 播面
播面 Paimon 的 Manifest List 和 Manifest 文件中记录了哪些级别的统计指标(Stats)?读取时是如何利用这些指标在未接触真实数据文件前实现“分区裁剪”和“数据文件跳过(Data Skipping)”的?
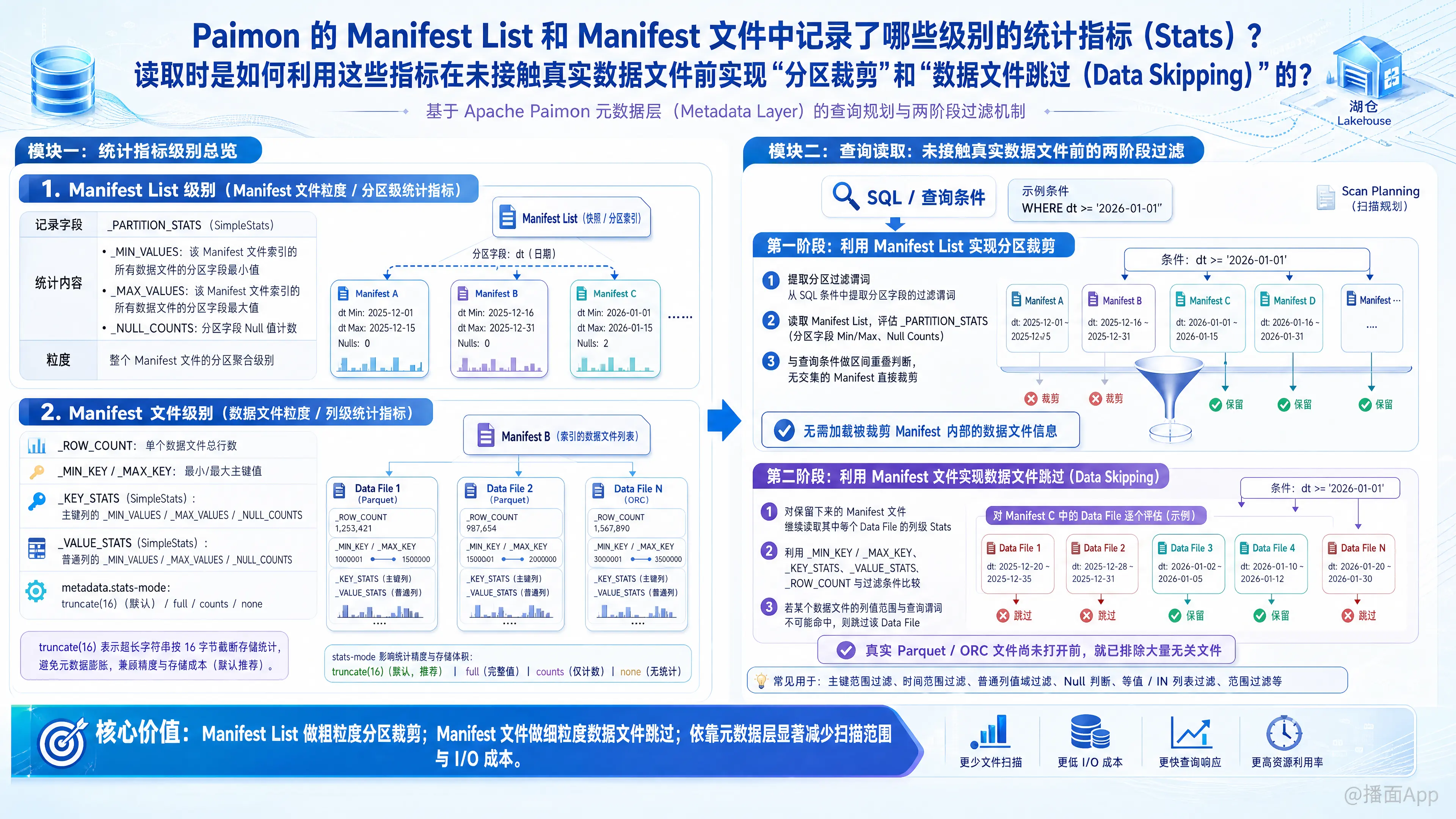
根据 Apache Paimon 的官方文档,其设计通过元数据层(Metadata Layer)在查询规划(Scan Planning)阶段进行快速的数据过滤。以下为您整理关于 Manifest List 和 Manifest 文件中记录的统计指标(Stats)级别,以及在读取时如何利用这些指标实现“分区裁剪”和“数据文件跳过(Data Skipping)”的具体实现机制:
一、 Manifest List 和 Manifest 文件中记录的统计指标级别
Paimon 在元数据层中,自上而下主要记录了以下两个级别的统计指标:
1. Manifest List 级别(Manifest 文件粒度 / 分区级统计指标)
Manifest List 记录了该 Snapshot 包含的所有 Manifest 文件的元数据。在此级别,它记录了分区字段的聚合统计信息:
- 记录字段:
_PARTITION_STATS(类型为SimpleStats)。 - 统计内容:
_MIN_VALUES:该 Manifest 文件中所索引的所有数据文件的分区字段最小值。_MAX_VALUES:该 Manifest 文件中所索引的所有数据文件的分区字段最大值。_NULL_COUNTS:该 Manifest 文件中分区字段的 Null 值计数。
- 粒度:针对整个 Manifest 文件的分区聚合级别。
2. Manifest 文件级别(数据文件粒度 / 列级统计指标)
Manifest 文件记录了具体数据文件(Data File)的元数据(在 Schema 中的 _FILE 结构内)。在此级别,它记录了具体到单个数据文件内的字段统计信息:
- 行数统计:
_ROW_COUNT(记录单个数据文件的总行数)。 - 主键统计:
_MIN_KEY/_MAX_KEY(该数据文件的最小/最大主键值)。 - 列级 Stats(主键列):
_KEY_STATS(类型为SimpleStats,记录主键各列的_MIN_VALUES、_MAX_VALUES和_NULL_COUNTS)。 - 列级 Stats(普通列):
_VALUE_STATS(类型为SimpleStats,记录非主键列/常规列的_MIN_VALUES、_MAX_VALUES和_NULL_COUNTS)。 - 配置说明:数据文件的列级统计模式可以通过
metadata.stats-mode进行配置(默认模式为truncate(16),即对超过 16 字节的字符串列进行阶段截断以防止元数据文件过度膨胀;亦可配置为full完整记录、counts仅记录 Null 计数或none禁用收集)。
二、 读取时如何利用统计指标实现过滤
在读取数据时,Paimon 的查询引擎(Scan Planning 阶段)无需接触真实的底层数据文件(如 Parquet 或 ORC),即可自上而下通过元数据进行两阶段的过滤:
第一阶段:利用 Manifest List 实现“分区裁剪”
- 提取查询条件:当用户提交查询时,Paimon 会解析 SQL 中的分区过滤谓词(例如
WHERE dt >= '2026-01-01')。 - 评估 Manifest 范围:Paimon 读取当前的 Manifest List,并将查询中的分区条件与每个 Manifest 记录的
_PARTITION_STATS(分区字段的 Min/Max 区间)进行重叠比较。 - 裁剪无效 Manifest:如果某个 Manifest 文件所覆盖的分区区间与查询条件完全没有交集,该 Manifest 文件将直接被过滤掉,其内部记录的所有数据文件信息均不会被加载。此步骤在大粒度上实现了分区裁剪。
第二阶段:利用 Manifest 文件实现“数据文件跳过(Data Skipping)”
- 解析候选文件元数据:对于未能被裁剪的 Manifest 文件,Paimon 会读取其内容,提取其中记录的数据文件元数据(
_FILE)。 - 匹配列级统计指标:针对查询条件中的非分区字段过滤谓词(例如
WHERE price > 100),Paimon 会将其与每个数据文件对应的_KEY_STATS或_VALUE_STATS进行匹配。- 支持的加速算子:包括
=,<,<=,>,>=,IN,LIKE 'abc%',IS NULL等常见过滤操作。 - 匹配逻辑:如果该查询条件所需的区间与该数据文件记录的 Min/Max 区间没有重合(或者不满足 Null 值判定),则该数据文件会被排除。
- 支持的加速算子:包括
- 生成读取分片(Splits):只有最终通过了这一层过滤的数据文件,才会被作为候选分片(Splits)传递给计算引擎,并触发实际的文件读取 I/O 动作。
总结
通过在 Manifest List(分区级统计) 和 Manifest(数据文件列级统计) 中建立的分层统计索引,Paimon 能够在查询规划期仅通过对少量轻量级元数据文件的读取和求值,便将不相关的数据排除在读取范围之外。这种“在未接触真实数据文件前”的提前过滤,大幅减少了不必要的分布式文件系统 I/O(如 NameNode 交互和数据块读取),从而优化了整体的查询性能。