 播面
播面 Paimon固定桶(Fixed Bucket)与动态桶(Dynamic Bucket)
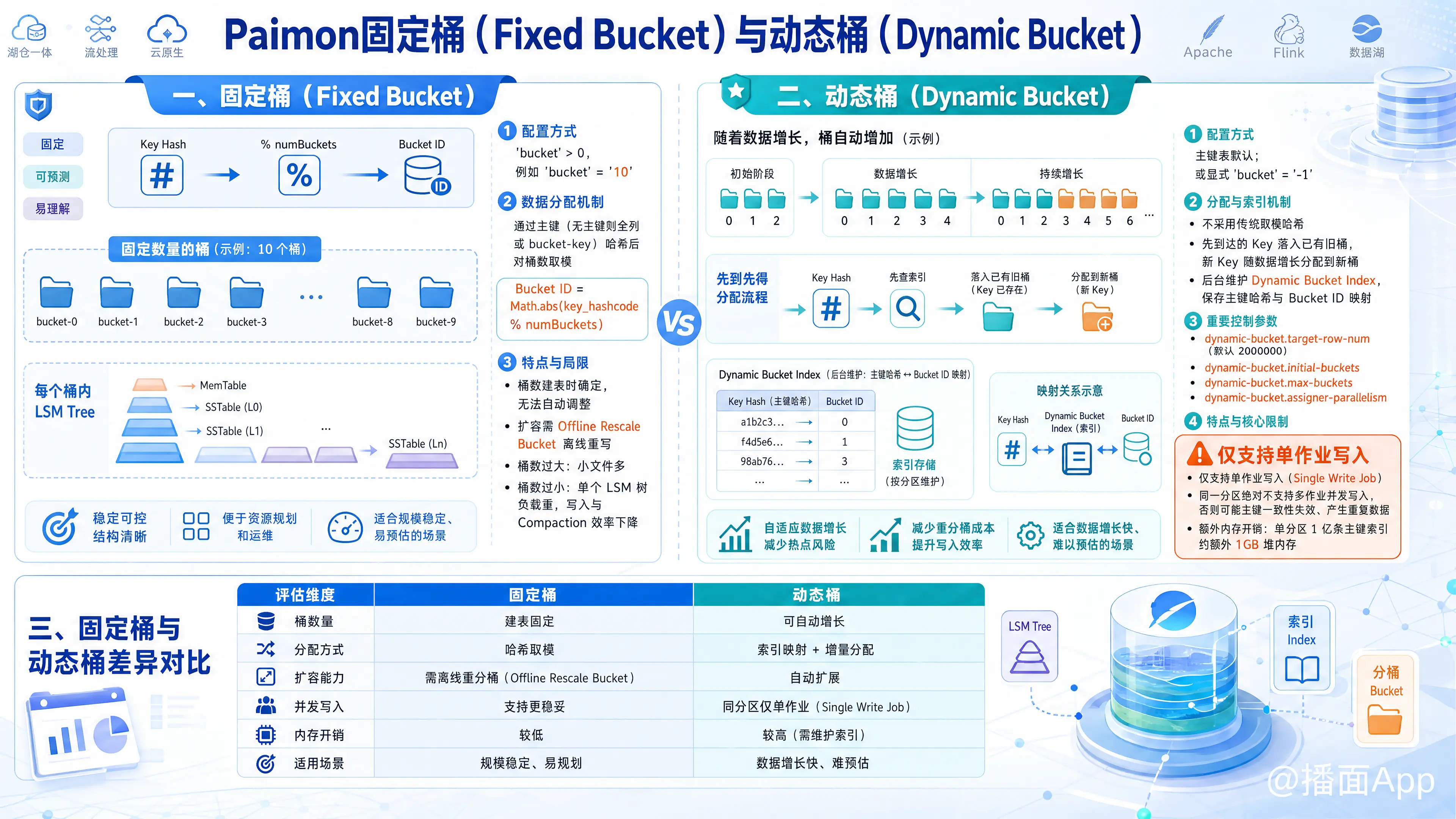
在 Apache Paimon 中,Bucket(桶) 是数据读写的最小存储单元,每个 Bucket 目录在底层都是一个独立的 LSM 树存储结构。Paimon 提供了 固定桶(Fixed Bucket) 和 动态桶(Dynamic Bucket) 两种数据分布模式,它们的特性与适用场景总结如下:
一、 固定桶(Fixed Bucket)
固定桶模式是传统的散列分桶方式,桶的数量在建表时必须显式指定。
- 配置方式:
将表参数'bucket'设置为大于 0 的正整数(例如'bucket' = '10')。 - 数据分配机制:
Paimon 通过计算主键(若无主键则使用全部列或指定的bucket-key)的哈希值对桶数进行取模运算,决定数据落入哪个 Bucket: - 特点与局限:
- 扩容受限:桶的数量一旦确定,无法自动调整。后期如需扩容(Rescale),必须通过离线作业(Offline Rescale Bucket)进行重分区重写。
- 调优难度大:在生产中,规划桶的数量较难。如果桶数配置过大,会导致产生大量小文件;若桶数配置过小,会导致单个 LSM 树负载过重,降低数据的写入与 Compaction 效率。
二、 动态桶(Dynamic Bucket)
动态桶模式是 Paimon 主键表(Primary Key Table)的默认分桶模式。该模式下,Bucket 的数量可以随着数据量的增长而自动扩展,免去了人工规划桶数的烦恼。
- 配置方式:
主键表默认即为动态桶模式,或者可显式在表参数中配置'bucket' = '-1'。 - 数据分配与索引机制:
- 动态桶不采用传统的取模哈希。数据采用“先到先得”的原则:先到达的数据 Key 会落入已有的旧桶,新产生的 Key 则会随着数据量扩充分配到自动生成的新桶中。
- 为确保相同主键(Key)在多次更新或不同流中被正确路由到同一个 Bucket,Paimon 会在后台维护一个 Dynamic Bucket Index(动态桶索引)。该索引存储了主键哈希值与 Bucket ID 之间的映射关系。
- 重要控制参数:
dynamic-bucket.target-row-num(默认 2000000 / 200 万行):控制单个 Bucket 期望承载的目标最大记录数,当数据超过此值时会尝试分裂产生新桶。dynamic-bucket.initial-buckets:指定单个分区的初始 Bucket 数量。dynamic-bucket.max-buckets:限制单个分区的最大 Bucket 数量上限,防止极端情况下由于主键数量庞大而无限产生 Bucket 导致小文件失控。dynamic-bucket.assigner-parallelism:动态桶分配器(Assigner)的算子并发度。
- 特点与核心限制:
- ⚠️ 仅支持单作业写入(Single Write Job):动态桶模式在写同一个分区时绝对不支持多作业并发写入。如果有多个并发写入作业,各作业由于本地状态和索引无法同步,可能会分配出不同的 Bucket,进而导致主键一致性失效(产生重复数据)。
- 额外的内存开销:在更新不跨分区(主键包含了全部的分区字段或表无分区)的情况下,Paimon 通过 HASH 索引维护内存映射,相比固定桶会消耗更多内存。根据官方估算,单分区内 1 亿条主键索引大约会占用额外 1 GB 的堆内存(但已经不再活跃的历史分区不占用常驻内存)。
三、 固定桶与动态桶差异对比
| 评估维度 | 固定桶(Fixed Bucket) | 动态桶(Dynamic Bucket) |
|---|---|---|
| 配置参数 | bucket 为正整数(如 10) |
bucket = -1(主键表默认) |
| 桶数量计算 | Math.abs(hashcode % numBuckets) |
基于物理行数触发动态扩张与动态索引映射 |
| 多作业写入支持 | 支持多流/多作业并发写入同一个分区 | 不支持。仅支持单流/单作业写入同一分区 |
| 后期扩容难度 | 需借助离线 Rescale Bucket 任务重新分布数据 | 随行数增多自动新增 Bucket,无需人工介入 |
| 内存开销 | 极低 | 相对较高(1 亿条主键约占用 1 GB 额外内存) |
| 适用场景 | 1. 批量重写、大吞吐且明确数据量上限的场景 2. 必须进行多作业多流并发写入同一分区的场景 |
1. 主键表低更新率、数据规模逐步增长的场景 2. 无法提前估算每日数据量的实时/CDC 摄入场景 |