 播面
播面 电商大促时,某个大商家(热点大 Key)产生了千万级别的订单流入,导致某个 TaskManager 资源打满甚至 OOM,而其他 TaskManager 却很空闲。如何解决热点大 Key 造成的计算倾斜?
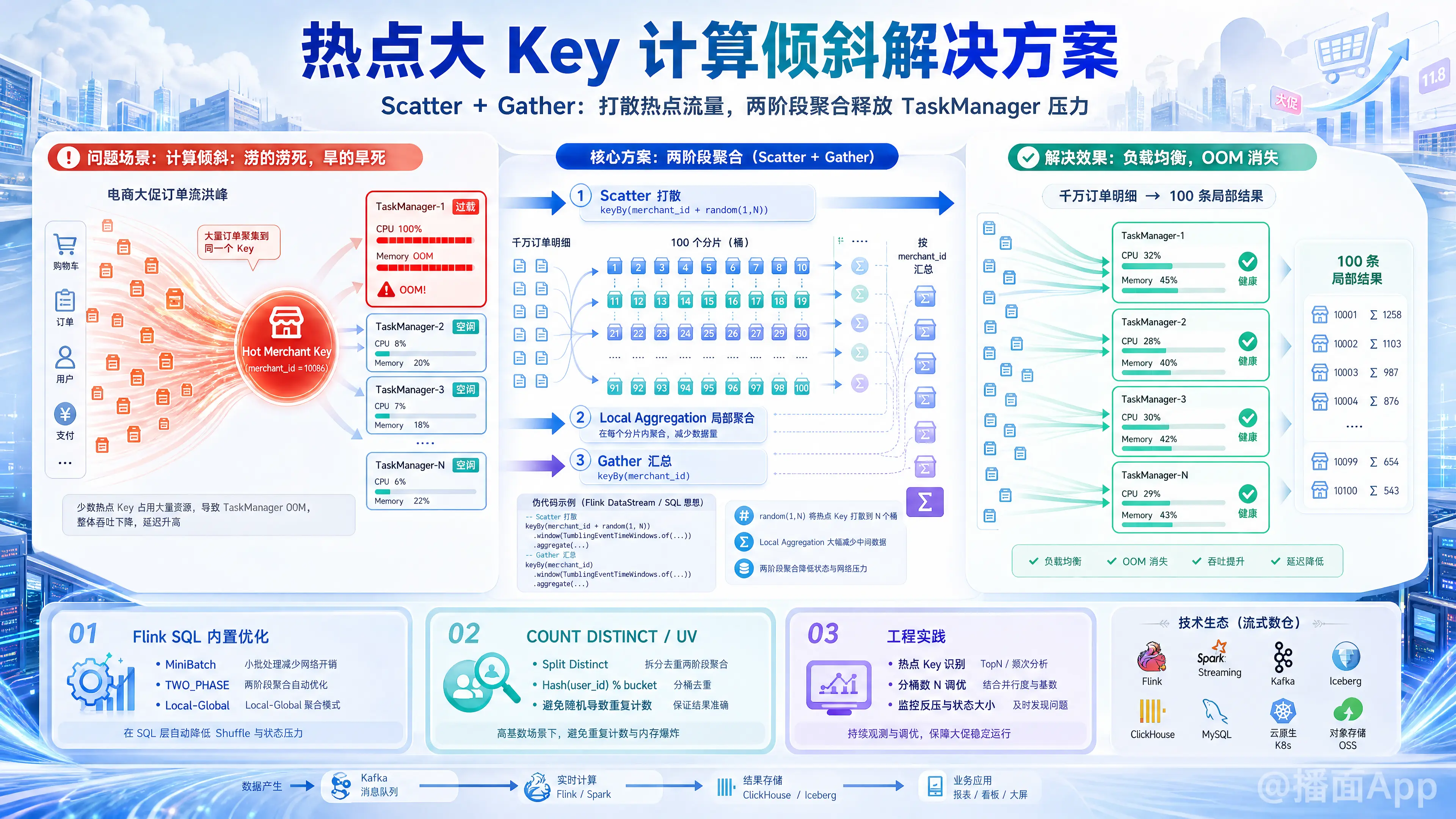
在电商大促(如双11)场景下,大商家(热点大 Key)引发的计算倾斜和 TaskManager OOM 是实时计算(如 Flink / Spark Streaming)中最经典的高频痛点。
针对这种“旱的旱死,涝的涝死”的情况,核心解决思路是“打散(Scatter)+ 聚合(Gather)”。以下是按实现难度和场景分类的系统性解决方案:
一、 核心方案:两阶段聚合(Two-Phase Aggregation)
这是解决热点 Key 聚合最根本、最通用的方法。将单点计算压力分摊到整个集群。
1. 第一阶段:打散(Local Aggregation)
给原本的 merchant_id 加上一个随机前缀或后缀(例如 1 到 N 的随机数),将同一个大商家的数据强行打散到 个不同的 Task 中进行局部聚合。
- 伪代码:
keyBy(merchant_id + "_" + random(1, 100)) - 效果: 千万级订单被平均分给了 100 个 Task,每个 Task 计算局部结果(例如局部 SUM)。
2. 第二阶段:汇总(Global Aggregation)
将第一阶段的局部聚合结果去掉随机后缀,恢复成真正的 merchant_id,再次进行 keyBy,做全局最终聚合。
- 伪代码:
keyBy(merchant_id) - 效果: 此时流入大商家 Task 的数据量,从“千万级订单明细”变成了“100 条局部聚合结果”,TaskManager 轻松处理,彻底解决打满和 OOM 问题。
二、 Flink SQL 用户的福音:开启内置优化参数
如果你使用的是 Flink SQL,完全不需要改动代码,只需在配置中开启 Flink 针对热点倾斜提供的内置优化机制即可。
1. 开启 MiniBatch(微批处理)
减少状态访问和向下游发送数据的频率,极大缓解 CPU 和 OOM 压力。
# 开启 mini-batch
table.exec.mini-batch.enabled: true
# 允许的最大延迟时间(例如 5 秒攒一批)
table.exec.mini-batch.allow-latency: 5 s
# 每个 Task 最大缓存的数据条数
table.exec.mini-batch.size: 200002. 开启 Local-Global 优化(自动两阶段聚合)
基于 MiniBatch 开启后,Flink 引擎会自动帮你做“本地预聚合 + 全局聚合”。专门解决 SUM、COUNT、MAX、MIN 等普通聚合的倾斜。
# 开启两阶段聚合策略
table.optimizer.agg-phase-strategy: TWO_PHASE3. 开启 Split Distinct 优化(解决 COUNT DISTINCT 倾斜)
如果是算大商家的 UV(独立买家数),普通的 Local-Global 是无效的。需要开启拆分去重参数。
# 解决 COUNT DISTINCT 热点问题
table.optimizer.distinct-agg.split.enabled: true
# 拆分的桶数量,默认 1024
table.optimizer.distinct-agg.split.bucket-num: 1024原理是 Flink 会自动在 SQL 底层按 Hash(user_id) % bucket_num 把去重操作打散到多个桶,最后再合并。
三、 针对精确去重(COUNT DISTINCT)的特殊处理
在 DataStream API 下,如果业务需要计算大商家的 UV,两阶段加随机数的方法行不通(因为同一个用户可能被分到不同的随机 Task 中,导致去重结果偏大)。
方案 1:按 UserID 分桶打散(推荐)
不要加随机数,而是用买家的 user_id 的 Hash 值求余作为后缀。
Phase 1 keyBy:merchant_id + "_" + (hash(user_id) % 100)- 这样保证了同一个买家一定在同一个预处理 Task 中去重。
Phase 2 keyBy:merchant_id,把 100 个桶的 UV 值直接相加即可(因为桶之间绝对没有重复买家)。
方案 2:使用 HyperLogLog / RoaringBitmap
- 非精确去重: 如果业务容忍 1%~2% 的误差,直接使用
HyperLogLog替代 HashSet 保存 UV 状态,内存占用从 G 级别降到 KB 级别,彻底消灭 OOM。 - 精确去重: 使用
RoaringBitmap(咆哮位图)来存储user_id(前提是 user_id 是整型),不仅内存占用极小,而且在第二阶段合并(BitMap OR 操作)时速度极快。
四、 架构与系统层面的兜底策略
1. 热冷数据分流(Hot-Cold Separation)
如果大促期间头部大商家就那么几个(例如苹果官方旗舰店、优衣库等),可以在上游做一个动态测速或静态配置。
- 大商家走单独链路: 在 Flink 开头加一个
Filter或SideOutput(侧输出流)。把大商家的流单独切出来,分配更多的资源,或者直接把明细写入 ClickHouse / Redis 等外部 OLAP 引擎去硬算。 - 中小商家走常规链路: 避免大商家拖垮整个集群影响其他商家的时效性。
2. 更换 State Backend(解决 OOM)
如果 TaskManager 发生 OOM 是因为 HashMap State 撑爆了堆内存:
- 改为 RocksDB State Backend:将状态存储到本地磁盘(SSD),突破 JVM 堆内存限制。虽然性能会有轻微下降,但能保证系统不崩。
- 开启 RocksDB 的增量 Checkpoint,防止由于大 Key 导致单点 Checkpoint 超时失败。
3. 增大并发与并行度调整
检查 Kafka 的 Partition 数量与 Flink 的并行度是否匹配。如果 Kafka 某个 Partition 因为上游生产倾斜就已经挤压了大量数据,Flink Source 端就会成为瓶颈,需要在上游 Kafka 发送端就做好 Round-Robin 轮询打散。
💡 总结与建议操作路径
- 首选低成本方案: 如果用的是 Flink SQL,立刻开启
MiniBatch+Local-Global+Split Distinct,通常能解决 90% 的问题。 - DataStream 核心方案: 如果是写代码,实现 “加随机数前缀的 Two-Phase 聚合”(求和/计数)或 “加 UserID Hash 前缀的分桶聚合”(去重)。
- 保命底线: 状态后端必须切换为 RocksDB,防止大 Key 的海量状态导致 JVM OOM。结合大促预案,提前扩容该作业的 TaskManager 内存。