 播面
播面 在flink中,什么时候你会放弃精确的 Event Time,而选择使用 Processing Time 作为窗口划分的依据?
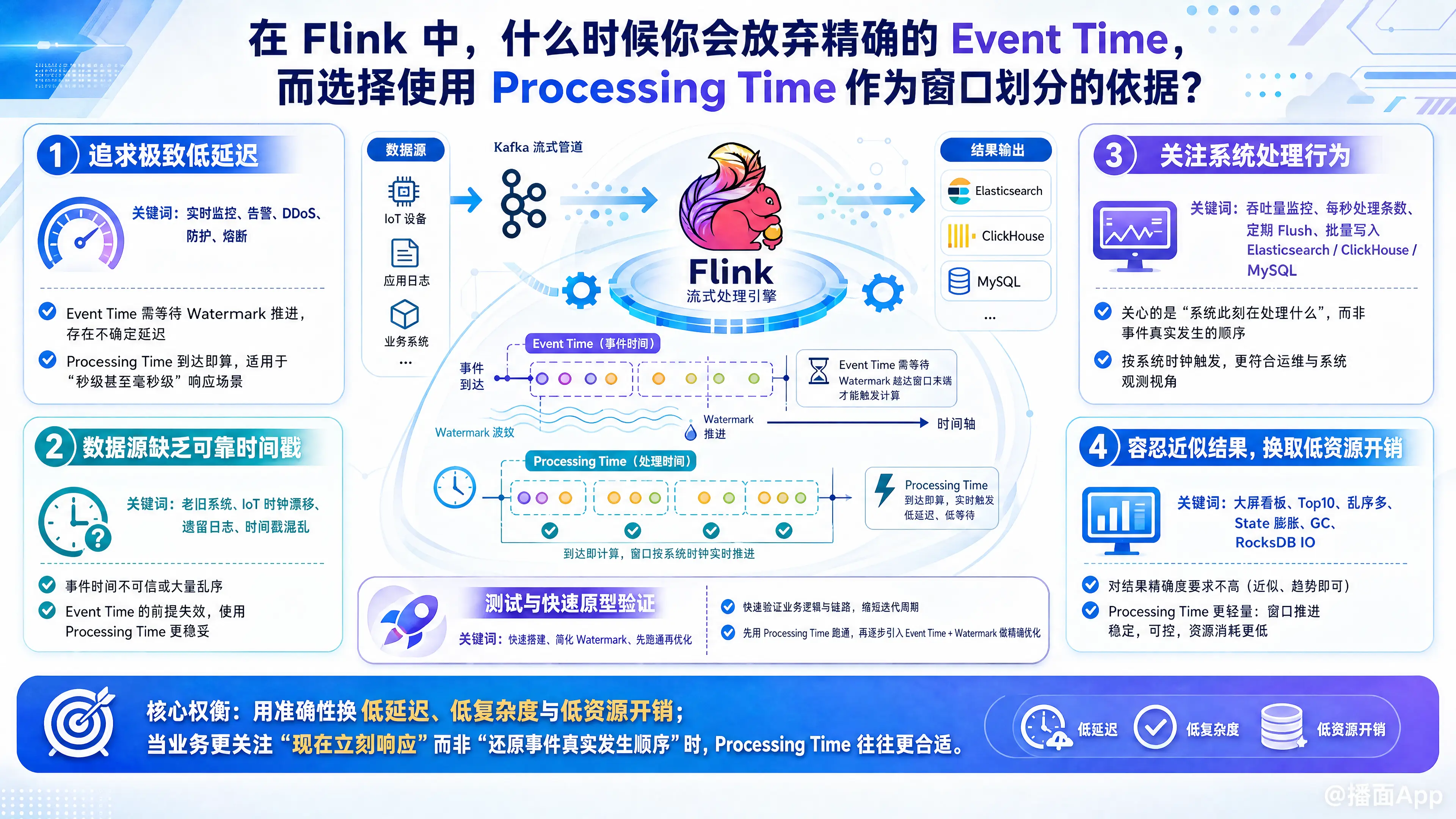
在 Apache Flink 中,Event Time(事件时间) 通常是默认且推荐的选择,因为它能保证结果的确定性,并且能完美处理乱序和延迟数据。然而,Event Time 的代价是增加了处理延迟(需要等待 Watermark)和增加了状态开销。
当你决定放弃精确的 Event Time,而选择 Processing Time(处理时间) 作为窗口划分依据时,通常是因为你的业务场景在低延迟、系统资源、数据本身特性等方面做出了权衡。
以下是我会选择使用 Processing Time 的几个典型场景:
1. 追求极致的低延迟(实时监控与告警)
- 原因:Event Time 依赖 Watermark 的推进来触发窗口。为了容忍乱序数据,Watermark 通常会设置一个延迟(例如允许迟到 5 秒)。这意味着窗口的触发至少会被故意延迟 5 秒。
- 场景:在网络安全防护(如 DDoS 攻击检测)、系统故障实时熔断等场景中,每一毫秒都很关键。如果某个 IP 的请求量在 1 秒内激增,系统需要立刻报警并封禁,而不是等待 5 秒后的 Watermark 来确认数据是否到齐。此时,使用 Processing Time 可以做到数据到达 Flink 节点后立刻被统计和触发。
2. 数据源本身缺乏可靠的时间戳
- 原因:Event Time 的前提是数据自带准确的时间戳。如果时间戳不可靠,Event Time 窗口的计算结果也会是错误的,甚至会导致 Watermark 无法正常推进(卡死)。
- 场景:
- 老旧系统或简易 IoT 设备:设备没有时钟同步(NTP),导致上报的时间戳极度混乱或严重漂移。
- 没有时间戳的遗留日志:某些古老的日志流在生成时完全没有记录毫秒级的时间字段。
- 在这种情况下,“垃圾进,垃圾出”,强行使用 Event Time 毫无意义,不如直接使用 Flink 接收到数据的本地时钟(Processing Time)来划分窗口。
3. 业务逻辑关注的是“系统处理行为”而非“事件发生事实”
- 原因:有时候,我们统计的目的不是为了还原客观世界的真实情况,而是为了衡量或控制 Flink 系统本身的处理状态。
- 场景:
- 系统吞吐量监控:你想统计“Flink 任务每秒处理了多少条数据”,这本质上就是一个基于 Processing Time 的指标。
- 定期微批写入(Sink Flush):为了提高写入外部数据库(如 Elasticsearch、ClickHouse、MySQL)的性能,你需要“每隔 5 秒钟将当前缓存的数据批量写入一次”。这种“定期触发”的操作,使用 Processing Time 窗口(或 Processing Time Timer)是最合理、最简单的,使用 Event Time 反而会因为没数据时 Watermark 不推进而导致无法按时 Flush。
4. 容忍近似结果,且希望大幅降低系统资源开销
- 原因:Event Time 窗口需要将数据保留在 State(状态)中,直到 Watermark 越过窗口结束时间。如果存在严重乱序,或者迟到数据很多,State 会变得非常庞大,引发严重的 GC 问题或 RocksDB 磁盘 IO 瓶颈。Processing Time 窗口不考虑乱序,时间一到立刻触发并清空 State,内存管理极其可控且轻量。
- 场景:粗粒度的实时大屏看板。例如统计“当前 1 分钟内的热门搜索词 Top 10”。这种场景下,少统计几个迟到几秒的数据对最终的 Top 10 排名几乎没有影响。为了这点极度苛求的准确性去维护庞大的 Event Time 状态是不划算的,用 Processing Time 既省资源又能满足业务的大致趋势需求。
5. 测试与快速原型验证
- 原因:Event Time 需要处理 Watermark 的生成策略(AssignerWithPeriodicWatermarks 等),还要考虑乱序容忍度、空闲分区(Idle Source)等复杂问题,容易出现“窗口不触发”的调试难题。
- 场景:在开发初期,为了快速验证 Flink 算子逻辑(如聚合、连接)是否走通,直接使用 Processing Time 可以屏蔽掉时间同步和 Watermark 的干扰,让开发者专注于业务代码本身的逻辑验证。
总结:何时切换?
可以把这个选择看作是一个 CAP 原理式的权衡:
- 选择 Event Time:你选择了 正确性(Correctness) 和 确定性(Determinism),付出的代价是 延迟(Latency) 和 资源(State Size)。
- 选择 Processing Time:你选择了 极低延迟 和 系统极简/高性能,付出的代价是 牺牲了业务数据的精确性,且结果是 不可重现的(如果由于故障重启重新消费 Kafka,Processing Time 算出的结果会和之前完全不同,因为处理的物理时间变了)。
只要业务方能够接受“结果不可重现”以及“少许时间错位”,并且极度渴望低延迟和省资源,就是放弃 Event Time 的最佳时机。