 播面
播面 Paimon 主键表支持哪几种合并引擎(Merge Engines)?
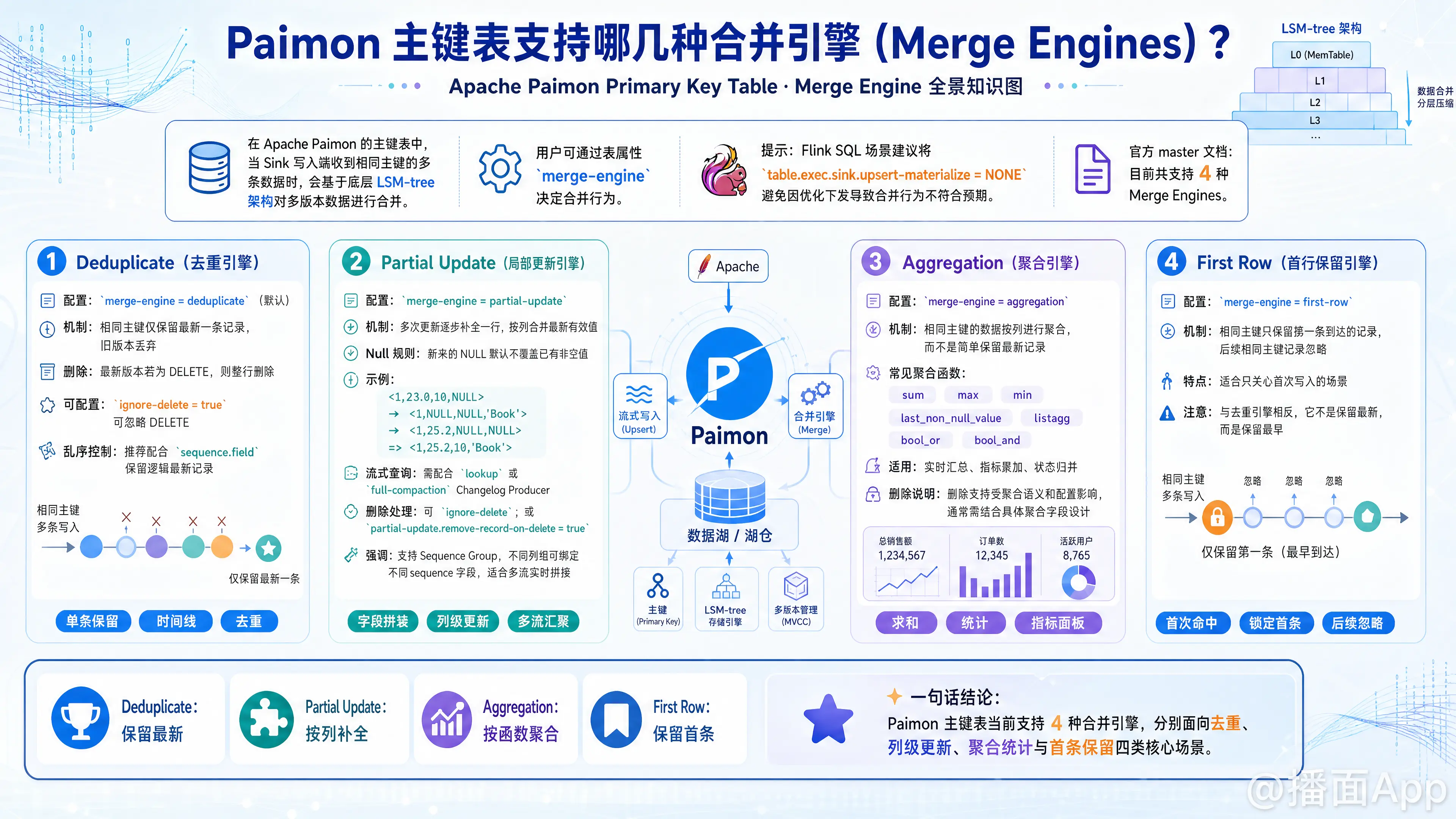
在 Apache Paimon 的主键(Primary Key)表结构中,当 Sink 写入端收到具有相同主键的多条数据时,Paimon 会通过底层 LSM-tree 架构对这些多版本数据进行合并。用户可以通过指定表属性 merge-engine 来决定数据合并的具体行为。
提示:官方在主键表的合并引擎介绍中特别强调,在使用 Flink SQL 时,建议将 TableConfig 中的
table.exec.sink.upsert-materialize设置为NONE,否则可能会由于 Flink 算子的下发优化导致产生不符合预期的合并行为。
根据 Paimon 官方 master 分支的最新文档,主键表目前支持以下 4 种 合并引擎(Merge Engines):
1. Deduplicate (去重引擎)
- 配置属性:
'merge-engine' = 'deduplicate'(默认值) - 核心机制:
- 这是 Paimon 的默认合并引擎。当相同主键的多条数据到达时,Paimon 仅保留最新一条记录,丢弃该主键下所有较旧的记录。
- 删除处理:
- 如果收到的最新版本是一条
DELETE消息,那么相同主键的整行数据都将被彻底删除。 - 可以通过配置
ignore-delete为true来忽略DELETE类型的输入。
- 如果收到的最新版本是一条
- 乱序控制:推荐配合
sequence.field(如更新时间戳或业务版本号),以确保在流式输入存在乱序的情况下依然能保留逻辑上最新的一条数据。
2. Partial Update (局部更新引擎)
- 配置属性:
'merge-engine' = 'partial-update' - 核心机制:
- 允许用户通过多次更新操作,逐步丰富、补充一条记录的各个列,最终形成一条完整的行记录。
- 它将相同主键下、最新的有效列数据合并覆盖到历史记录中。
- 空值(Null)处理:
- 默认情况下,新到达的
NULL值不会覆盖已存在的非空值。 - 示例:依次收到三条记录
<1, 23.0, 10, NULL><1, NULL, NULL, 'Book'><1, 25.2, NULL, NULL>,最终合并输出的结果是<1, 25.2, 10, 'Book'>。
- 默认情况下,新到达的
- 流式查询依赖:
- 在流式(Streaming)查询场景下,
partial-update必须配合lookup或full-compaction的 Changelog Producer 一起使用(如果使用input则只能返回输入的裸记录,无法保证流式回撤语义)。
- 在流式(Streaming)查询场景下,
- 删除处理:
- 由于局部更新只更新局部字段,默认情况下不接受整行删除消息。可使用以下几种变通方案:
- 配置
ignore-delete忽略删除消息; - 配置
partial-update.remove-record-on-delete = true,当收到DELETE记录时,直接物理移除整行记录; - 配置 Sequence Group 的撤回,或通过
partial-update.remove-record-on-sequence-group在指定 Sequence Group 收到删除记录时移除整行。
- 配置
- 由于局部更新只更新局部字段,默认情况下不接受整行删除消息。可使用以下几种变通方案:
- Sequence Group(序列组机制):
- 在多流实时拼接场景中,由于各业务流的进度和乱序情况不同,单一的全局
sequence-field可能会由于某个迟到流的值导致某些字段被错误覆盖。 - 通过定义 Sequence Group,可将不同的列划分为独立的列组,每个列组可以绑定专属的 sequence 字段进行多流独立比对,完美应对复杂的分布式乱序更新。
- 自 0.6.0 版本起,Sequence Group 中还支持定义局部字段的聚合函数。
- 在多流实时拼接场景中,由于各业务流的进度和乱序情况不同,单一的全局
3. Aggregation (聚合引擎)
- 配置属性:
'merge-engine' = 'aggregation' - 核心机制:
- 适用于用户仅关注聚合指标结果(如实时看板汇总、明细聚合)的场景。系统根据用户指定的聚合函数,逐个对相同主键下的非主键字段进行聚合计算。
- 指定聚合函数:
- 通过设置表属性
'fields.<field-name>.aggregate-function' = '<function_name>'为字段指定具体聚合逻辑。如果未显示指定,则默认使用last_non_null_value。
- 通过设置表属性
- 支持的聚合函数(部分核心示例):
sum(求和)、product(相乘)、count(计数)、max(最大值)、min(最小值);last_value/last_non_null_value/first_value/first_non_null_value(值选择);collect:将数据收集并拼接为ARRAY,支持通过'fields.<field_name>.distinct' = 'true'实现内部去重;merge_map:将输入的MAP字段进行合并;merge_map_with_keytime:通过MAP元素内部的时间戳对 Map 的 Key 级别数据进行局部更新,仅保留最新时间戳对应的值;nested_update/nested_partial_update:专门针对 Array 类型实现的嵌套表局部更新。
- 回撤支持(Retraction):
- 在处理流式撤回消息(如接收到
UPDATE_BEFORE或DELETE消息)时,只有部分聚合函数(如sum、product、count、collect、merge_map、nested_update、last_value和last_non_null_value)自带对撤回的天然支持。对于其他不支持回撤的函数,可以通过配置'fields.${field_name}.ignore-retract' = 'true'让其忽略撤回消息以避免计算报错。
- 在处理流式撤回消息(如接收到
4. First Row (首行引擎)
- 配置属性:
'merge-engine' = 'first-row' - 核心机制:
- 其行为与
deduplicate相反,该引擎仅保留主键下第一条(最先到达的)记录,并忽略后续所有具有相同主键的更新数据。
- 其行为与
- Changelog 优化优势:
- 在流式处理中,由于该引擎保证了“数据一经写入便永不更改”,Paimon 在对外生成 Changelog 时只会输出纯新增(Insert-only)的消息,无需生成成本昂贵的撤回(
-U/-D)消息。这对于下游也是流式处理的链路来说,能够成倍减少计算开销,通常被广泛应用于海量日志去重等特殊场景。
- 在流式处理中,由于该引擎保证了“数据一经写入便永不更改”,Paimon 在对外生成 Changelog 时只会输出纯新增(Insert-only)的消息,无需生成成本昂贵的撤回(
- 局限与依赖:
- 无法指定
sequence.field; - 不接受
DELETE和UPDATE_BEFORE类型的输入(如有需要,可以通过配置ignore-delete来直接忽略它们); - 流式查询时,必须配置并配合
lookup类型的 Changelog Producer 使用; - 可见性限制:由于 LSM 树的特定,在
first-row模式下,写入 Level 0 的文件数据只有在经过 Compaction(文件合并压缩)后才会对查询可见。
- 无法指定