 播面
播面 Partial-update(局部更新)合并引擎在多流拼接场景下是如何工作的?
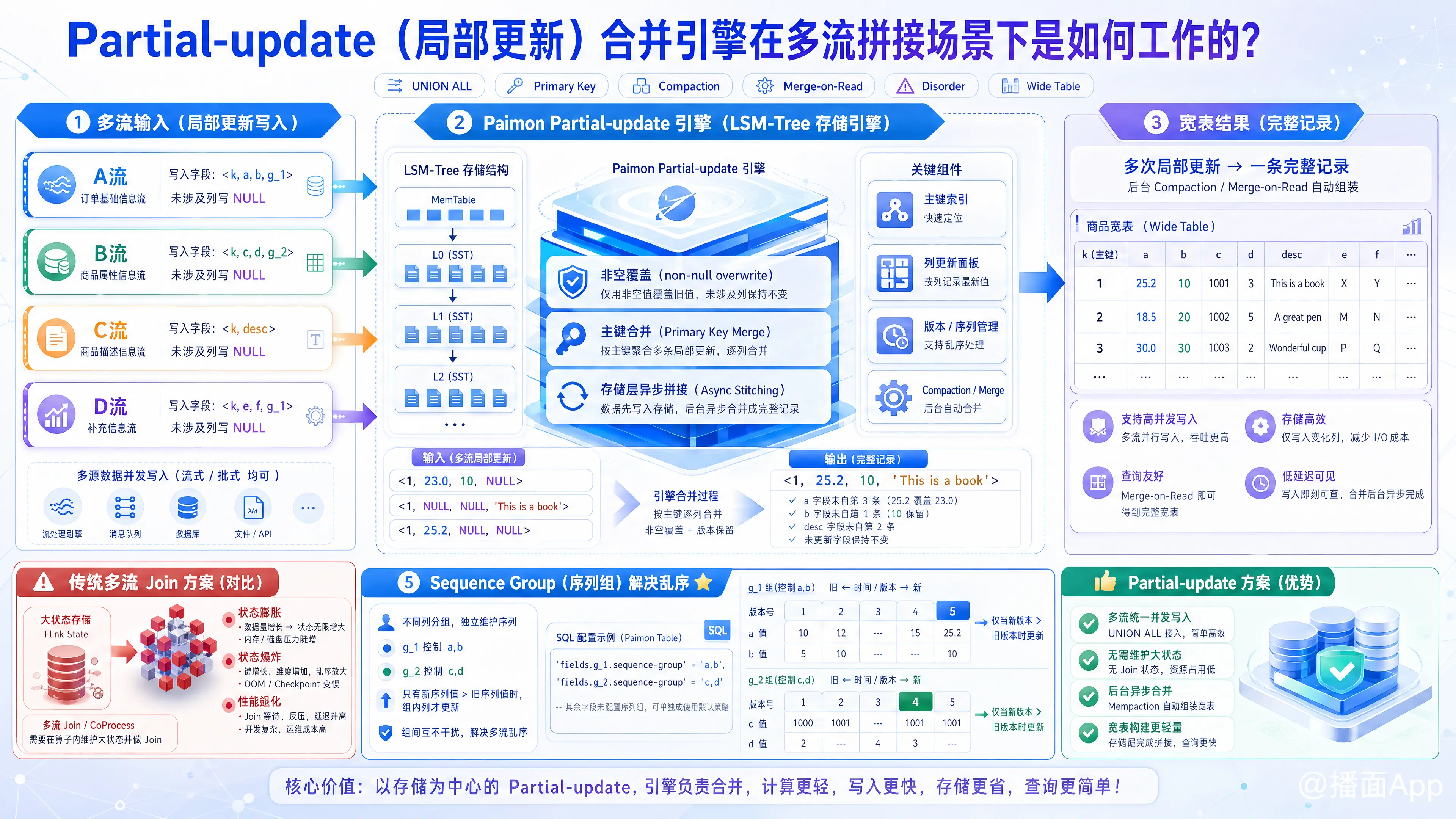
在 Apache Paimon 的 master 分支文档中,Partial-update(局部更新) 合并引擎是专为流式数据处理和多流拼接(宽表建设)场景设计的核心功能。它允许用户通过多次更新同一个主键的不同列,最终在存储层将数据融合成一条完整的记录。
以下是 Partial-update 合并引擎在多流拼接场景下的详细工作原理、核心机制以及关键配置:
1. Partial-update 的基本合并逻辑
在最基础的层面上,Partial-update 引擎根据主键(Primary Key)来合并多条记录。
非空覆盖:当接收到多条相同主键的记录时,Paimon 会用最新的非空(non-null)值逐个覆盖原有的列值,而输入中的
NULL值则不会覆盖已有数据。合并示例:
假设主键是第一列,Paimon 依次接收到以下三条局部更新的数据:<1, 23.0, 10, NULL><1, NULL, NULL, 'This is a book'><1, 25.2, NULL, NULL>
经过 LSM 存储引擎的合并(Merge)后,该主键最终在底层的合并结果为:
<1, 25.2, 10, 'This is a book'>。
2. 多流拼接场景下的工作机制
在传统方案中,多流拼接通常依靠 Flink 的双流/多流 Join(如 Regular Join、Interval Join),这需要在 Flink 状态(State)中维护海量的历史数据,极易导致 Flink 状态爆炸和性能退化。
Paimon 的 Partial-update 彻底改变了这一模式,其工作流如下:
- 统一并发写入:多个上游 Flink 任务(对应不同的数据流)可以通过
UNION ALL融合在一个作业中,或者作为独立的写入作业,直接并发往同一张 Paimon 表中写入各自关联的列(未涉及的列直接留空为NULL)。 - 存储层异步拼接:Flink 写入任务不需要维护复杂的 Join 状态,只需将带有主键的数据直接写入 Paimon 的 LSM-tree 中。
- 后台 Compact/读取时合并:Paimon 内部在执行后台 Compaction(文件合并)或在用户读取(Merge-on-Read)数据时,自动根据主键进行“列的组装”,最终对外呈现一张完整的宽表。
3. 解决多流乱序:Sequence Group(序列组)机制
在多流拼接中,由于各路数据流的生成、传输和处理延迟不同,极易出现乱序(Disorder)。传统的全局单一 sequence_field(如全局版本戳)无法解决该问题,因为 A 流可能因为带有较大的时间戳,而在合并时无意中覆盖或屏蔽掉 B 流较早但实际上有效的更新。
为了解决这个问题,Paimon 引入了 Sequence Group(序列组):
- 原理:将宽表的列划分为不同的“组”(每个组对应一个数据流要写入的列集合),并为每个组定义一个专属的序列字段(如事件时间)。
- 更新规则:只有当新数据的组对应序列值大于存储中的旧序列值时,该组关联的列才会被更新,各个组之间的更新独立对比、互不干扰。
序列组配置示例
CREATE TABLE t (
k INT,
a INT,
b INT,
g_1 INT, -- 组 1 的序列字段
c INT,
d INT,
g_2 INT, -- 组 2 的序列字段
PRIMARY KEY (k) NOT ENFORCED
) WITH (
'merge-engine' = 'partial-update',
'fields.g_1.sequence-group' = 'a,b', -- g_1 控制 a 和 b 列的更新
'fields.g_2.sequence-group' = 'c,d' -- g_2 控制 c 和 d 列的更新
);数据流动与更新痕迹分析(结合官方示例):
写入第 1 条数据:
INSERT INTO t VALUES (1, 1, 1, 1, 1, 1, 1);- 状态:
k=1, a=1, b=1, g_1=1, c=1, d=1, g_2=1
- 状态:
写入第 2 条数据(此时更新
a,b的值为 2,但g_2传入NULL表示 B 流此时无数据):INSERT INTO t VALUES (1, 2, 2, 2, 2, 2, CAST(NULL AS INT));- 结果:因为
g_2是NULL,组 2 (c,d) 被忽略不更新。g_1值为 2(大于旧值 1),所以组 1 (a,b) 成功更新。 - 状态:
k=1, a=2, b=2, g_1=2, c=1, d=1, g_2=1
- 结果:因为
写入第 3 条数据(发生乱序,传入较小的
g_1和更新的g_2):INSERT INTO t VALUES (1, 3, 3, 1, 3, 3, 3);- 结果:传入的
g_1为 1,小于已存储的g_1值 2,因此组 1 (a,b) 拒绝更新;而传入的g_2为 3,大于已存储的g_2值 1,因此组 2 (c,d) 更新为 3。 - 最终查询结果:
k=1, a=2, b=2, g_1=2, c=3, d=3, g_2=3
- 结果:传入的
注:序列组还支持*多列排序字段组合(复合版本),多字段会按顺序依次比较,如 'fields.g_2,g_3.sequence-group' = 'c,d'。*
4. 局部更新中的聚合支持(Aggregation For Partial Update)
若多流拼接时,某些列不仅需要更新,还需要进行累加、取最大值等聚合计算,Paimon 允许为局部更新的列指定聚合函数(如 sum, max, min 等)。
当引入聚合函数时,sequence-group 的机制会随之变化:
- 无聚合函数时:
sequence-group的序列字段作为版本过滤器(Version Filter),版本低的数据直接被丢弃。 - 有聚合函数时:
sequence-group的序列字段退化为排序键(Ordering Key)。任何带有非空序列值的数据,无论版本新旧,都会参与聚合计算,以此保证聚合数据的完整性。- 对于顺序无关的聚合(如
sum,max),输入顺序不影响最终结果。 - 对于顺序相关的聚合(如
last_non_null_value,first_value),该序列组的序列字段值将最终决定哪个数据应该作为“最后(最新)”或“最前(最旧)”的结果输出。
- 对于顺序无关的聚合(如
5. 拼接中的回撤与物理删除处理
多流拼接的数据源中(例如来自 CDC 产生的 -D 物理删除或 -U 回撤消息),通常需要对记录进行撤销。在 Partial-update 模式下,Paimon 提供了以下四种策略:
- 直接丢弃删除消息:配置
'ignore-delete' = 'true',系统将无视一切删除消息,保障已有数据不被破坏。 - 物理整行删除:配置
'partial-update.remove-record-on-delete' = 'true',一旦接收到-D(整行删除消息),则立刻从 Paimon 中彻底抹除这一整行数据。 - 序列组级别局部回撤(列回撤):通过定义
sequence-group,当接收到该流关联的-D数据时,只将其控制的列回撤重置为NULL,不影响其他流的数据。 - 特定序列组触发整行删除:配置
'partial-update.remove-record-on-sequence-group' = '<group-name>',只有当收到指定序列组的-D消息时,才允许物理删除整行。
6. 必不可少的 Changelog 产生配置
在实时湖仓架构中,拼接好的宽表往往需要被下游系统订阅消费。为了能够将拼接后的完整宽表变更流正常发送给下游,Partial-update 必须搭配特定的 Changelog Producer:
- 必须启用
lookup或full-compaction:因为写入时仅为局部列,Paimon 必须通过lookup机制(在写入时实时读取底层旧数据并合成)或者full-compaction机制(在 Compact 时合成)来产生包含完整-U和+U镜像的 Changelog。 - 如果误用默认的
none或者仅能返回输入本身的input模式,下游将无法收到拼接后的整行变更事件。