 播面
播面 使用 Flink 做一个长期(如按月统计)的用户去重 UV 计算,随着时间推移 State 越来越大,如何利用 State TTL 或是其他机制防止状态无限制膨胀?
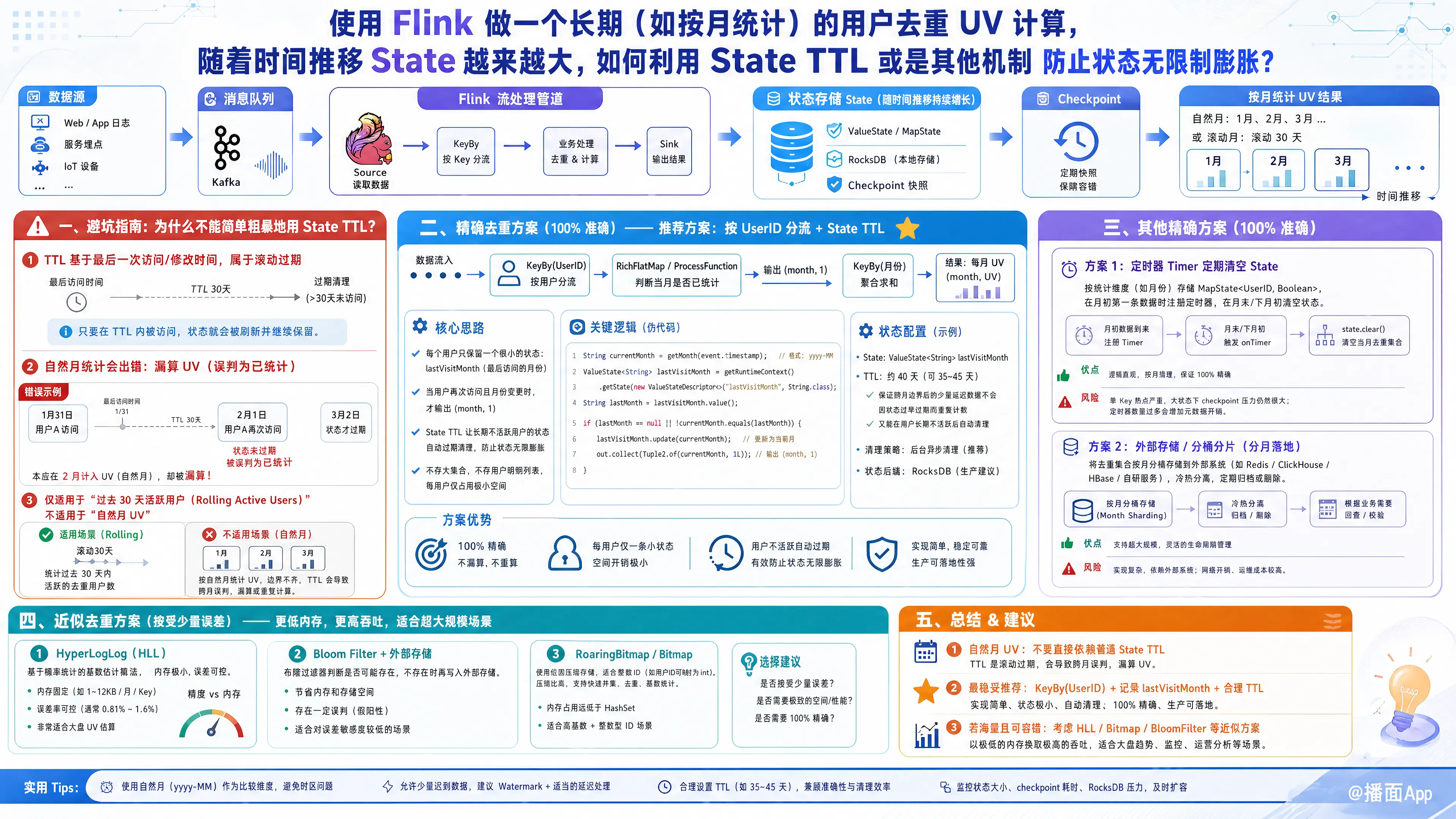
在 Flink 中进行长期(如自然月)的 UV(Unique Visitor,独立访客)计算,状态(State)无限制膨胀是一个非常经典的痛点。
如果你直接使用 Set 或 MapState 把所有的 UserID 存下来,到了月末,State 的大小会随着用户量呈线性()暴增,这会导致 Checkpoint 变慢、甚至 OOM 或任务崩溃。
针对这个问题,不能单纯依赖一种方法,而是要根据“是否需要 100% 精确”和“统计的是自然月还是滚动月”来选择方案。以下是几种业界最常用的破局思路:
一、 避坑指南:为什么不能简单粗暴地用 State TTL?
很多人的第一反应是给 State 设置一个 30 天的 TTL。但这对于“自然月(如1月1日-1月31日)”统计是错误的!
- 错误原因:Flink 的 State TTL 是基于最后一次访问/修改时间来计算的(滚动过期)。假设你在 1月31日 访问了,TTL 设为 30天,那么你的状态会保留到 3月2日。如果在 2月1日 你再次访问,系统会发现你的状态还在,把你当作“已经统计过”的旧用户,从而导致 2 月份的 UV 漏算。
- 适用场景:简单的 State TTL 只适用于计算“过去 30 天活跃用户(Rolling Active Users)”,不适合“自然月 UV”。
二、 精确去重方案(要求 100% 准确)
如果你必须做到 100% 精确,可以通过以下几种方式来控制 State 大小和生命周期。
1. 巧妙结合 State TTL 与“按用户分流” (推荐)
不要按照 KeyBy(平台/页面) 来存储所有用户的集合,而是按照 KeyBy(UserID) 进行分流。
- 思路:每个用户自己记录自己“这个月是否访问过”。
- 具体实现:
- 在
KeyedProcessFunction中,定义一个ValueState<String> lastVisitMonth,记录该用户最后一次访问的月份(如"2023-10")。 - 给这个 State 设置一个 40天 的 TTL(稍微大于一个月即可)。
- 当数据到来时:java
String currentMonth = "2023-10"; String lastMonth = lastVisitMonth.value(); if (!currentMonth.equals(lastMonth)) { // 这个月第一次来 lastVisitMonth.update(currentMonth); // 刷新状态和 TTL out.collect(Tuple2.of(currentMonth, 1L)); // 发送给下游进行简单的 sum 操作 } - 下游处理:下游按照
KeyBy(月份),直接做一个简单的.sum(1)即可。
- 在
- 为什么能防膨胀:State 中不存大集合,只存一个极小的字符串。如果一个用户下个月没来,40天后 TTL 会自动清理掉该用户的状态,完美防止死数据无限膨胀。
2. 定时器 (Timer) 定期清空 State
如果你采用的是 KeyBy(统计维度) 并在 State 中存 MapState<String, Boolean>(Key 为 UserID)。
- 思路:在每个自然月的第一条数据到来时,注册一个月末最后一秒的 EventTime Timer(或 ProcessingTime Timer)。
- 具体实现:当时间到达下个月 1 号 00:00:00 时,触发
onTimer方法,在里面直接调用state.clear(),清空上个月的所有去重数据。 - 缺点:虽然月末会清空,但在月末的那几天,State 依然会达到本月的峰值。
3. 使用 RoaringBitmap (咆哮位图) 压缩 State
如果你的 UserID 是整数(或者可以通过 Hash 转成整数且无冲突),绝对不要用 Set,改用 RoaringBitmap。
- 优势:极大地压缩连续或稀疏的整型数组,内存占用通常只有原生
Set的 1%~10%。 - 实现:将
ValueState<byte[]>作为状态,里面存储序列化后的RoaringBitmap。每次有新用户,反序列化 -> 添加ID -> 序列化存回。结合 Timer 在月末清空。
三、 近似去重方案(业界大数据常规做法)
在绝大多数真实业务中,长周期的 UV 计算不需要 100% 精确,允许有 1% 左右的误差。此时使用概率数据结构是彻底解决 State 膨胀的最佳方案。
1. HyperLogLog (HLL)
HyperLogLog 是统计基数(Cardinality)的核武器。Redis 的 UV 统计底层就是用的它。
- 原理:利用 Hash 算法中的前导零概率来估算数据量。
- 优势:无论你有 1 万个用户还是 10 亿个用户,一个 HLL 对象在内存中只占用 12KB 的固定大小!State 永远不会膨胀。
- 实现:
- 引入开源库(如
Clearspring的stream-lib或 Algebird)。 - Flink State 定义为
ValueState<byte[]>,存 HLL 的字节序列。 - 每来一条数据,将其加入 HLL,然后输出 HLL 估算出的最新 UV 值。
- 同样配合月末 Timer 来
clear()。
- 引入开源库(如
2. Bloom Filter (布隆过滤器)
如果下游不仅需要总数,还需要根据“是否是新用户”做其他业务逻辑,可以使用 Bloom Filter。
- 原理:一个很大的 Bit 数组 + 多个 Hash 函数。
- 实现:将 Bloom Filter 的 Bit 数组存在 Flink 的 State 中。判断不在里面,则输出 +1,并存入 Bloom Filter。
- 缺点:相比 HLL,Bloom Filter 会大一些(通常几 MB 到几十 MB,取决于你设置的预期数据量和误差率),并且不支持删除操作,必须每个月重新建一个。
四、 架构层面的外部化 (Off-heap)
如果业务要求 100% 精确,且数据量大到 Flink 甚至无法承受优化后的 State:
1. 外部存储去重 (Redis / HBase / Doris)
- 不要把明细状态存在 Flink 内部。
- Flink 只做数据清洗,然后通过 Async I/O (异步 IO) 去查询 Redis。
- Redis 里可以通过
SETBIT(按天/月拼接 Key) 来记录某用户是否访问过。 - 利用 Redis 自带的过期机制(TTL)来清理每个月的 Key。
2. OLAP 引擎去重 (推荐现代架构)
- Flink 完全不做去重,只做基础的清洗和实时入库。
- 把明细数据打入 ClickHouse、Doris 或 StarRocks 等现代 OLAP 引擎。
- 利用这些引擎内部的
count(distinct uid)或者自带的 Bitmap/HLL 物化视图功能,由前端业务发起 SQL 直接查询实时 UV。
总结与建议
- 首选架构:如果是现代大数据平台,推荐 Flink 只洗数据 + Doris/ClickHouse 等 OLAP 引擎做实时聚合去重。
- 允许误差:直接在 Flink 中使用 HyperLogLog + 月末 Timer 清理 State。
- 必须 100% 精确且纯 Flink 实现:采用 KeyBy(UserID) + ValueState<上一次访问月份> + 40天 State TTL(上文的精确方案一),再由下游做 Sum。
- 基建配置:只要涉及到去重计算,请务必把 Flink 的 State Backend 切换为 RocksDB,并开启增量 Checkpoint (
state.backend.incremental: true),不要用默认的内存 State Backend。