 播面
播面 在 Paimon 中,对于数据量极其庞大、文件数过多的表,如何避免在 Coordinator(如 Flink JobManager 或 Spark Driver)中生成分片(Splits)而引发 OOM?
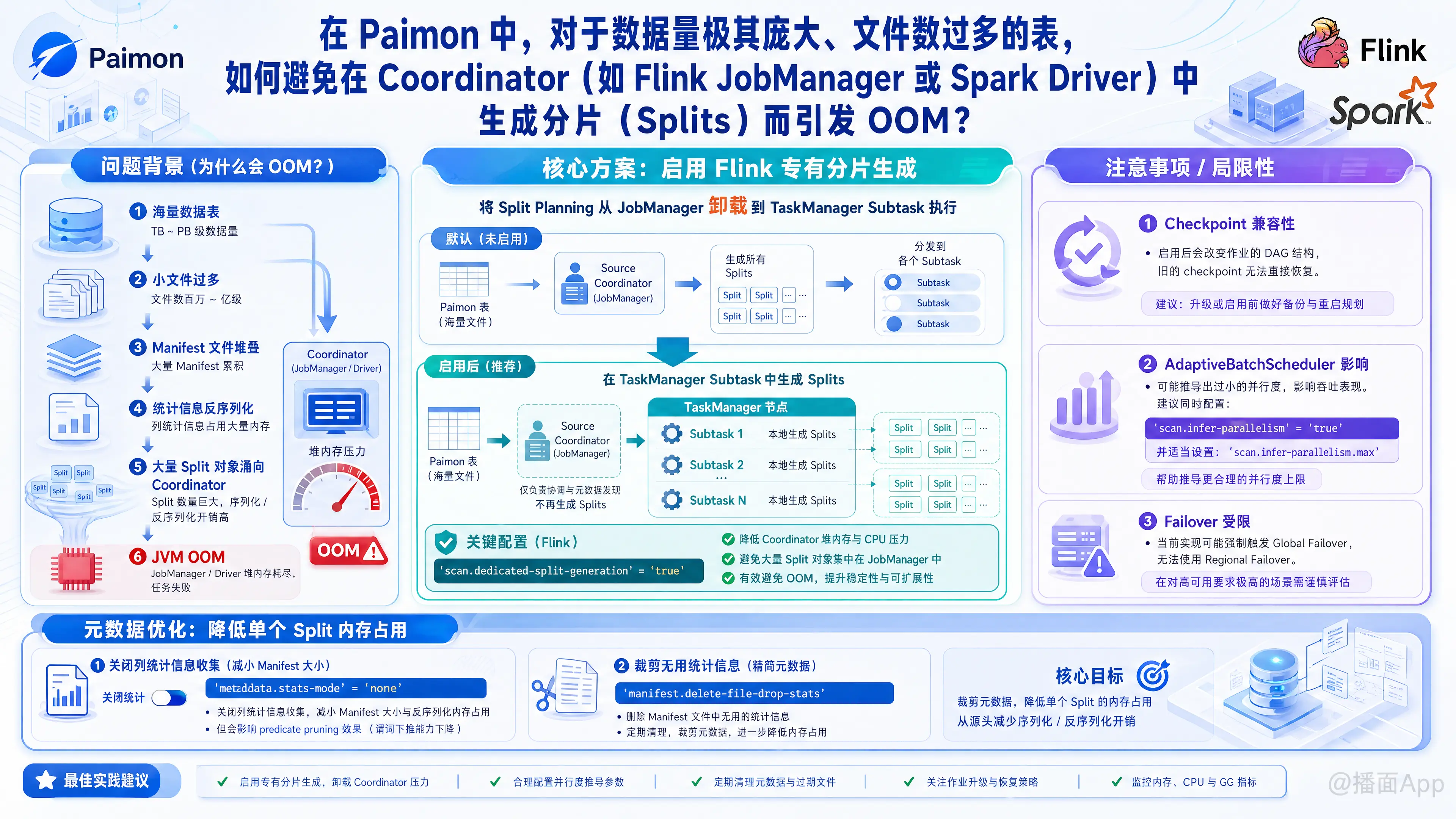
在 Apache Paimon 中,当表的数据量极其庞大且小文件过多时,Coordinator(如 Flink 的 JobManager 或 Spark 的 Driver)在任务初始化和分片规划(Split Planning)阶段,往往需要扫描大量的清单文件(Manifest)、反序列化统计信息并在内存中存储极其庞大的分片(Splits)对象。这极易导致 Coordinator 的内存被迅速耗尽,从而引发 JVM OOM。
根据 Paimon master 版本的官方文档,针对这一问题可以通过以下几种方式进行优化和避免:
一、 核心机制:启用 Flink 专有分片生成(Dedicated Split Generation)
对于 Flink 任务,Paimon 提供了一个专门的参数来解决 JobManager 端的 OOM 问题。
1. 配置参数
可以在 Paimon 的表属性(Table Properties)中配置如下参数:
'scan.dedicated-split-generation' = 'true'2. 工作原理
- 默认机制:在默认情况下(
false),Flink 任务在初始化阶段会将分片的扫描与生成工作放在 JobManager 的 Source Coordinator 中执行。 - 优化机制:当该参数配置为
true时,Paimon 会将分片生成过程移至运行在 TaskManager 上的专用子任务(Subtask)中进行,而不是在 JobManager 内存中处理。这实际上是将原本消耗 JobManager 堆内存和 CPU 的重度计算卸载到了 TaskManager 上,从而避免了 JobManager 的 OOM。
3. 局限性与注意事项
启用此功能虽能有效缓解 JobManager 的内存压力,但官方文档也指出它可能带来一些副作用:
- 破坏 Checkpoint 兼容性:它会改变 Flink 任务的 DAG(有向无环图)结构。如果在一个已存在并依赖 checkpoint 恢复的任务上开启此功能,将无法从原有的 checkpoint 直接恢复。
- 影响自适应批调度器(AdaptiveBatchScheduler):它可能导致 Flink 无法准确推导 Source Reader 算子的并行度,从而推导出一个非常小的并行度。
- 应对方案:建议同时显式配置
scan.infer-parallelism(设置为true并适当设置scan.infer-parallelism.max)来规避此问题。
- 应对方案:建议同时显式配置
- Failover 策略受限:由于专有的分片生成任务会与下游所有的 Subtask 相连,这会强制 Flink 任务的容错策略转为全局失败重启(Global Failover),而无法使用区域失败重启(Regional Failover)。
二、 元数据信息裁剪与优化(降低单个 Split 的内存占用)
当 Splits 数量无法减少时,可以通过裁剪 Splits 关联的元数据,降低单个分片在 Coordinator 内存中的空间占比。
1. 禁用或截断元数据统计信息收集(metadata.stats-mode)
默认情况下,Paimon 会在 Manifest 中收集列的 Null 计数、Min/Max 统计值(默认为 truncate(16))。在超大规模和宽表场景下,这些统计信息会占据巨大的内存空间。
- 建议配置:将该值设为sql
'metadata.stats-mode' = 'none'none可以彻底关闭元数据统计信息收集,能够大幅度减小 Manifest 的文件大小以及反序列化后的内存占用。但请注意,关闭后可能会影响查询时的预过滤(Push-down predicate pruning)效果。
2. 删除无用统计信息(manifest.delete-file-drop-stats)
在进行 Compaction 或删除文件时,如果依然保留无用历史文件的统计信息会浪费空间。
- 建议配置(Paimon 1.0+ 推荐,需确保所有读取端已升级):开启后,Paimon 将不再保留已删除文件的元数据统计信息,可进一步降低分片扫描和合并时的内存消耗。sql
'manifest.delete-file-drop-stats' = 'true'
三、 调整分片合并逻辑(减少 Splits 生成总量)
通过调整 Splits 的打包(Packing)逻辑,让多个小文件合并进更少的分片中,从源头上减少生成的 Splits 数量,进而降低 Coordinator 内存开销。
在 Flink 消费或批读取时,可通过以下参数控制打包行为:
source.split.target-size(默认 128 MB):控制单个 Source Split 的目标大小。可以适当调大该值,使更多的小数据文件合并成单个 Split 发送,从而减少 Splits 对象的整体数量。source.split.open-file-cost(默认 4 MB):代表打开一个文件的开销权重。调整该值可以间接优化小文件的分配逻辑,避免为过多的小文件生成过多的 Splits。
四、 结合引擎侧的通用优化手段
除了 Paimon 内部机制的调优,在 Spark 引擎或日常查询时,还应结合以下策略以防止 Coordinator OOM:
- 强制分区裁剪(Partition Pruning):
在 Spark SQL 或 Flink Batch 任务中,避免全表扫描。必须确保 SQL 查询中包含分区字段的过滤条件(如WHERE dt = '2026-05-22'),使 Coordinator 仅需要规划特定分区的 Splits,而不是加载整张表的 Manifest 历史数据。 - 增大 Coordinator 的 JVM 堆内存:
对于确实必须一次性读取超大规模文件的场景,如果上述参数优化后仍显吃力,需要适当增加 JobManager 堆内存(如设置 Flink 的jobmanager.memory.process.size)或 Spark Driver 内存(如设置spark.driver.memory)。