 播面
播面 流计算过程中需要通过 Map 算子调用第三方 HTTP API 补全维表数据,因为网络延迟导致吞吐量极低。如何在 Flink 中使用异步 I/O (Async I/O) 加并发缓存来提升吞吐?
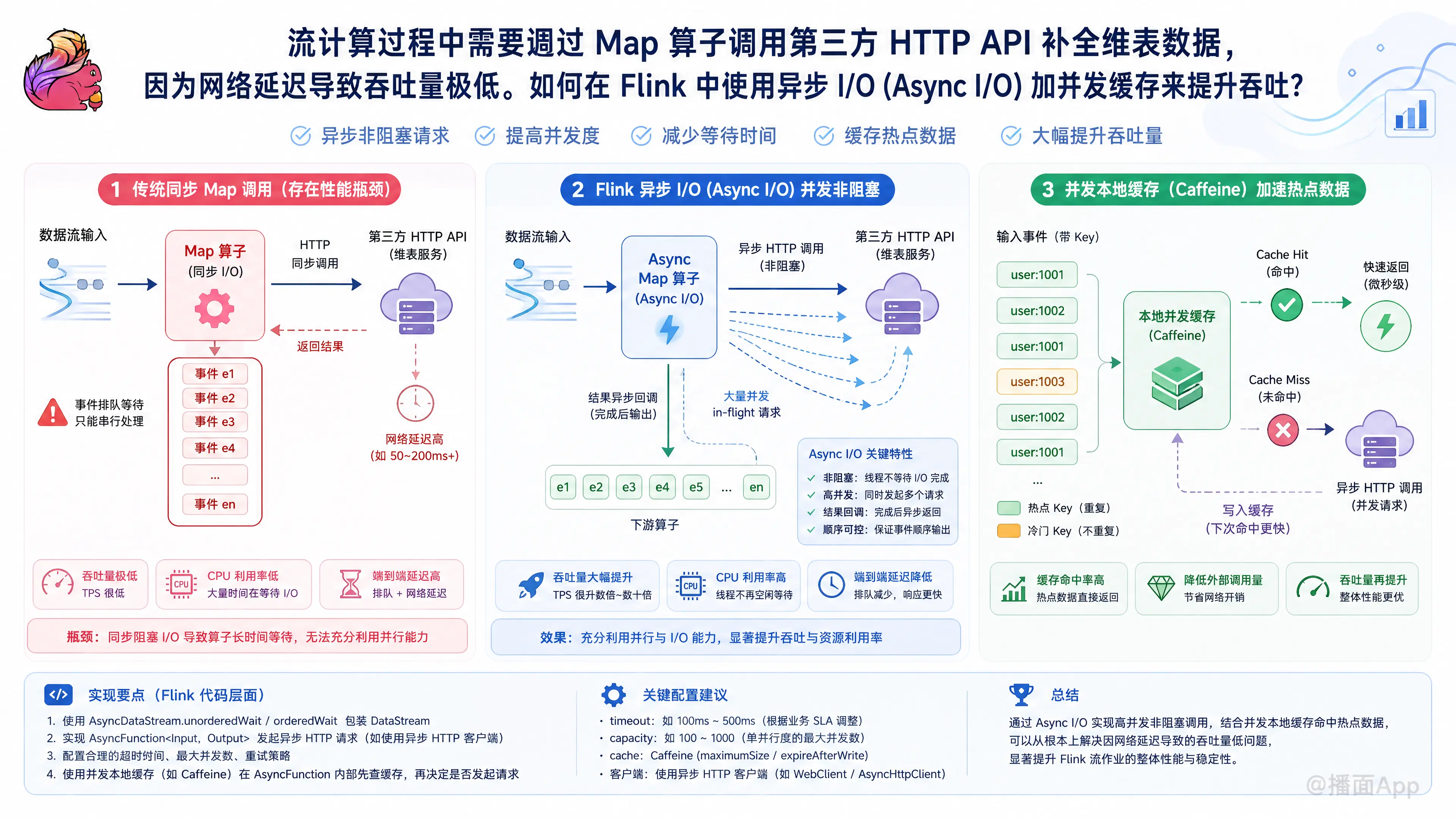
在流计算(Flink)中,通过同步的 Map 算子调用外部 HTTP API 进行维表关联,是典型的反模式。因为单线程同步等待网络 IO 会导致 CPU 大量空闲,吞吐量断崖式下降。
解决这个问题的标准方案是:Flink Async I/O(异步 IO) + 异步 HTTP Client + 本地并发缓存(如 Caffeine)。
下面将详细介绍如何实现这一方案,并提供完整的代码示例和生产环境调优指南。
1. 核心架构设计
- Async I/O (异步 IO):允许单个并发实例同时发起多个 HTTP 请求,而不需要等待上一个请求返回。Flink 会在后台管理这些飞行中(In-Flight)的请求。
- 异步 HTTP Client:必须使用支持异步非阻塞的 HTTP 客户端(如 Java 11+ 自带的
HttpClient、Apache HttpAsyncClient或Vert.x WebClient),否则在 AsyncFunction 中使用同步 HTTP 客户端仍然会阻塞 Flink 的 Task 线程。 - 并发缓存 (Concurrent Cache):使用
Caffeine缓存最近请求过的维表数据。由于异步回调会在不同的线程中执行,缓存必须是线程安全且高并发的。
2. 添加依赖
在 pom.xml 中引入 Flink 依赖以及高性能缓存库 Caffeine:
<!-- 引入 Caffeine 缓存 -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.8</version>
</dependency>(注:HTTP Client 我们直接使用 Java 11+ 内置的 java.net.http.HttpClient,因为它原生返回 CompletableFuture,与 Flink 异步 IO 结合极其平滑。)
3. 编写带有缓存的 AsyncFunction
我们需要继承 RichAsyncFunction,在 open 方法中初始化 HttpClient 和 Cache,在 asyncInvoke 中处理逻辑。
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
import java.util.Collections;
import java.util.concurrent.CompletableFuture;
public class HttpAsyncEnrichmentFunction extends RichAsyncFunction<InputData, EnrichedData> {
private transient HttpClient httpClient;
private transient Cache<String, String> cache;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 1. 初始化异步 HTTP Client (配置连接池和超时)
httpClient = HttpClient.newBuilder()
.version(HttpClient.Version.HTTP_2)
.connectTimeout(Duration.ofSeconds(3)) // 连接超时
.build();
// 2. 初始化本地并发缓存 Caffeine
cache = Caffeine.newBuilder()
.maximumSize(100000) // 最大缓存数量
.expireAfterWrite(Duration.ofMinutes(10)) // 写入后 10 分钟过期,保证维表数据更新
.build();
}
@Override
public void asyncInvoke(InputData input, ResultFuture<EnrichedData> resultFuture) {
String key = input.getUserId(); // 假设用 UserId 关联维表
// 3. 查缓存 (命中则直接返回,避免网络开销)
String cachedValue = cache.getIfPresent(key);
if (cachedValue != null) {
EnrichedData result = new EnrichedData(input, cachedValue);
resultFuture.complete(Collections.singletonList(result));
return; // 结束处理
}
// 4. 缓存未命中,发起异步 HTTP 请求
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("http://api.example.com/userInfo?userId=" + key))
.timeout(Duration.ofSeconds(2)) // 读超时
.GET()
.build();
CompletableFuture<HttpResponse<String>> responseFuture =
httpClient.sendAsync(request, HttpResponse.BodyHandlers.ofString());
// 5. 处理异步回调
responseFuture.whenComplete((response, exception) -> {
if (exception != null) {
// 网络异常处理:记录日志,可以返回带默认值的对象,或者使 future 失败
System.err.println("HTTP 请求失败: " + exception.getMessage());
// 根据业务需求:允许数据流失则 complete(空集合),要求强一致则 completeExceptionally
resultFuture.completeExceptionally(exception);
} else {
if (response.statusCode() == 200) {
String apiResult = response.body();
// 写入缓存 (Caffeine 是线程安全的)
cache.put(key, apiResult);
// 组装结果并输出
EnrichedData result = new EnrichedData(input, apiResult);
resultFuture.complete(Collections.singletonList(result));
} else {
// API 返回非 200 错误码处理
resultFuture.complete(Collections.singletonList(new EnrichedData(input, "DEFAULT_VALUE")));
}
}
});
}
@Override
public void timeout(InputData input, ResultFuture<EnrichedData> resultFuture) {
// 6. Flink 层的异步超时处理
System.err.println("Async I/O 请求超时: " + input.getUserId());
resultFuture.complete(Collections.singletonList(new EnrichedData(input, "TIMEOUT_DEFAULT")));
}
@Override
public void close() throws Exception {
// 资源清理
if (cache != null) {
cache.cleanUp();
}
super.close();
}
}4. 在 Flink Job 中集成 AsyncFunction
在组装 DataStream 时,使用 AsyncDataStream 包装你的数据流:
import org.apache.flink.streaming.api.datastream.AsyncDataStream;
import org.apache.flink.streaming.api.datastream.DataStream;
// ... 初始化 env 和 inputStream
// 使用异步 IO 处理流
DataStream<EnrichedData> enrichedStream = AsyncDataStream.unorderedWait(
inputStream,
new HttpAsyncEnrichmentFunction(),
3000, // 超时时间:3秒 (必须大于 HTTP Client 的超时时间)
TimeUnit.MILLISECONDS,
100 // 容量 (Capacity):最大同时进行中的异步请求数
);orderedWait vs unorderedWait
unorderedWait(推荐):只要某个异步请求先返回,就先向下游发送。吞吐量最高,延迟最低。适用于对数据顺序没有严格要求的场景。orderedWait:保证输出顺序与输入顺序完全一致。如果前面的请求未返回,后面的请求即使返回了也要在 Flink 内存中排队等待。会增加延迟和内存占用。
5. 生产环境调优指南 (极其重要)
代码写完只是第一步,要达到高吞吐,必须调整以下参数:
1. 异步容量 (Capacity) 的计算逻辑 (Little's Law)
Capacity 参数表示单 Task 并发能容纳的最多异步请求数。
如果你的目标吞吐是 10000 QPS,API 平均响应时间是 50ms (0.05s),那么你至少需要的并发请求数(Capacity)为:Capacity = QPS * Latency = 10000 * 0.05 = 500
如果 Flink 并发度为 10,那么配置的参数应为 500 / 10 = 50。建议预留 2 倍 buffer,设置为 100。
2. HTTP Client 底层连接池
极其容易被忽略的一点:就算 Flink 的 Capacity 设置为 1000,如果底层的 HTTP Client 连接池最大连接数(Max Connections)只有 50,那么剩下的 950 个请求全都在本地排队,根本没有发出去。
如果使用 Apache HttpAsyncClient,务必调整 setMaxTotal() 和 setDefaultMaxPerRoute()。Java 11 HttpClient 默认没有硬性连接数限制,但受限于操作系统的临时端口数。
3. 缓存策略优化 (Caffeine)
- 命中率:缓存的意义在于减少外部请求。如果 key (如 UserId) 高度分散且只出现一次,缓存不仅无效还会增加 GC 压力。此时应考虑 Redis 甚至不要缓存。
- 缓存大小 (
maximumSize):评估单个 value 的内存占用,避免 OOM。比如 100 万条字符串数据可能占用几百 MB 内存。 - 过期策略 (
expireAfterWrite):维表数据是会变的。根据业务容忍度设置过期时间。不要设置永不过期。
4. Flink Checkpoint 影响
需要注意的是,本地缓存(Caffeine)是 Transient(瞬态)的,不会被写入 Flink Checkpoint。
当 Flink 任务崩溃重启时,缓存是空的,此时会产生缓存雪崩效应(大量请求瞬间打向 HTTP API)。
解决策略:可以在 HTTP Client 中加入限流器(如 Guava RateLimiter),或者要求 HTTP API 端具备抗高并发及限流降级能力。
5. 资源隔离与线程池
在 Java 11 HttpClient 的 sendAsync 底层使用了公用的 ForkJoinPool。如果 HTTP 请求非常密集,建议为 HttpClient 提供专属的 ExecutorService,避免干扰 Flink Task 线程:
ExecutorService customExecutor = Executors.newFixedThreadPool(50);
httpClient = HttpClient.newBuilder().executor(customExecutor).build();记得在 close() 方法中关闭这个线程池。