录互不重复,输入文件和最终产生的数据文件完全一致时),Paimon 会通过直接复制/链接数据文件来产生 Changelog 文件,避免不必要的双倍磁盘写入。
3. 使用前提与适用场景
使用 input 模式有一个绝对的前提条件:
写入 Paimon 的上游数据源本身必须是完整、合法的 Changelog。
典型适用场景:
- 数据库 CDC 同步:如通过 Flink CDC 摄入的 MySQL binlog、PostgreSQL WAL 变更流等。这些数据源天生就包含了完备的
UPDATE_BEFORE与UPDATE_AFTER。 - Flink 有状态计算的产出:上游 Flink 任务进行聚合或双流 Join 后输出的带撤回(Retraction)信号的变更流。
- 数据库 CDC 同步:如通过 Flink CDC 摄入的 MySQL binlog、PostgreSQL WAL 变更流等。这些数据源天生就包含了完备的
不适用场景:
如果上游只是一个简单的INSERT-ONLY(只插不删改)的数据源,或者只包含UPDATE_AFTER而缺失UPDATE_BEFORE(如部分应用生成的 Log 数据),使用input模式无法帮下游补齐-U消息,下游如果含有需要撤回的算子(如SUM、COUNT)将会导致计算结果失真。
4. 局限性与注意事项
- 与特定合并引擎(Merge Engine)的冲突:
- 如果主键表配置了
partial-update(部分更新)或aggregation(预聚合)引擎,当有下游需要流读该表时,不推荐将changelog-producer设为input。 - 原因:
input模式只记录“原始输入”。当进行partial-update时,输入往往只包含部分字段,而合并后的完整行是在 LSM-tree 数据文件中维护的。如果设为input,下游流读时只会读到未合并的 raw 局部字段,无法获取整行更新的正确视图。在这类场景下,通常必须选择lookup或full-compaction。
- 如果主键表配置了
- 乱序与重复数据:
- 因为
input模式仅仅是把写入缓冲区的记录直接倒出,所以如果同一个 Checkpoint 窗口内存在乱序数据或重复的主键更新,Changelog 文件中会原封不动地保留这些冗余的中间过程。Compaction 只会合并 LSM-tree 的普通数据文件,而不会对已经写死的 Changelog 文件进行二次清洗。
- 因为