 播面
播面 系统有一批业务规则保存在 MySQL 中,需要实时更新并下发到 Flink 所有的处理节点去匹配流数据。这种场景如何利用广播状态实现,有什么坑?
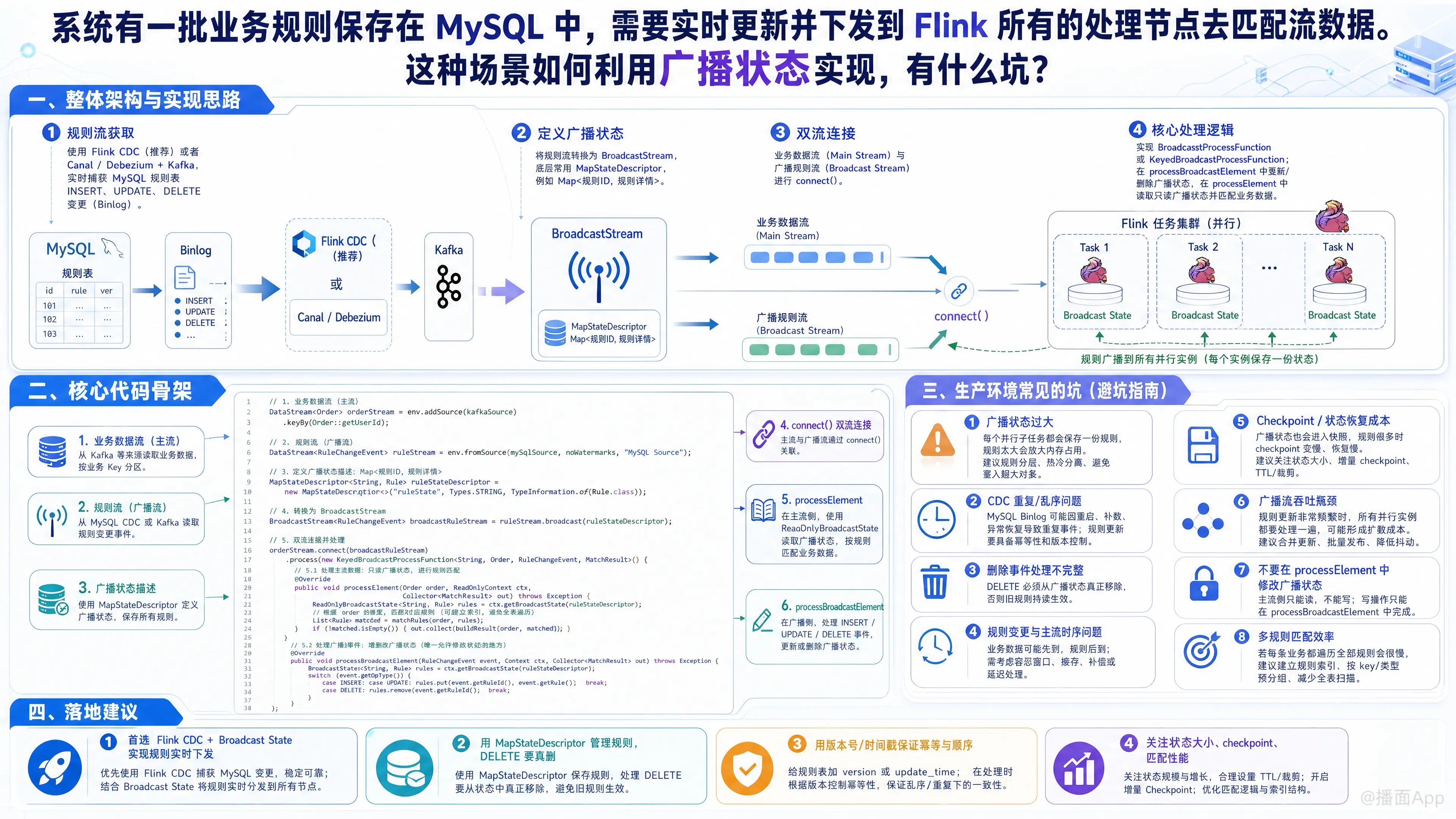
在 Flink 中,将 MySQL 中的业务规则实时下发到所有处理节点去匹配流数据,是 Broadcast State(广播状态) 的最经典应用场景。
下面我将从架构设计、代码实现步骤,以及生产环境中常见的坑(避坑指南)三个方面为你详细解答。
一、 整体架构与实现思路
- 规则流获取:使用 Flink CDC(推荐)或者 Canal/Debezium + Kafka,实时捕获 MySQL 中规则表的
INSERT、UPDATE、DELETE变更(Binlog)。 - 定义广播状态:将规则流转换为
BroadcastStream,底层数据结构通常是MapStateDescriptor(例如Map<规则ID, 规则详情>)。 - 双流连接:将 业务数据流(Main Stream) 与 广播规则流(Broadcast Stream) 进行
.connect()。 - 核心处理逻辑:实现
BroadcastProcessFunction或KeyedBroadcastProcessFunction。- 在
processBroadcastElement中:接收 MySQL 变更,更新/删除广播状态。 - 在
processElement中:读取业务数据,从只读广播状态中获取最新规则进行匹配。
- 在
二、 核心代码骨架
以下是基于 Flink CDC 和 KeyedBroadcastProcessFunction 的伪代码实现:
java
// 1. 业务数据流 (主数据流)
DataStream<Order> orderStream = env.addSource(kafkaSource).keyBy(Order::getUserId);
// 2. MySQL 规则流 (使用 Flink CDC)
DataStream<Rule> ruleStream = env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
.map(new MapFunction<String, Rule>() {
// 解析 CDC 的 JSON 数据,提取增删改标识 (RowKind) 和规则内容
});
// 3. 定义广播状态描述符
MapStateDescriptor<String, Rule> ruleStateDescriptor = new MapStateDescriptor<>(
"rule-broadcast-state",
BasicTypeInfo.STRING_TYPE_INFO,
TypeInformation.of(Rule.class)
);
// 4. 将规则流广播出去
BroadcastStream<Rule> broadcastRuleStream = ruleStream.broadcast(ruleStateDescriptor);
// 5. 连接双流并处理
SingleOutputStreamOperator<String> resultStream = orderStream
.connect(broadcastRuleStream)
.process(new KeyedBroadcastProcessFunction<String, Order, Rule, String>() {
// 处理主流数据 (业务数据)
@Override
public void processElement(Order order, ReadOnlyContext ctx, Collector<String> out) throws Exception {
// 注意:这里只能获取 ReadOnlyBroadcastState,不能修改规则
ReadOnlyBroadcastState<String, Rule> ruleState = ctx.getBroadcastState(ruleStateDescriptor);
// 遍历/匹配规则
for (Map.Entry<String, Rule> entry : ruleState.immutableEntries()) {
Rule rule = entry.getValue();
if (match(order, rule)) {
out.collect("Order: " + order.getId() + " matched Rule: " + rule.getId());
}
}
}
// 处理广播流数据 (规则变更)
@Override
public void processBroadcastElement(Rule rule, Context ctx, Collector<String> out) throws Exception {
BroadcastState<String, Rule> ruleState = ctx.getBroadcastState(ruleStateDescriptor);
// 根据 CDC 的操作类型 (INSERT/UPDATE/DELETE) 更新状态
if ("DELETE".equals(rule.getOpType())) {
ruleState.remove(rule.getId());
} else {
ruleState.put(rule.getId(), rule);
}
}
});三、 生产环境有哪些“坑”?(避坑指南)
在实际生产中使用广播状态,有几个非常经典的痛点,必须提前防范:
1. 冷启动问题(数据比规则先到)
- 现象:Flink 任务刚启动时,MySQL 中的全量规则还在拉取中,但业务数据流已经开始进入
processElement。此时广播状态为空,导致前期的业务数据漏匹配规则。 - 解决方案:
- 方案 A(阻塞主流):在
processElement中判断规则状态是否为空,如果为空,则将业务数据暂时放入ListState缓存,等规则加载完毕(可以加一个特定标记规则)后再处理。 - 方案 B(优先拉取规则):目前 Flink CDC 不支持先跑完 Snapshot 再消费其他 Source。但可以通过拆分作业,或者在启动 Flink 任务前,先通过外部接口/Redis 把历史规则全量加载到内存,CDC 只负责增量。
- 方案 C(容忍并侧输出):如果业务允许,对没有匹配到规则的数据打上标签,写入 Side Output (侧输出流),事后做离线补偿。
- 方案 A(阻塞主流):在
2. 广播状态内存 OOM (Out Of Memory)
- 现象:广播状态是保存在 TaskManager 的 Heap 内存中的。即使你配置了 RocksDB 状态后端,广播状态也不会存在 RocksDB 里。如果 MySQL 中的规则表极大(比如几十万条、几百 MB),会导致 TM 直接 OOM。
- 解决方案:
- 广播状态只适合小数据量(通常 MB 级别)。
- 如果规则表极其庞大,不能使用广播状态。应该改用:Async I/O (异步查询 Redis/HBase/MySQL) 或 Lookup Join (维表 Join)。
- 精简规则:只查出当前业务需要的字段,避免把无用的超长字符串加载到状态里。
3. 各节点规则更新的并发不一致性
- 现象:
processBroadcastElement在各个 Task 之间是独立并行触发的。由于网络等原因,Task A 可能在 10:00:01 收到新规则,而 Task B 在 10:00:02 才收到。在这 1 秒的时间差内,不同节点处理相同数据的逻辑是不一致的。 - 解决方案:
- 业务层面需要容忍这种毫秒级到秒级的不一致。因为这是 Processing Time 语义下的正常现象。
- 如果要求绝对的全局一致性(极度严苛场景),通常需要引入带有 Event Time Watermark 的规则流,并在处理逻辑中对齐时间,但这会极大增加系统复杂度,一般不推荐。
4. processElement 中严禁修改广播状态
- 现象:新手常犯的错误,试图在处理主流数据时
put或remove广播状态。 - 原因:为了保证 Flink Checkpoint 的一致性,各个 Task 中的广播状态必须完全相同。主流数据是被 keyBy 打散分配到特定 Task 的,如果在主流里修改规则,会导致 Task 之间的规则状态产生分歧(Divergence),后续 Checkpoint 恢复时会导致灾难性错误。
- 结论:
processElement提供的 Context 是ReadOnlyContext,强行转换或使用反射修改会报错。只有processBroadcastElement才能修改状态。
5. Checkpoint 状态倾斜/放大问题
- 现象:Checkpoint 保存时,所有的并发 Task 都会将自己内存中的广播状态写入 HDFS。如果并行度是 100,一份 10MB 的规则会被保存 100 份。
- 机制说明:实际上 Flink 做了优化,在进行 Checkpoint 时,只有并发度为 0 的 Subtask(即第一个 Task)会将 Broadcast State 写入快照。但在恢复(Restore)时,该快照会被分发给所有的 Subtask。所以快照大小不是问题,但反序列化恢复时的瞬间 CPU/内存开销需要注意。
6. 软删除 (Soft Delete) 处理
- 现象:业务在 MySQL 中删除了规则,但使用的是伪删除(如
is_deleted = 1)。如果 CDC 直接把这条数据发给 Flink,Flink 默认当成UPDATE处理。 - 解决方案:在 CDC 的解析逻辑或者
processBroadcastElement中,务必识别业务上的“软删除”字段。如果是软删除,必须调用ruleState.remove(ruleId)把规则从内存彻底清掉,否则废弃规则越堆越多,迟早 OOM。