 播面
播面 Flink自定义Connector的开发步骤流程
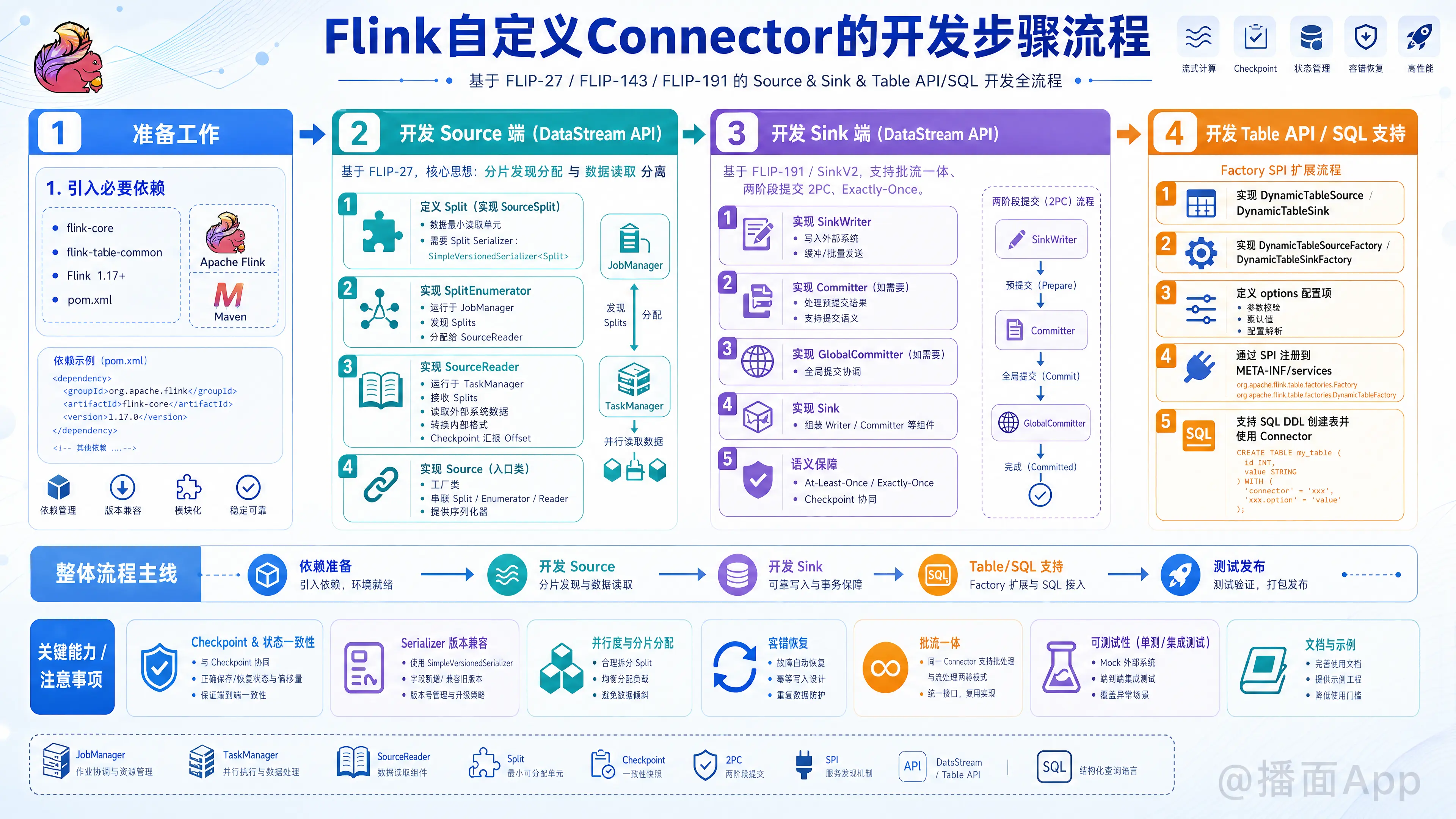
在Apache Flink中开发自定义Connector(连接器)是一个结构化的过程。自Flink 1.11和1.12版本引入了全新的Source API (FLIP-27) 和 Sink API (FLIP-143/FLIP-191) 以后,开发流程变得更加模块化,并能更好地支持精确一次(Exactly-Once)语义、批流一体以及发现分片等高级特性。
以下是开发一个完整 Flink 自定义 Connector(包含 DataStream API 和 Table API/SQL 支持)的标准步骤流程:
第一阶段:准备工作
1. 引入必要的依赖
在你的 pom.xml 中引入 Flink 核心依赖和 Table API 依赖(以 Flink 1.17+ 为例):
<dependencies>
<!-- Flink Core -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- 如果需要支持 Flink SQL / Table API -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>第二阶段:开发 Source 端 (DataStream API)
基于 FLIP-27 架构,核心思想是将“分片发现分配”与“数据读取”分离。
1. 定义 Split (数据分片)
- 实现
SourceSplit接口。 - 作用: 定义数据的最小读取单元(例如:Kafka的一个Partition,或者文件系统中的一个文件/文件块)。
- 伴生类: 需要同时实现
SimpleVersionedSerializer<YourSplit>用于在 Checkpoint 时序列化保存 Split 状态。
2. 实现 SplitEnumerator (分片枚举器)
- 实现
SplitEnumerator接口。 - 运行位置: JobManager (单例运行)。
- 作用: 负责发现数据源中的 Splits(如定期轮询发现新文件/新分区),并将 Splits 分配给下游的 SourceReader。
3. 实现 SourceReader (数据读取器)
- 实现
SourceReader接口(通常继承SourceReaderBase可减少工作量)。 - 运行位置: TaskManager (并行运行)。
- 作用: 接收来自 SplitEnumerator 分配的 Splits,连接外部系统读取数据,并将数据转换为 Flink 的内部格式输出。负责处理 Checkpoint 时汇报当前读取的 Offset。
4. 实现 Source (入口类)
- 实现
Source接口。 - 作用: 这是一个工厂类,负责把上面三个组件(Split, Enumerator, Reader)串联起来,并提供它们的序列化器。
第三阶段:开发 Sink 端 (DataStream API)
基于 FLIP-191 (SinkV2) 架构,支持批流一体和两阶段提交 (2PC)。
1. 实现 SinkWriter (写入器)
- 实现
SinkWriter接口。 - 运行位置: TaskManager (并行运行)。
- 作用: 接收上游数据并写入外部系统。
- 注意: 如果只需要 At-Least-Once (至少一次),在这里直接写入或批量 Flush 即可。如果需要 Exactly-Once,这里只进行预提交(Pre-commit),并在
prepareCommit方法中生成Committable对象。
2. 定义 Committable 和 Serializer (可选,用于 Exactly-Once)
- 作用: 定义提交事务所需的信息(如事务ID、临时文件路径),并提供
SimpleVersionedSerializer。
3. 实现 Committer (提交器 - 可选,用于 Exactly-Once)
- 实现
Committer接口。 - 运行位置: TaskManager 或 JobManager (视具体实现而定)。
- 作用: 在 Checkpoint 完成时,接收来自 SinkWriter 的
Committable,执行真正的提交操作(如数据库的 Commit,或者把临时文件重命名为正式文件)。
4. 实现 Sink (入口类)
- 实现
Sink(SinkV2) 接口。 - 作用: 工厂类,创建
SinkWriter和Committer。
第四阶段:支持 Table API 与 Flink SQL (桥接层)
如果你希望用户能通过 CREATE TABLE 语句使用你的 Connector,必须完成此阶段。
1. 实现 DynamicTableSource (动态表输入)
- 实现
ScanTableSource和/或LookupTableSource接口。 - 作用: 它是 SQL 层与 DataStream Source 层的桥梁。在
getScanRuntimeProvider方法中,将你在“第二阶段”写好的 DataStreamSource包装进去(通常使用SourceProvider.of(yourSource))。可以实现各种 PushDown 接口(如谓词下推、投影下推)来优化性能。
2. 实现 DynamicTableSink (动态表输出)
- 实现
DynamicTableSink接口。 - 作用: SQL 层与 DataStream Sink 层的桥梁。在
getSinkRuntimeProvider中包装你在“第三阶段”写好的 DataStreamSink。
3. 实现 Factory (工厂类)
- 实现
DynamicTableSourceFactory和/或DynamicTableSinkFactory。 - 作用:
- 定义
factoryIdentifier()(这就是 SQL 中WITH ('connector' = '你的标识符'))。 - 定义
requiredOptions()和optionalOptions()(校验 SQL DDL 中的 WITH 参数)。 - 在
createDynamicTableSource/createDynamicTableSink方法中,读取参数并实例化前面的DynamicTableSource/Sink。
- 定义
4. 注册 SPI (Service Provider Interface)
- 在项目的
src/main/resources/META-INF/services/目录下创建文件,文件名为:org.apache.flink.table.factories.Factory。 - 文件内容为你写的 Factory 类的全限定名(如:
com.mycompany.flink.MyConnectorFactory)。 - 作用: 让 Flink 在启动时能够通过 Java SPI 机制自动发现你的 Connector。
第五阶段:测试与优化
1. 单元测试与集成测试
- 使用 Flink 提供的
MiniClusterWithClientResource编写集成测试,启动本地 Flink 集群测试数据读写。 - 使用 Flink 提供的 Test Harness 工具测试 Checkpoint 恢复时的状态是否正确(尤其是 Exactly-Once 语义)。
2. 最佳实践检查
- 类型系统 (TypeInformation): 确保 Connector 产生的数据类型能被 Flink 序列化器正确识别。
- Metrics (指标): 在 SourceReader 和 SinkWriter 中注册 Flink Metrics(如
numBytesIn,numRecordsOut),方便生产环境监控。 - Watermark 生成: 在 Source API 中,利用
RecordEmitter正确提取时间戳并生成 Watermark。 - 反压处理: 确保 Sink 在写入外部系统变慢时,能正确阻塞并引发 Flink 的反压,而不是导致 OOM。
总结流程图:
[用户 SQL DDL]
↓
[SPI 发现 Factory] -> 校验参数 -> [创建 DynamicTableSource/Sink]
↓
[生成 DataStream Source/Sink] (核心逻辑)
/ \
Source (Split/Enumerator/Reader) Sink (Writer/Committer)
/ \
从外部系统读数据 写数据到外部系统