 播面
播面 Paimon的三种changelog-producer模式(input、lookup、full-compaction )
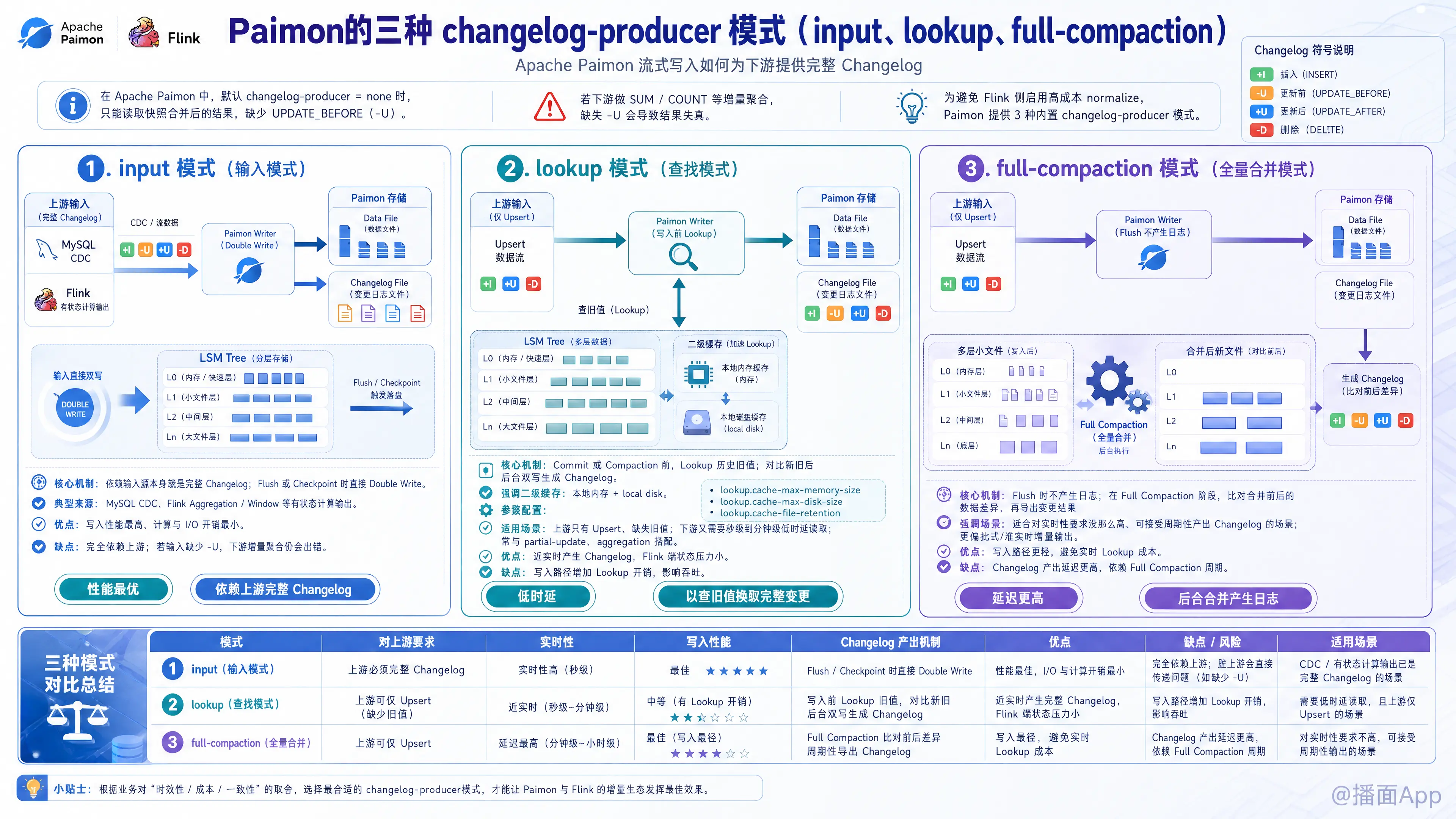
在 Apache Paimon 中,流式写入可以持续为下游流式读取提供增量变更数据(Changelog)。
默认情况下(即 changelog-producer = none),Paimon 仅能提供快照合并后的变化,无法读取到主键的更新前旧值(UPDATE_BEFORE,即 -U)。如果下游消费者需要进行增量聚合(如 SUM、COUNT),缺失 -U 消息会导致计算结果失真。为了解决该问题且避免 Flink 侧启用高昂的 normalize 状态算子,Paimon 提供了以下三种内置的 changelog-producer(Changelog 产生器)模式:
1. input 模式 (输入模式)
- 工作机制:
Paimon 的写入端(Writer)直接依赖输入数据源本身作为完整的 Changelog。当内存数据缓冲区满或 Flink 触发 Checkpoint 进行 Flush 刷盘时,Writer 会直接将输入记录双写(Double Write)到专门的 Changelog 文件中,并由 Paimon Source 直接提供给下游消费者。 - 适用场景:
适用于输入源本身就已经具备完整、正确 Changelog 属性的场景。- 典型例子:来自数据库 CDC(如 MySQL CDC)的数据,或者是由 Flink 有状态计算(如 Flink Aggregation、Window)产生并输出的数据,这类数据自身已携带有完整的
INSERT、UPDATE_BEFORE、UPDATE_AFTER、DELETE操作符。
- 典型例子:来自数据库 CDC(如 MySQL CDC)的数据,或者是由 Flink 有状态计算(如 Flink Aggregation、Window)产生并输出的数据,这类数据自身已携带有完整的
- 优缺点:
- 优点:写入性能极高,平摊的计算和 I/O 开销最小,是性能上最优的选择。
- 缺点:完全信赖上游数据。如果输入数据源本身不是完整的 Changelog(例如缺失
-U),下游做增量聚合计算时仍会出错。
2. lookup 模式 (查找模式)
- 工作机制:
当输入源无法提供完整的 Changelog 时,lookup模式可在不引入 Flink Normalize 算子的情况下生成 Changelog。
Paimon 会在提交数据写入(Commit)或合并(Compaction)前,通过点查(Lookup)底层的 LSM 树或本地缓存(利用本地内存与 local disk 构建二级索引),寻找该主键对应的历史旧值。通过将新写入的值与获取的历史值进行比对,在后台双写生成对应的-U和+U变更记录。 - 相关性能参数:
Lookup 过程支持将数据缓存在内存和本地磁盘中。你可以通过以下参数进行性能调优:lookup.cache-max-memory-size:本地 Lookup 缓存的最大内存大小。lookup.cache-max-disk-size:本地缓存的最大磁盘使用空间限制。lookup.cache-file-retention:缓存文件的过期保留时间。
- 适用场景:
适用于上游不是完整 Changelog(只有 Upsert 数据,缺失旧值),但下游需要低时延(秒级到分钟级)读取,且无法接受 Flinknormalize算子高昂状态成本的场景。常与partial-update(部分更新)或aggregation(聚合)等合并引擎联用。 - 优缺点:
- 优点:时效性高(近实时产生),Flink 端的资源和状态托管负担小。
- 缺点:点查逻辑会在写入路径上引入额外的磁盘或内存 Lookup 开销,对写入吞吐量会有一定影响。
3. full-compaction 模式 (全量合并模式)
- 工作机制:
在正常刷写数据落盘(Flush)时,Writer 不会产生 Changelog。而是在后台触发 Full Compaction(全量合并) 时,通过比对合并前后的数据差异,产生并导出差异部分的 Changelog 文件。
其产生 Changelog 的频次和延迟主要取决于 Full Compaction 的触发间隔,可通过表属性full-compaction.delta-commits(指定触发 Full Compaction 的增量提交次数)等参数来微调。 - 适用场景:
适用于对流式消费延迟要求较低(如 10 分钟、30 分钟或更长时延),但要求Changelog 数据最纯净(完全去重、无中间临时状态)的业务场景。可以支持任何类型的输入源。 - 优缺点:
- 优点:在平时的正常写入落盘阶段没有 Lookup 的点查开销,产生的 Changelog 是完全合并后的最终增量状态,最为精准。
- 缺点:延迟非常高,无法做到秒级的流式消费;且 Full Compaction 本身属于重度 I/O 操作,会对系统瞬时资源产生一定消耗。
核心对比总结
| 维度 | input 模式 |
lookup 模式 |
full-compaction 模式 |
|---|---|---|---|
| 数据源要求 | 必须是完整、合法的 Changelog 数据 | 任意类型的输入源(通常为非完整数据) | 任意类型的输入源(通常为非完整数据) |
| 生成时机 | 数据 Flush 刷盘落盘时 | 数据提交/合并前的 Lookup 阶段 | 后台异步执行 Full Compaction 时 |
| 时效性/延迟 | 极低(秒级,取决于 Checkpoint 间隔) | 较低(近实时,取决于 Checkpoint 间隔) | 较高(取决于全量合并触发频率,如10~30分钟) |
| 写入性能影响 | 极低(仅增加双写 Changelog 文件成本) | 中(需在内存/本地磁盘中查询历史数据) | 平时无影响,全量合并触发时消耗一定磁盘/算力资源 |
| 下游聚合支持 | 依赖上游提供 -U |
完美支持,且可配置 row-deduplicate 去重 |
完美支持,且可配置 row-deduplicate 去重 |