 播面
播面 Paimon 的读时合并(Merge-on-Read)与写时合并(Merge-on-Write / Deletion Vectors)模式的区别
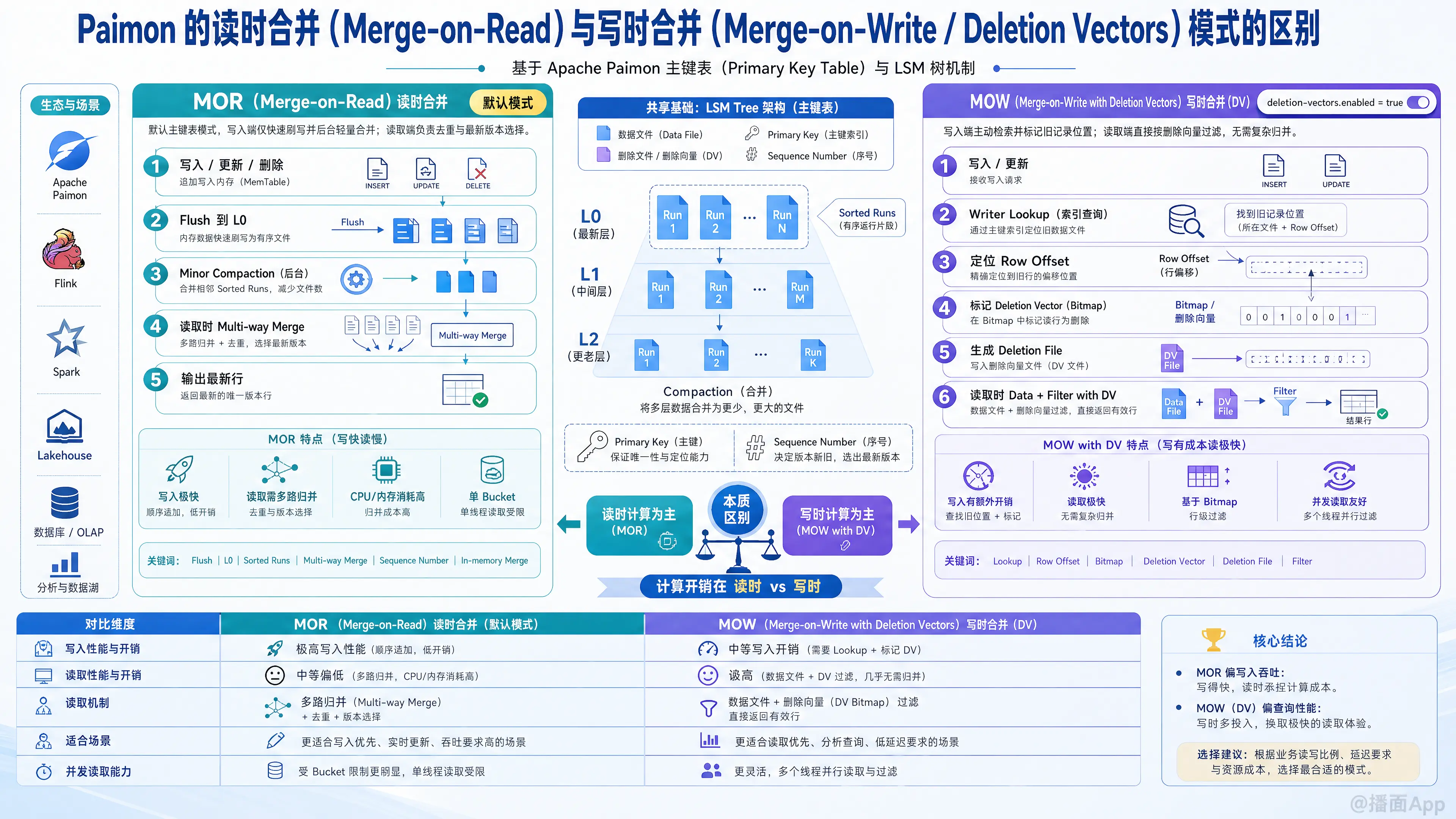
根据 Apache Paimon 的官方文档(Master 分支概念与 Table Mode 章节),主键表(Primary Key Table)主要通过 LSM 树(Log-Structured Merge-tree) 来组织和存储数据。针对数据的写入与更新,Paimon 提供了不同的处理模式,其中最核心的对比就是读时合并(Merge-on-Read,简称 MOR) 与写时合并(Merge-on-Write,此处特指基于 Deletion Vectors 的 MOW 模式)。
以下根据 Paimon 文档对这两种模式进行详细剖析与对比:
一、 核心概念与工作原理
1. 读时合并(Merge-on-Read,MOR)— 默认模式
- 写入阶段:
Paimon 的默认主键表模式。当有数据写入、更新或删除时,写入端(如 Flink / Spark 任务)只需将数据快速刷写(Flush)到 LSM 树的 L0(Level 0)文件中,并在后台触发 Minor Compaction(轻量级合并)以限制文件数量。- 特点:写入过程不作实时的主键去重或旧数据物理删除,只进行顺序追加和常规的 LSM 树分层。
- 读取阶段:
在查询时,读取端(Reader)必须在内存中对所有相关的 Sorted Runs(有序文件组)进行多路归并(Multi-way Merge)。通过比较主键(Primary Key)及序列号(Sequence Number)等信息,过滤掉旧版本数据,仅输出最新的一行。
2. 写时合并(Merge-on-Write,MOW — 基于 Deletion Vectors)
- 写入阶段:
需要通过配置'deletion-vectors.enabled' = 'true'来开启。在数据写入或更新时,Paimon 的 Writer 会主动去查询 LSM 树(进行主键检索 Lookup),找到该主键之前所在的数据文件和具体的行偏移量(Row Offset),并在对应的 Deletion Vector(删除向量,通常为 Bitmap 格式) 中标记这一行已被删除,随后产生一个单独的 Deletion File(删除文件)。- 特点:它不会像传统的 COW(Copy-on-Write)那样去重写整个数据文件,而是以轻量级的“逻辑标记”方式,在写入时就精确锁定了需要过滤的数据位置。
- 读取阶段:
读取端(Reader)无需进行复杂的内存多路归并,只需直接加载数据文件,并利用对应的 Deletion Vector 进行行级过滤(Data + Filter with Deletion Vector),即可直接拼装出最终的正确数据。
二、 核心性能与特性对比
| 对比维度 | 读时合并 (Merge-on-Read / MOR) | 写时合并 (Merge-on-Write / MOW with DV) |
|---|---|---|
| 写入性能与开销 | 极高。写入操作极快,几乎没有 Lookup 检索和生成额外索引的负担。 | 中等(引入额外开销)。由于在写入时需要进行 LSM 树 Lookup 检索,并生成/写入对应的 Deletion File(删除向量文件),因此写入吞吐量会受到一定影响。 |
| 读取性能与开销 | 中等/偏低。Reader 需要进行内存中的多路归并及主键对比计算,CPU 和内存消耗较大,在大数据量下容易成为瓶颈。 | 极高。无需在内存中进行多路归并计算,只做基于 Bitmap 的行过滤,读取效率与普通的 AppendOnly 表或 COW 表相当。 |
| 并发读取能力 | 有限(受限于 Bucket 数量)。由于多路合并要求同一个 Bucket 内的所有有序运行文件(Sorted Runs)协同读取,单个 Bucket 在 MOR 模式下通常只能由单线程读取。如果 Bucket 的数据量过大,将严重限制并发度。 | 无限制。并发读取不再受 Bucket 数量的限制。不同的 Task 可以并发、多线程地读取同一个 Bucket 下的不同数据文件并应用 DV 进行过滤。 |
| 非主键列过滤下推 (Filter Pushdown) | 不支持。如果对非主键列进行过滤下推(Data Skipping),可能会不小心过滤掉更新后的最新数据,从而错误地暴露旧数据。 | 完美支持。因为数据行是否存活在读取前就已经通过 Deletion Vector 唯一确定,非主键列上的过滤条件可以安全下推。 |
| 推荐适用场景 | 适合实时写入吞吐要求极高,但下游查询频率不高,或者只做增量流式消费(Streaming Read)的场景。 | 适合OLAP 分析、频繁交互式查询、高性能批处理查询的场景。 |
三、 Deletion Vectors (MOW) 的底层设计与机制
Paimon 文档中对 Deletion Vector 的底层机制也有深入的设计说明:
- 文件格式与存储 (Table Index):
- Deletion Vector(删除文件)存储在每个 Bucket 目录下的
index目录中。 - 该文件是一个二进制文件,采用特定的格式记录:
版本号 (1 byte) + <序列化长度, 序列化二进制体, 校验和>。
- Deletion Vector(删除文件)存储在每个 Bucket 目录下的
- Bitmap 位图实现:
Paimon 提供了两种位图表示:- 32位位图 (默认):基于
RoaringBitmap(org.roaringbitmap.RoaringBitmap)。 - 64位位图(配置
'deletion-vectors.bitmap64' = 'true'):针对 64 位整型位置进行了优化。此模式与 Apache Iceberg 规范兼容,如果希望外部引擎(如 Iceberg Reader)直接读取 Paimon 的 Deletion Vector 并达到高性能实时同步,可以启用该配置。
- 32位位图 (默认):基于
- L0 (Level 0) 文件过滤延迟:
由于 Level 0 文件在写入时还处于未完全整理状态,开启 MOW 时虽然会在写时生成 DV,但在利用 Time Travel(时间旅行)读取APPEND快照时,可能会遇到由于未完全完成过滤带来的微量数据延迟。 - 垃圾回收 (GC):
当一个数据文件本身由于后续的 Compaction 被物理删除时,指向该数据文件的 Deletion Vector 也会被逻辑标记为无效,并在对应的 Metadata / Snapshot 过期后被彻底清理。
四、 如何在 DDL 中启用相关模式
在创建主键表时,可以通过配置项来灵活切换这两种模式:
启用 读时合并(Merge-on-Read) (默认行为):
sqlCREATE TABLE my_table ( id BIGINT PRIMARY KEY NOT ENFORCED, name STRING, dt STRING ) WITH ( 'bucket' = '4' -- 默认即为 MOR 模式 );启用 写时合并(Merge-on-Write via Deletion Vectors):
sqlCREATE TABLE my_table ( id BIGINT PRIMARY KEY NOT ENFORCED, name STRING, dt STRING ) WITH ( 'bucket' = '4', 'deletion-vectors.enabled' = 'true', -- 开启写时合并模式 'deletion-vectors.bitmap64' = 'true' -- (可选)开启 64 位位图,以获得更好的 Iceberg 兼容性 );(补充) 传统的写时复制(Copy-on-Write / COW):
如果需要传统意义上完全同步合并的 COW(写完即产生完整合并后的新 Parquet/ORC 文件,代价极高),可以通过配置强制每次 commit 都进行 Full Compaction:'full-compaction.delta-commits' = '1'。