 播面
播面 讲讲Paimon读数据的详解流程
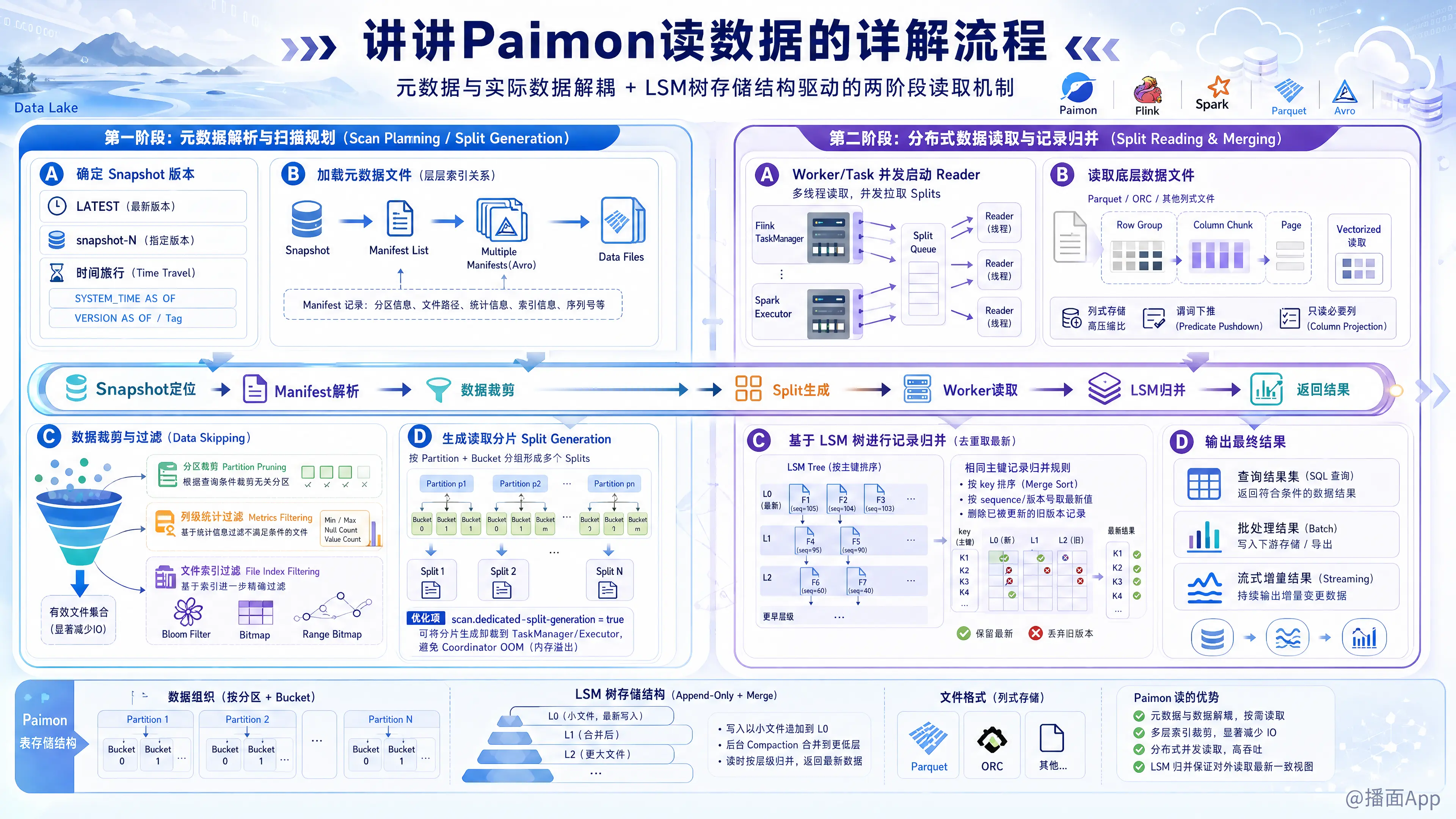
在 Apache Paimon 中,读数据的流程同样秉承了数据湖格式“元数据与实际数据解耦”的原则,并深度结合了其底层的 LSM 树存储结构。
Paimon 的数据读取流程主要可以分为两个阶段:第一阶段:元数据解析与扫描规划(Scan Planning / Split Generation),通常在计算引擎的协调节点(Coordinator/Driver)上执行;第二阶段:分布式数据读取与记录归并(Split Reading & Merging),在分布式计算节点的任务实例(Workers/Tasks)上并发执行。
第一阶段:元数据解析与扫描规划(Scan Planning)
此阶段的目标是在不触及底层巨大数据文件的情况下,仅通过轻量级的元数据解析,快速剔除不相关的数据(Data Skipping),并把需要读取的文件划分为多个逻辑读取任务(Splits)。
1. 确定 Snapshot 版本
- 默认情况:Reader 会定位最新的快照(从
LATEST提示文件或扫描snapshot目录获取最新的snapshot-NJSON 文件),返回当前表最新状态的数据。 - 时间旅行(Time Travel):如果用户指定了特定的时间戳、Snapshot ID 或 Tag(例如 Flink 的
FOR SYSTEM_TIME AS OF或 Spark 的VERSION AS OF),Reader 会定位并加载对应的历史快照元数据。
2. 加载元数据文件(Manifest List & Manifests)
- 读取并解析当前 Snapshot 关联的 Manifest List(元数据清单列表)。
- 进一步加载 Manifest List 指向的多个 Manifest 文件(Avro 格式),这些文件中记录了所有底层数据物理文件(Data File)的路径、所属分区、统计指标(Metrics)等信息。
3. 数据裁剪与过滤(Pruning & Data Skipping)
- 分区裁剪(Partition Pruning):根据查询条件中的分区过滤条件(如
WHERE dt > '2026-05-01'),直接过滤掉不匹配的分区目录。 - 列级统计过滤(Metrics Filtering):Manifest 中记录了每个文件的列级统计信息(如最小值 Min、最大值 Max、空值个数 Null Count)。若查询条件不落在文件的 Min-Max 范围内,则直接排除该文件。
- 文件索引过滤(File Index Filtering):若配置并生成了 Bloom Filter、Bitmap 或 Range Bitmap 等文件索引,Paimon 还会利用这些索引在元数据层排除不含目标主键/过滤键的文件。
4. 生成读取分片(Split Generation)
- 将通过过滤的活跃数据文件按 Partition 和 Bucket 分组,划分为一个个逻辑读取单元 —— Split(分片)。
- 分片生成优化(Dedicated Split Generation):如果表的 Split 数量极其庞大,在 Coordinator 内存中生成可能会导致 JVM 内存溢出(OOM)。Paimon 支持开启
scan.dedicated-split-generation=true,将分片生成计算过程卸载(Offload)到 TaskManager/Executor 上执行,避免 coordinator 的单点瓶颈。
第二阶段:分布式数据读取与记录归并(Split Reading)
一旦分片(Splits)被下发给分布式的 Worker(如 Flink TaskManager、Spark Executor),各个 Worker 启动 Paimon SDK 内置的 Reader 开始进行物理读取。
1. 多线程并发读取
- 各个 Worker 启动
RecordReader(针对 Parquet/ORC/Avro 格式的文件读取器),并发读取物理 Data File。
2. 主键表的记录重构与归并(LSM Tree Merging - 核心机制)
对于定义了主键的表(Primary Key Table),由于 LSM 树在不同层级的 Sorted Run 间可能存在更新和删除的历史记录,Reader 必须在读取时进行数据合并。根据表的不同更新模式,合并策略有所不同:
- 读时合并(Merge On Read - MOR 模式,默认):
- Reader 必须同时打开当前 Split 内所有相关的 Sorted Run 文件。
- 在内存中执行 「多路归并排序(Multi-way Merge Sort)」。
- 根据表配置的 Merge Engine(如
Deduplicate去重、Partial Update局部更新、Aggregation聚合等)对相同主键的记录进行计算,只向计算引擎返回最新的最终状态行。
- 标记删除模式(Merge On Write - MOW 模式,启用 Deletion Vectors):
- 在此模式下,Reader 无需在读取时做复杂的内存多路归并。
- Reader 会在读取 Data File 的同时,加载关联的 Deletion Vector(删除向量)文件,根据 Deletion Vector 记录的物理行索引直接过滤掉失效的行。这大大降低了多路比较的 CPU 消耗。
- 读优化系统表(Read-Optimized System Table):
- 若用户查询的是
my_table$ro这种只读优化系统表,Reader 仅会扫描 LSM 树顶层(已经完成 Full Compaction、不再需要 Merge 的文件),完全跳过内存合并逻辑。
- 若用户查询的是
3. 无主键表的直接读取(Append-Only Table)
- 对于无主键的追加表,读取不涉及 LSM 归并逻辑。Reader 只需要并行扫描物理 Data File,并将结果直接投递给下游,此过程完美支持计算引擎的投影下推(Projection Pushdown)和谓词下推(Predicate Pushdown)。
针对流式读取(Streaming Read)的增量循环机制
如果将 Paimon 视作流式源(Streaming Source),其读取流程将变为一个无界监听的循环:
- 定位初始 Snapshot:根据流式扫描模式(如
latest:仅消费启动后的新数据;latest-full:先读取最新完整快照作为初始状态,再增量消费等)定位增量消费的起点。 - 后台增量监听(Incremental Scan Loop):
- 协调器(Coordinator)会在后台定时轮询 Paimon 的元数据,检测是否有新 Snapshot 产生。
- 差异分析与分片派发:
- Changelog 消费:如果表配置了 Changelog Producer(如
lookup或full-compaction等),Paimon 会直接定位并读取新增 Snapshot 关联的 Changelog 文件,将其作为流式 Split 发送给 Reader。 - 无 Changelog 消费:若未生成 Changelog 文件,Paimon 将回退到对比新旧 Snapshot 之间新增的 Data Files 来分析出增量变化。
- Changelog 消费:如果表配置了 Changelog Producer(如
- 顺序保证(Ordering):
- 为保证流式处理的正确性,Paimon 增量下发分片时会按照分区时间顺序、以及单个 Bucket 内文件的写入先后顺序进行下发(保证单个 Bucket 内部数据“先写先读”的局部保序)。