 播面
播面 Flink自定义Format的开发步骤流程
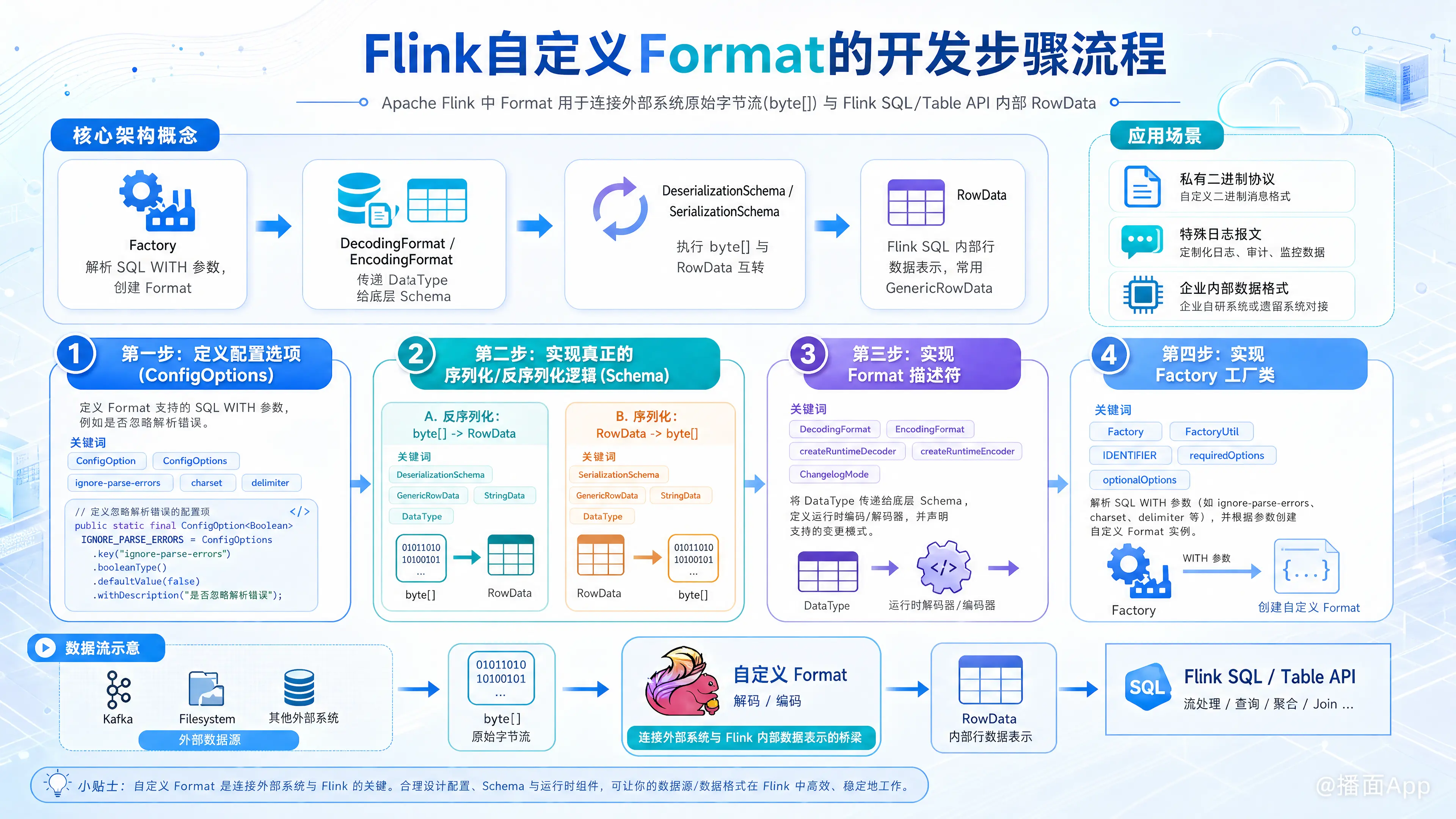
在 Apache Flink 中,Format(格式) 的作用是连接外部系统(如 Kafka、文件系统)的原始字节流(byte[])和 Flink SQL/Table API 内部的数据结构(RowData)。
如果你需要处理一种 Flink 原生不支持的特殊数据格式(例如公司内部自研的私有二进制协议、特殊的日志报文等),就需要开发自定义 Format。
以下是开发 Flink 自定义 Format 的标准步骤流程,基于 Flink 1.11+ 的新版 Table API 接口(Factory 架构):
核心架构概念
在动手之前,需要理解以下四个核心组件的关系:
Factory:工厂类,负责解析 SQL 中的WITH参数,并创建 Format。DecodingFormat/EncodingFormat:Format 描述符,负责将 Flink 的数据类型(DataType)传递给底层的 Schema。DeserializationSchema/SerializationSchema:真正的序列化/反序列化核心逻辑,执行byte[]和RowData的互转。RowData:Flink SQL 内部的行数据表示,通常我们手动组装时会使用GenericRowData。
第一步:定义配置选项 (ConfigOptions)
首先,定义你的 Format 支持哪些 SQL WITH 参数(例如分隔符、是否忽略错误等)。
java
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ConfigOptions;
public class MyFormatOptions {
// 示例:定义一个配置项 'myformat.ignore-parse-errors'
public static final ConfigOption<Boolean> IGNORE_PARSE_ERRORS = ConfigOptions
.key("ignore-parse-errors")
.booleanType()
.defaultValue(false)
.withDescription("是否忽略解析错误");
// 可以添加更多配置,如 charset, delimiter 等
}第二步:实现真正的序列化/反序列化逻辑 (Schema)
这是最核心的一步,处理 byte[] 和 RowData 的互相转换。
1. 反序列化 (字节 -> Flink SQL 数据)
java
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.table.data.GenericRowData;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.data.StringData;
import org.apache.flink.table.types.DataType;
import java.io.IOException;
import java.util.List;
public class MyFormatDeserializationSchema implements DeserializationSchema<RowData> {
private final DataType physicalDataType;
private final boolean ignoreParseErrors;
private final TypeInformation<RowData> producedTypeInfo;
public MyFormatDeserializationSchema(
DataType physicalDataType,
boolean ignoreParseErrors,
TypeInformation<RowData> producedTypeInfo) {
this.physicalDataType = physicalDataType;
this.ignoreParseErrors = ignoreParseErrors;
this.producedTypeInfo = producedTypeInfo;
}
@Override
public RowData deserialize(byte[] message) throws IOException {
try {
// 【核心逻辑】将 byte[] 转换为内部 RowData
String msg = new String(message);
String[] parts = msg.split(","); // 假设自定义逻辑是简单的逗号分隔
// 使用 GenericRowData 组装数据
GenericRowData rowData = new GenericRowData(parts.length);
for (int i = 0; i < parts.length; i++) {
// 注意:字符串需要转换为 Flink 内部的 StringData
rowData.setField(i, StringData.fromString(parts[i]));
}
return rowData;
} catch (Exception e) {
if (ignoreParseErrors) {
return null; // 忽略错误,返回 null 会被 Flink 过滤掉
}
throw new IOException("Failed to deserialize byte array.", e);
}
}
@Override
public boolean isEndOfStream(RowData nextElement) {
return false;
}
@Override
public TypeInformation<RowData> getProducedType() {
return producedTypeInfo;
}
}2. 序列化 (Flink SQL 数据 -> 字节)
(如果你的 Format 只需要读取不需要写入,可以不实现此部分)
java
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.DataType;
public class MyFormatSerializationSchema implements SerializationSchema<RowData> {
private final DataType physicalDataType;
public MyFormatSerializationSchema(DataType physicalDataType) {
this.physicalDataType = physicalDataType;
}
@Override
public byte[] serialize(RowData element) {
// 【核心逻辑】从 RowData 提取字段,拼接后转为 byte[]
// 注意:提取字段时需要根据 physicalDataType 知道每列是什么类型
StringBuilder sb = new StringBuilder();
int arity = element.getArity();
for (int i = 0; i < arity; i++) {
sb.append(element.getString(i).toString());
if (i < arity - 1) {
sb.append(",");
}
}
return sb.toString().getBytes();
}
}第三步:实现 Factory 工厂类
工厂类负责通过 SPI 被 Flink 发现,解析参数,并实例化上面写的 Schema。
java
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.format.EncodingFormat;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.factories.DeserializationFormatFactory;
import org.apache.flink.table.factories.DynamicTableFactory;
import org.apache.flink.table.factories.FactoryUtil;
import org.apache.flink.table.factories.SerializationFormatFactory;
import java.util.HashSet;
import java.util.Set;
public class MyFormatFactory implements DeserializationFormatFactory, SerializationFormatFactory {
public static final String IDENTIFIER = "my-format"; // SQL 中使用的名字
@Override
public String factoryIdentifier() {
return IDENTIFIER;
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
return new HashSet<>(); // 必填参数
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
Set<ConfigOption<?>> options = new HashSet<>();
options.add(MyFormatOptions.IGNORE_PARSE_ERRORS); // 选填参数
return options;
}
// 创建反序列化 Format
@Override
public DecodingFormat<DeserializationSchema<RowData>> createDecodingFormat(
DynamicTableFactory.Context context,
ReadableConfig formatOptions) {
// 校验配置
FactoryUtil.validateFactoryOptions(this, formatOptions);
// 获取参数值
final boolean ignoreParseErrors = formatOptions.get(MyFormatOptions.IGNORE_PARSE_ERRORS);
// 返回 DecodingFormat
return new DecodingFormat<DeserializationSchema<RowData>>() {
@Override
public DeserializationSchema<RowData> createRuntimeDecoder(
DynamicTableSource.Context context,
DataType physicalDataType) {
// 返回我们在第二步写的 Schema
return new MyFormatDeserializationSchema(
physicalDataType,
ignoreParseErrors,
context.createTypeInformation(physicalDataType) // 生成 Flink 内部需要的类型信息
);
}
@Override
public ChangelogMode getChangelogMode() {
return ChangelogMode.insertOnly(); // 仅追加数据
}
};
}
// 创建序列化 Format (同理)
@Override
public EncodingFormat<SerializationSchema<RowData>> createEncodingFormat(
DynamicTableFactory.Context context,
ReadableConfig formatOptions) {
// ... (类似上面的逻辑,返回 MyFormatSerializationSchema)
return null;
}
}第四步:注册 SPI (Service Provider Interface)
为了让 Flink 在运行时能找到你写的 MyFormatFactory,你需要使用 Java SPI 机制。
- 在你的项目的
src/main/resources目录下创建文件夹:META-INF/services/ - 在该文件夹下创建一个名为
org.apache.flink.table.factories.Factory的文本文件。 - 在文件内写入你刚才实现的 Factory 类的全限定类名:
plaintext
com.yourcompany.flink.format.MyFormatFactory第五步:打包并使用
- 使用 Maven 将你的代码打包成一个 JAR 文件(例如
my-flink-format-1.0.jar)。 - 将这个 JAR 包放入 Flink 安装目录的
lib/目录下(如果是集群模式),或者在提交任务时通过-j参数引入。 - 在 Flink SQL 中使用你的自定义 Format:
sql
CREATE TABLE my_kafka_table (
id STRING,
name STRING,
age STRING
) WITH (
'connector' = 'kafka',
'topic' = 'test_topic',
'properties.bootstrap.servers' = 'localhost:9092',
-- 使用自定义的 Format
'format' = 'my-format',
-- 配置你在 MyFormatOptions 中定义的参数
'my-format.ignore-parse-errors' = 'true'
);
-- 查询测试
SELECT * FROM my_kafka_table;开发注意事项 (避坑指南)
- 类型转换映射:在
DeserializationSchema中,外部数据需要转换为 Flink Table 内部的数据类型:String->StringData(StringData.fromString("..."))byte[]->byte[]Timestamp->TimestampDataArray->ArrayData
- 多层嵌套数据解析:如果数据很复杂(包含 Array/Map),你需要解析传入的
physicalDataType.getLogicalType(),这通常需要写一个递归的方法来提取数据结构。如果字段很多,建议参考 Flink 官方的JsonRowDataDeserializationSchema源码。 - 性能优化:
deserialize方法是针对每条数据执行的,要尽量避免在循环内创建大对象(如重复创建ObjectMapper或Gson实例),这些应该作为类的成员变量,并实现 Flink 的InitializationContext相关接口进行初始化,或者使用transient关键字并实现对象的按需初始化。