 播面
播面 集群有 10 台机器,每台机器 16 核 64G。你有一个包含 Kafka Source -> Map -> KeyBy Window -> Redis Sink 的任务,你会如何规划 TaskManager 的数量、Slot 数量以及各个算子的并行度?
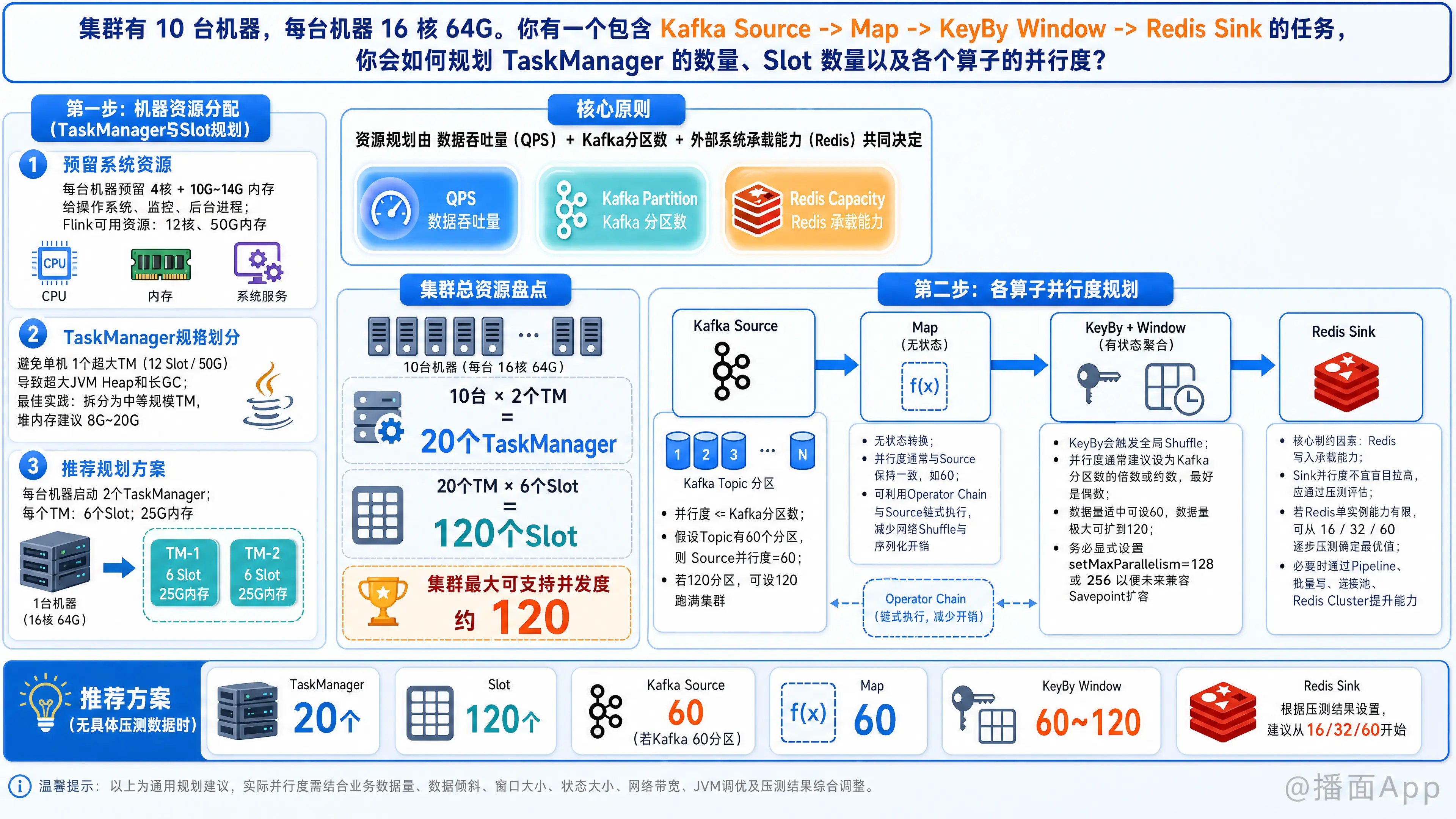
这是一个非常经典的 Flink 生产环境资源规划与调优问题。
要给出合理的规划,首先需要明确一个核心原则:资源规划不是凭空想象的,而是由“数据吞吐量(QPS)”、“Kafka 分区数”以及“外部系统的承载能力(Redis)”共同决定的。
在没有具体数据量的情况下,我将基于 10台 16核 64G 的硬件配置,为你提供一套生产环境的最佳实践推导过程和推荐方案。
第一步:机器资源分配(TaskManager与Slot规划)
1. 预留系统资源
- 千万不要把机器的所有资源全部分配给 Flink。操作系统、后台进程(如 HDFS/YARN NodeManager/K8s Kubelet)、监控组件等需要预留资源。
- 建议: 每台机器预留 4 个核心和 10G-14G 内存给系统。
- Flink 可用资源: 每台机器 12 核,50G 内存。
2. TaskManager (TM) 规格划分
- 误区: 每台机器只配 1 个 TM,拥有 12 个 Slot 和 50G 内存。
- 原因: 50G 的超大 JVM Heap 会导致极长的 GC(垃圾回收)停顿时间,严重影响流处理的延迟。
- 最佳实践: 将大机器拆分成多个中等规模的 TM。建议 TM 的堆内存控制在 8G - 20G 之间。
- 规划方案:
- 每台机器启动 2 个 TaskManager。
- 每个 TM 分配 6 个 Slot(对应 6 个 CPU Core)。
- 每个 TM 分配 25G 内存。
3. 集群总资源盘点
- 总 TaskManager 数量: 10台 × 2 = 20 个 TM。
- 总 Slot 数量: 20 个 TM × 6 = 120 个 Slot。(这意味着该集群最大可支持并发度为 120 的任务)。
第二步:各算子并行度(Parallelism)规划
假设默认都在同一个 Slot Sharing Group(共享槽组)中,我们来逐个分析算子:
1. Kafka Source
- 核心制约因素: Kafka Topic 的 Partition(分区)数量。
- 规则: Source 并行度 必须 <= Kafka 分区数。如果大于分区数,多出来的 Slot 会一直空闲;如果远小于分区数,容易产生数据积压。
- 规划: 假设你的 Kafka 有 60 个分区,那么 Source 并行度设为 60。(如果分区数是 120,则设为 120,刚好跑满集群)。
2. Map 算子(无状态转换)
- 核心制约因素: CPU 计算逻辑的复杂度。
- 规则: 尽量与 Source 保持一致,利用 Flink 的 Operator Chain(算子链) 机制。
- 规划: Map 并行度设为 60。它会和 Source 融合成一个 Task,在同一个线程里执行,避免了网络 Shuffle 和序列化/反序列化开销。
3. KeyBy -> Window 算子(有状态聚合)
- 核心制约因素: Key 的分布(是否有数据倾斜)、窗口大小、状态后端的压力。
- 规则: KeyBy 会引发全局的网络 Shuffle。并行度通常建议设置为 Kafka 分区数的倍数或约数,并且最好是偶数。
- 规划:
- 如果聚合逻辑简单,数据量适中,并行度设为 60。
- 如果数据量极大,或者 CPU 计算密集,可以扩大到整个集群的上限,并行度设为 120。
- 注意: 务必显式设置
setMaxParallelism(),一般设为 128 或 256,以便未来扩容时修改并行度能兼容旧的 Savepoint。
4. Redis Sink
- 核心制约因素: Redis 集群的连接数限制和写入 QPS 瓶颈。
- 规则: Sink 的并发度绝不是越高越好。过高的并发会导致与 Redis 建立海量连接,极易把 Redis 打挂(连接数耗尽或 CPU 满载)。
- 规划:
- 需要使用
disableChaining()断开与 Window 算子的链。 - Sink 并行度建议调低,例如 20 ~ 30(具体取决于 Redis 集群规模)。
- 强烈建议: 在 Sink 端一定要使用 Redis Pipeline(管道)或者批量写入(Batch Commit),不要来一条写一条。
- 需要使用
第三步:内存与状态后端(State Backend)专项优化
你的任务包含 Window,这是一个典型的有状态计算,必须针对内存做规划:
1. 状态后端选择
- 如果 Window 很大(例如 1小时/1天的窗口),积累的状态数据极多,必须使用 RocksDBStateBackend。
- 如果 Window 很小(例如 5秒/10秒的滚动窗口),状态数据很少,可以使用 HashMapStateBackend (JobManagerCheckpoint),性能更高。
2. TaskManager 内存配比调整(以 RocksDB 为例)
我们前面给每个 TM 分配了 25G 内存。如果使用 RocksDB,它使用的是堆外内存(Managed Memory):
- JVM 堆内存(Heap): 用于 Source、Map 解析数据,分配 10G。
- 托管内存(Managed Memory): 用于 RocksDB 读写,必须调大,建议分配 10G-12G(
taskmanager.memory.managed.fraction调至 0.4 - 0.5)。 - 网络缓冲(Network Buffer): 因为有 KeyBy Shuffle,网络通信多,预留 2G-3G。
总结:最终推荐架构配置清单
基于上述推导,你的 flink-conf.yaml 及任务提交参数建议如下:
【集群资源级】
taskmanager.numberOfTaskManagers: 20 (如果是 YARN/K8s 模式动态申请)taskmanager.memory.process.size: 25gtaskmanager.numberOfTaskSlots: 6
【算子并行度级(假设 Kafka 为 60 分区)】
Kafka Source: 60Map: 60 (与 Source 发生 Chain 绑定)KeyBy Window: 60 或 120 (视 CPU 负载而定,发生网络 Shuffle)Redis Sink: 30 (视 Redis 承受能力而定,断开 Chain,使用批处理写入)
【关键调优代码示例】
java
// 全局环境设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置最大并行度,为后续扩容留后路
env.setMaxParallelism(256);
// 开启 Checkpoint
env.enableCheckpointing(60000);
// 1. Source & Map (并行度 60)
DataStream<Result> mappedStream = env
.addSource(new FlinkKafkaConsumer<>(...)).setParallelism(60)
.map(new MyMapFunction()).setParallelism(60); // 自动与 Source Chaining
// 2. KeyBy & Window (并行度 60 或 120)
DataStream<AggResult> windowStream = mappedStream
.keyBy(data -> data.getKey())
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.aggregate(new MyAggregateFunction()).setParallelism(120);
// 3. Redis Sink (降低并行度至 30,保护下游)
windowStream
.addSink(new MyRedisSinkFunction()).setParallelism(30)
.disableChaining(); // 强制断开链,使得 Window 和 Sink 在不同线程执行这种规划充分利用了 120 个可用 Slot 的计算能力,有效避免了超大内存带来的 GC 问题,同时兼顾了 Kafka 读取和 Redis 写入的外部 I/O 瓶颈。