 播面
播面 Paimon 是如何结合 Flink 的 Checkpoint 机制实现端到端 Exactly-Once 语义的?
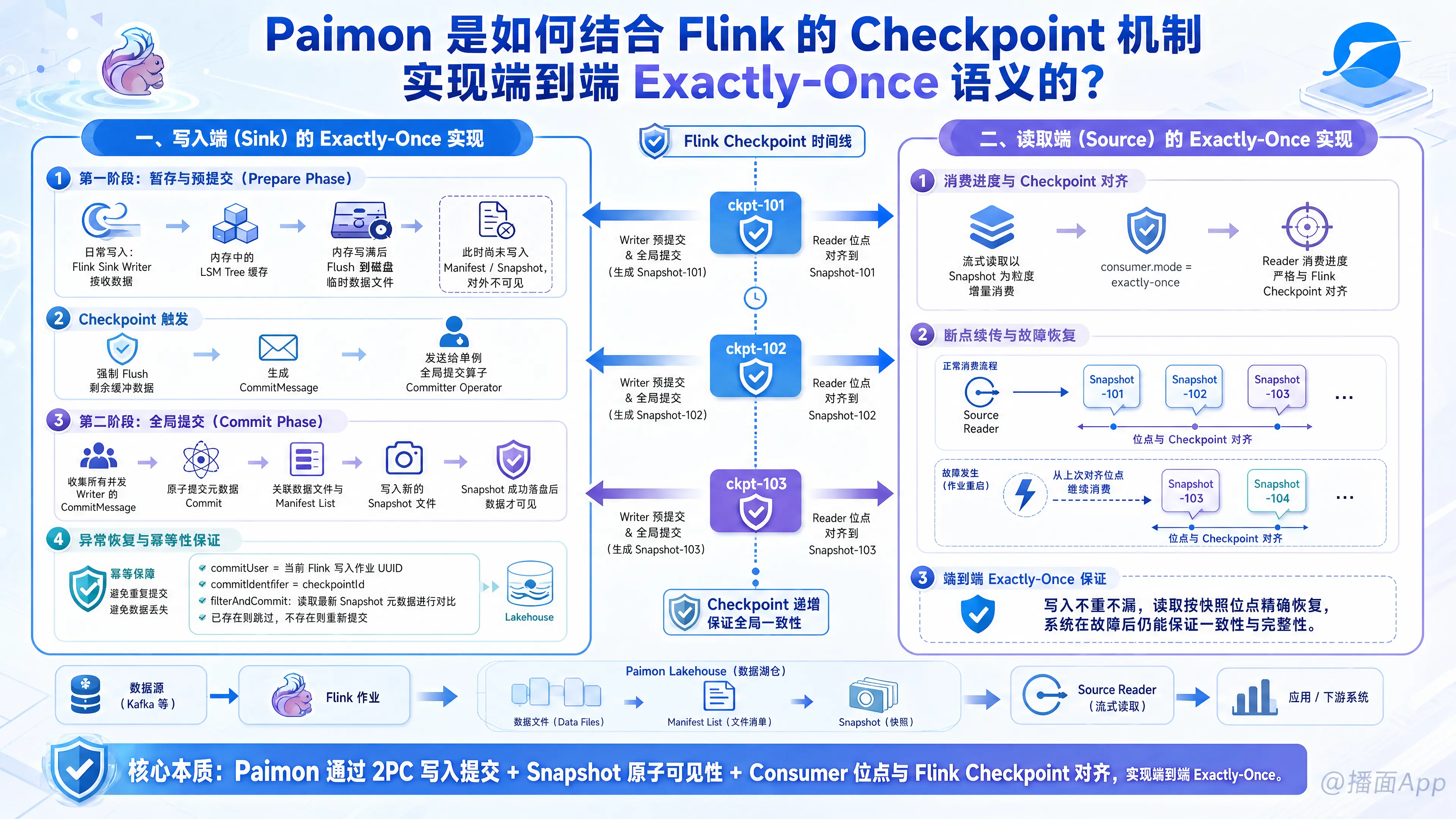
根据 Apache Paimon 官方文档,Paimon 结合 Flink 的 Checkpoint 机制来实现端到端 Exactly-Once 语义,主要依赖其基于两阶段提交(Two-Phase Commit, 2PC)的写入机制以及针对读取端的消费位点对齐机制。
具体的实现机制可以从写入端(Sink)和读取端(Source)两个维度进行总结:
一、 写入端(Sink)的 Exactly-Once 实现
Paimon 在写入时将处理过程分为数据写入与元数据提交两个阶段,并借由 Flink 的 Checkpoint 机制进行分布式协调:
第一阶段:暂存与预提交(Prepare Phase)
- 日常写入: 在 Flink 作业运行期间,Paimon Sink 算子(Writer Tasks)接收数据并缓存在内存的 LSM 树结构中。当内存写满时,数据会被刷写(Flush)到磁盘的临时数据文件中,但此时尚未写入 Manifest(元数据清单)和 Snapshot(快照),因此对外部用户是不可见的。
- Checkpoint 触发: 当 Flink 触发 Checkpoint 时,Sink 算子会强制将内存中剩余的缓冲数据全部 Flush 到磁盘。随后,Sink 算子会生成包含新写入文件信息的
CommitMessage(提交消息),并作为 committable 发送给下游的单例全局提交算子Committer Operator。
第二阶段:全局提交(Commit Phase)
- 快照创建:
Committer Operator在 Flink 的 Checkpoint 完成阶段,收集来自所有并发 Sink 算子的CommitMessage。它会执行一次原子的元数据提交(Commit),将数据文件与清单列表(Manifest List)进行关联,并写入一个新的 Snapshot 文件。 - 可见性: 只有当 Snapshot 文件成功写入 DFS 存储后,本次 Checkpoint 范围内写入的数据才正式对外界可见。
- 快照创建:
异常恢复与幂等性保证(故障恢复机制)
为应对 Flink 作业故障并保证Exactly-Once,Paimon 引入了两个核心标识:commitUser:通常是一个 UUID,代表当前的 Flink 写入作业。一个流作业对应一个唯一的commitUser。commitIdentifier:对应 Flink 的checkpointId,随着 Checkpoint 的递增而单调递增。- 冲突过滤(
filterAndCommit):如果在提交过程中 Flink 作业发生故障并尝试从上一次 Checkpoint 恢复,新拉起的全局提交算子无法确定前一次 Checkpoint 的CommitMessage是否已经真正提交到了文件系统。此时,Paimon 会读取存储介质中最新的 Snapshot 元数据,并通过filterAndCommit方法对比commitUser与commitIdentifier。若发现该checkpointId的 Snapshot 已经存在,则会自动跳过该批数据的重复提交;若不存在,则重新提交,从而避免了数据的重复或丢失。
二、 读取端(Source)的 Exactly-Once 实现
为了保证在流式消费 Paimon 表时能够实现 Exactly-Once(如“断点续传”),Paimon 提供了 Consumer ID 机制:
- 消费进度与 Checkpoint 对齐
- 在流式读取 Paimon 表时,Paimon 会以快照(Snapshot)为粒度进行增量消费。
- 在默认的
consumer.mode=exactly-once模式下,读取端(Reader)的消费进度严格与 Flink 的 Checkpoint 进行对齐。
- 状态持久化与断点续传
- Flink Checkpoint 触发时,Paimon Source 会将当前消费到的 Snapshot ID 记录到 Flink 的状态(State)中。
- 同时,Paimon 还可以通过
consumer-id选项将当前消费的 Snapshot 进度持久化记录在文件系统(DFS)中。这确保了当 Flink 作业由于非正常原因停止或升级重新启动时,即使不从 Flink State 恢复,也可以通过读取文件系统中的 Consumer 文件自动定位到上一次成功消费的 Snapshot ID + 1 位置继续读取,确保数据不重不漏。