 播面
播面 在基于 Event Time 的滚动窗口中,经常有迟到长达几个小时甚至几天的数据到来。业务要求既不能让窗口等太久,又不能丢弃迟到数据,你会如何利用 Flink 的机制组合解决?
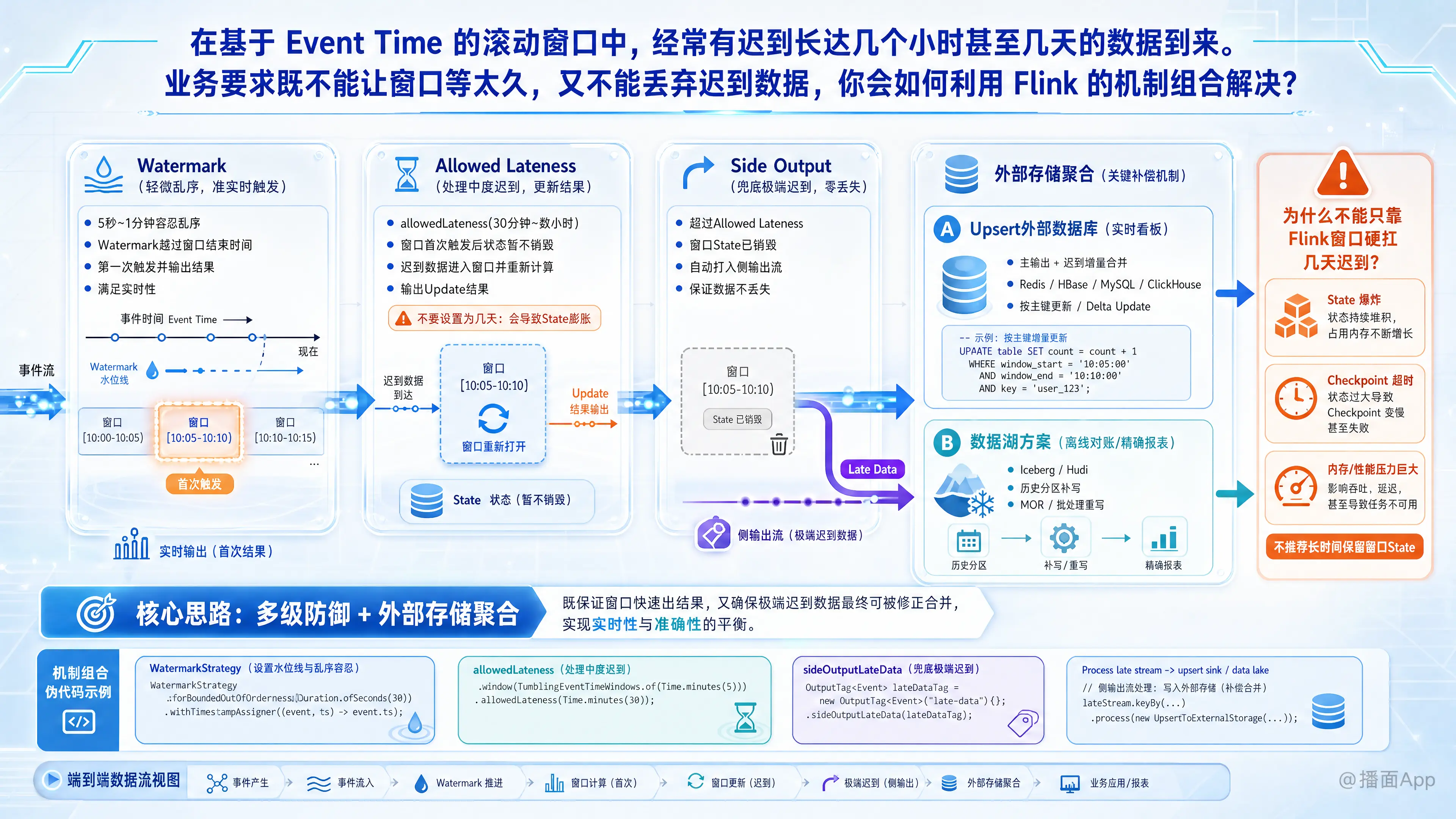
在 Flink 中处理长达数小时甚至数天的极端迟到数据,同时要求“窗口不能等太久(保证实时性)”且“不能丢数据(保证准确性)”,是一个经典的流处理架构难题。
如果仅仅依赖 Flink 的内置窗口状态来容忍数天的迟到,会导致 State 爆炸,进而引发 Checkpoint 超时、内存溢出或极差的性能。
为了完美解决这个问题,我会采用“多级防御 + 外部存储聚合”的组合机制。具体方案如下:
核心解法:Watermark + Allowed Lateness + Side Output + 外部 Upsert 存储/数据湖
我会将处理流程分为四个层级,逐步剥离不同程度的迟到数据,既释放 Flink 的 State 压力,又保证数据的最终一致性。
第一级:Watermark(处理轻微乱序,保证准实时触发)
- 机制:设置一个较短的容忍时间(例如 5秒 ~ 1分钟),生成 Watermark。
- 作用:当 Watermark 越过窗口结束时间时,窗口第一次触发计算并输出结果。
- 收益:满足业务“不能让窗口等太久”的要求,绝大多数按时或轻微网络延迟的数据能迅速得到计算和反馈。
第二级:Allowed Lateness(处理中度迟到,更新窗口结果)
- 机制:使用
allowedLateness(Time.minutes(30))或最多几个小时(具体取决于数据量和 State Backend 的容量)。 - 作用:窗口在第一次触发后,其 State 不会立刻销毁。在这 30 分钟内到达的迟到数据,会再次进入该窗口,触发窗口的重新计算,并发出一条更新(Update)结果。
- 限制:绝对不能将
allowedLateness设置为几天,否则 Flink 需要在 State 中保留过去几天所有窗口的聚合数据,会导致严重的 State 膨胀。
第三级:Side Output(兜底极端迟到,确保数据零丢失)
- 机制:使用
sideOutputLateData(OutputTag)。 - 作用:当迟到时间超过了
allowedLateness(例如迟到了 3 天),窗口的状态已经被彻底销毁。此时 Flink 会自动把这些数据打入侧输出流(Side Output)。 - 收益:满足“不能丢弃迟到数据”的要求,同时 Flink 内部不需要为这些极端数据维持任何历史窗口的状态。
第四级:外部存储聚合(解决侧输出流的合并问题)
这是解决“数天迟到数据”最关键的一环。侧输出流的数据被拦截后,需要与之前已经输出的早期结果进行合并。
- 方案 A:利用支持 Upsert / 累加的外部数据库(适用于实时看板)
- 将 Flink 的主输出流(第一次触发和 Allowed Lateness 触发的修正)写出到 Redis、HBase、MySQL 或 ClickHouse 等支持按主键更新的数据库中。
- 将侧输出流(迟到几天的数据)写一个单独的处理逻辑:将其转化为对外部数据库的增量更新(Delta Update)。例如,执行一条 SQL:
UPDATE table SET count = count + 1 WHERE window_time = '2023-10-25 10:00:00'。
- 方案 B:基于数据湖的 Lambda/Kappa 架构(适用于离线对账和精确报表)
- 将侧输出流直接 Sink 到 Iceberg、Hudi 等数据湖的对应时间分区中。
- 利用数据湖的行级更新能力(MOR)合并迟到数据,或者通过定时的批处理任务(Batch Job)重写那些因数据迟到而发生改变的历史分区数据。
代码伪逻辑示例
java
// 1. 定义侧输出流 Tag
final OutputTag<Event> lateDataTag = new OutputTag<Event>("late-data"){};
// 2. 核心窗口逻辑组合
SingleOutputStreamOperator<Result> mainStream = stream
// 第一级:Watermark 容忍 5 秒乱序
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
)
.keyBy(Event::getKey)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
// 第二级:Allowed Lateness 容忍 1 小时以内的迟到数据,状态保留 1 小时
.allowedLateness(Time.hours(1))
// 第三级:超过 1 小时的极端迟到数据,打入侧输出流
.sideOutputLateData(lateDataTag)
.aggregate(new MyAggregateFunction(), new MyWindowFunction());
// 3. 获取主流并写入外部 Upsert 存储
mainStream.addSink(new UpsertDatabaseSink());
// 4. 获取侧输出流,处理极端迟到数据
DataStream<Event> lateStream = mainStream.getSideOutput(lateDataTag);
lateStream
// 将迟到数据转换为增量更新操作,直接打入外部数据库修正历史结果
.map(new MapFunction<Event, UpdateRequest>() { ... })
.addSink(new ExternalDatabaseDeltaUpdateSink());总结与业务权衡
这种组合方案本质上是“将状态计算的压力进行了转移”:
- 短期的、高频的修正 交给 Flink 内存/RocksDB 处理(Watermark + Allowed Lateness),效率极高。
- 长期的、低频的极端修正 交给外部持久化存储(Side Output + DB/数据湖)处理,保证了系统的可扩展性和稳定性。
这样既完美实现了业务对时效性的要求,又保证了历史数据100%的完整性,是生产环境中解决长尾迟到数据的最佳实践。