 播面
播面 使用 Flink SQL 时,对比使用 DISTINCT 关键字去重和使用 ROW_NUMBER() 筛选第一条去重(Deduplication),它们在状态保留策略和性能上有什么区别?
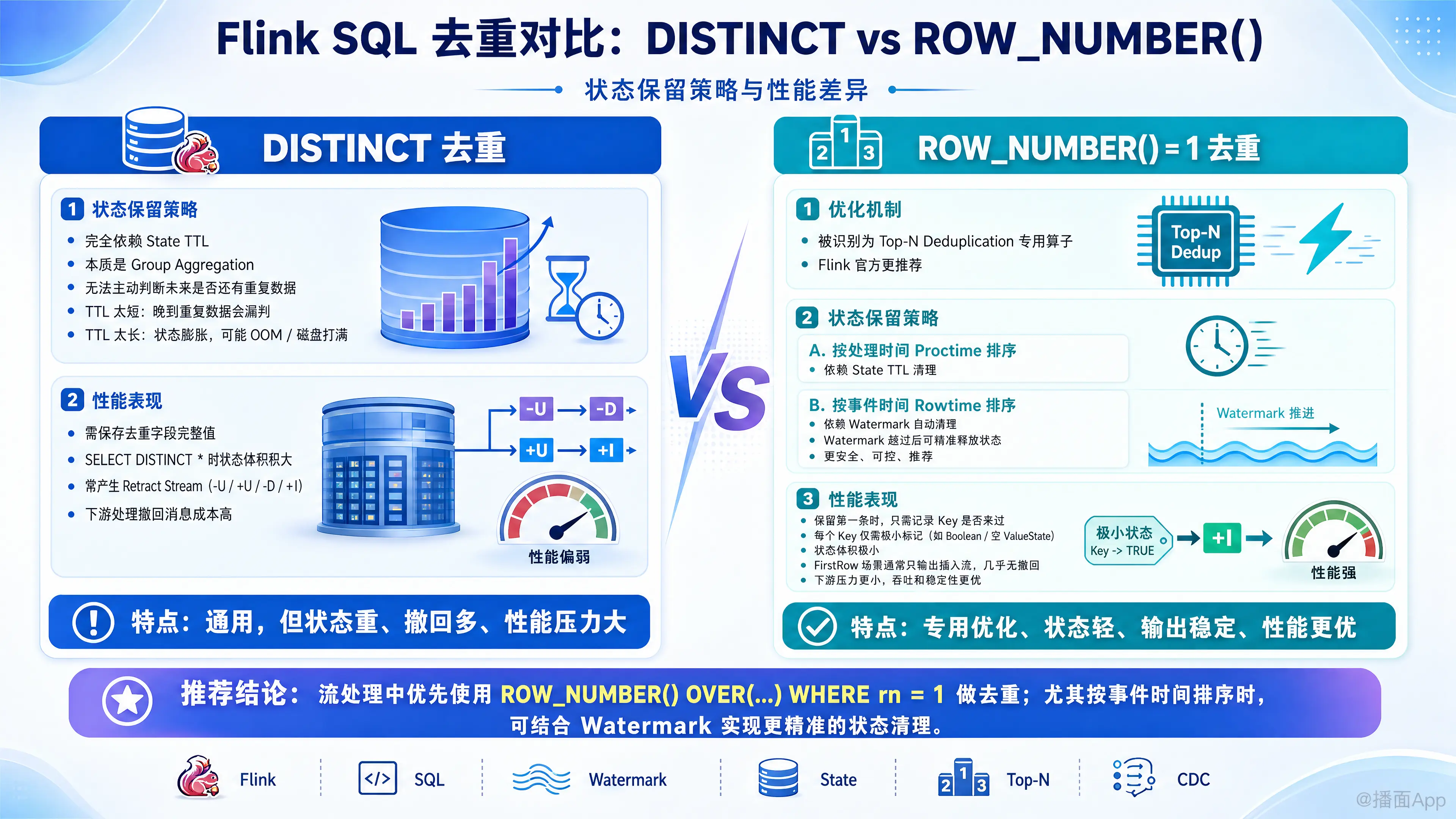
在 Flink SQL 中,数据去重是一个非常常见的需求。虽然 DISTINCT 和 ROW_NUMBER() OVER(...) WHERE rn = 1(保留第一条)在批处理中可能达到类似的效果,但在流处理(Streaming)中,由于底层实现和优化机制完全不同,它们在状态保留策略和性能上有着显著的区别。
总的来说,Flink 官方强烈推荐使用 ROW_NUMBER() 语法进行去重(Deduplication),因为它经过了专门的算子优化。
以下是它们在状态保留策略和性能上的详细对比:
一、 状态保留策略(State Retention)对比
在流处理中,为了识别重复数据,Flink 必须在 State(状态)中记住以前见过的数据。如何清理这些状态是两者的核心差异之一。
1. DISTINCT 的状态保留
- 清理机制:完全依赖 State TTL(状态生存时间)。
- 原理:
DISTINCT本质上是一个聚合(Group Aggregation)操作。Flink 无法预知未来的数据流中是否还会出现相同的数据,因此它不能主动清理状态。 - 缺点:你必须配置
table.exec.state.ttl。- 如果 TTL 设置得太短,晚到的重复数据会被当成新数据输出,导致去重不彻底。
- 如果 TTL 设置得太长,State 会持续膨胀,可能导致 OOM 或磁盘被打满。
2. ROW_NUMBER()(保留第一条)的状态保留
Flink SQL 优化器能够识别 ROW_NUMBER() = 1 这种特定的 Top-N 语法,并将其优化为专门的 Deduplication 算子。它的状态清理取决于你按什么时间属性排序(ORDER BY):
- 按处理时间(Processing Time / Proctime)排序:
- 清理机制:依赖 State TTL。
- 与 DISTINCT 类似,处理时间没有事件时间推进的概念,必须依靠配置的 TTL 来清理状态。
- 按事件时间(Event Time / Rowtime)排序:
- 清理机制:依赖 Watermark(水位线)自动清理。
- 这是最推荐的方式。当 Watermark 越过当前数据的 Event Time + Allowed Lateness 时,Flink 知道不会再有更早的数据到来了,会自动、精准地清理该时间窗口内的状态。
- 优点:不需要依赖全局的 State TTL,状态管理更加安全、可控。
二、 性能(Performance)对比
ROW_NUMBER() 经过 Flink 专门的 Deduplication 优化后,在性能上对 DISTINCT 形成了碾压优势。
1. 状态大小(State Size)
- DISTINCT:状态中需要保存去重字段的完整值。如果是
SELECT DISTINCT *,则需要把整行数据作为 Key 存入状态,状态体积非常大。 - ROW_NUMBER() (FirstRow):由于是保留第一条,Flink 只需要知道“这个 Key 是否已经来过”。因此,在底层实现中,Flink 只需要对每个 Partition Key 存储一个极小的标记(例如一个 Boolean 值或空的 ValueState)。状态体积被压缩到了极致。
2. 产生的消息流类型(Changelog Stream)
这是影响下游算子性能的关键因素。
- DISTINCT:通常会产生 撤回流(Retract Stream)。如果上游是 CDC 等包含 Update 的数据源,
DISTINCT会向下游发送大量的-U和+U(或-D,+I)消息。下游算子处理撤回消息的代价是非常高的。 - ROW_NUMBER() (FirstRow):因为业务逻辑是“只保留到达的第一条数据”,所以一旦某个 Key 的第一条数据被输出后,后续相同的 Key 到来会被直接丢弃。因此,它只会向下游发送
INSERT (+I)消息,绝对不会产生撤回消息(Update/Delete)。这极大减轻了下游算子(如 Sink)的压力。
3. Checkpoint 开销
- DISTINCT:由于状态体积大,Checkpoint 时需要持久化到 HDFS/OSS 的数据量大,耗时较长,容易造成反压。
- ROW_NUMBER():状态仅为一个轻量级标记,State 极小,Checkpoint 速度极快,对业务处理几乎无影响。
三、 总结与建议
| 维度 | DISTINCT |
ROW_NUMBER() WHERE rn = 1 (Deduplication) |
|---|---|---|
| 底层算子 | Group Aggregation | Deduplication (专门优化) |
| 状态存储内容 | 去重的全量字段 | 仅一个 Boolean/Empty 标记 (极小) |
| 状态清理机制 | 强依赖 State TTL | Proctime依赖TTL / EventTime依赖Watermark自动清理 |
| 向下游发送的消息 | 可能包含 Update/Retract,下游压力大 | 仅有 INSERT (+I),下游压力极小 |
| Checkpoint 压力 | 大 | 极小 |
| 适用场景 | 简单的全量数据去重统计 (流处理中不推荐) | 流处理中去重的标准/最佳实践 |
代码示例(最佳实践)
如果你想按 user_id 去重,只保留用户的第一条行为记录:
❌ 不推荐写法(DISTINCT)
sql
-- 性能差,状态大
SELECT DISTINCT user_id, user_name, behavior
FROM user_log;✅ 推荐写法(ROW_NUMBER 基于处理时间)
sql
-- 性能极好,状态极小,只发 INSERT
SELECT user_id, user_name, behavior
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY proctime ASC) as rn
FROM user_log
) WHERE rn = 1;结论:在 Flink SQL 流处理中进行去重,请永远优先考虑使用 ROW_NUMBER() OVER(...) WHERE rn = 1 语法。