 播面
播面 在遇到了严重的数据背压(Backpressure)时,Checkpoint 的 Barrier 无法传递导致完全卡死,开启 Unaligned Checkpoint 后会有什么副作用?
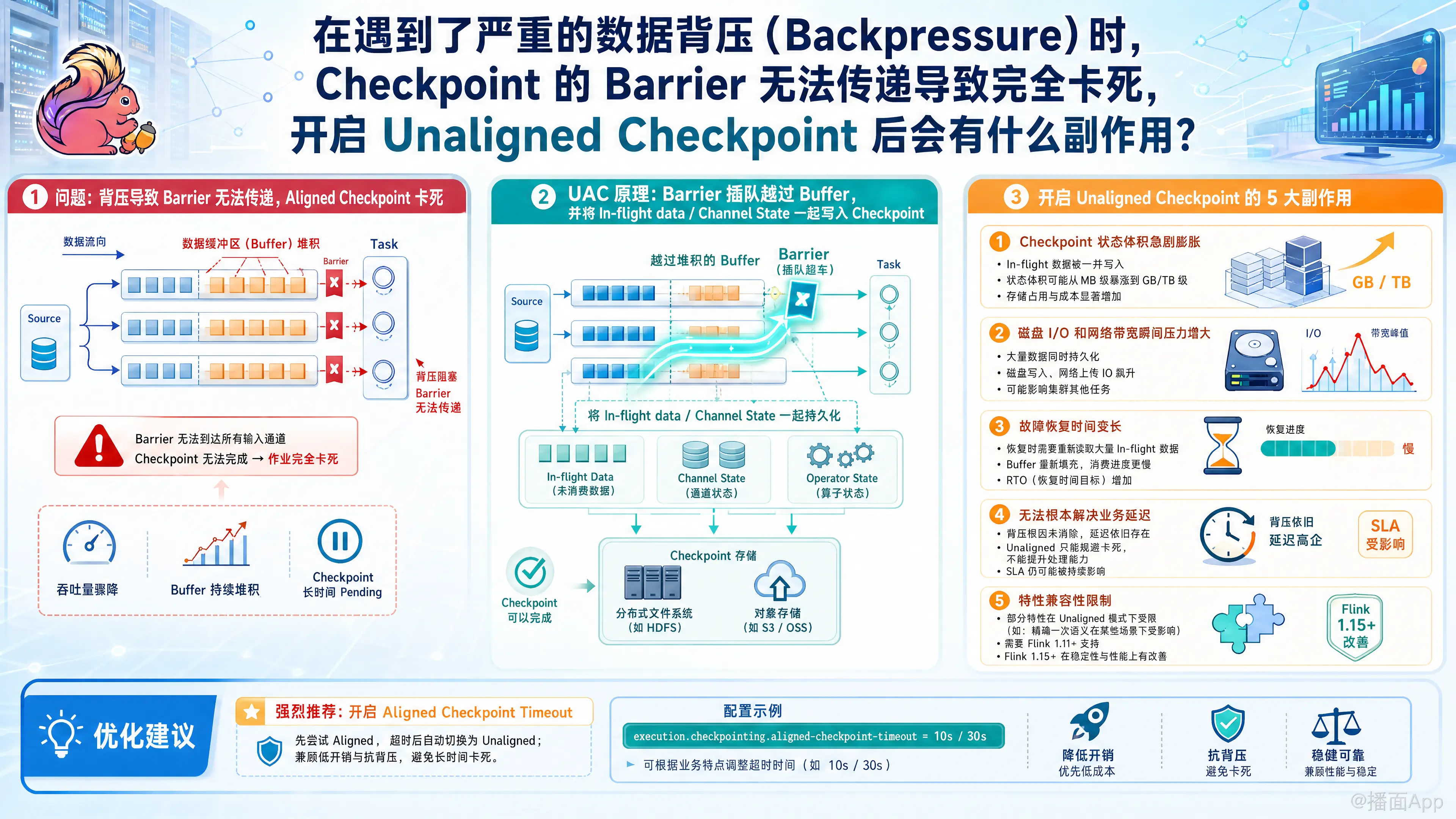
在 Flink 中,当你遇到严重的数据背压导致 Checkpoint Barrier 被阻塞(Aligned Checkpoint 的机制要求 Barrier 必须随着数据流移动),进而导致 Checkpoint 频繁超时甚至卡死时,开启 Unaligned Checkpoint (UAC) 是官方推荐的破局方案。
UAC 的核心原理是:让 Barrier “插队”越过那些堆积在 Buffer 中的数据,同时把这些被越过的数据(In-flight data / Channel State)也一起保存到 Checkpoint 状态中。
虽然它能有效解决背压下的 Checkpoint 卡死问题,但这并不是没有代价的。开启 UAC 会带来以下几个显著的副作用和潜在影响:
1. Checkpoint 状态体积急剧膨胀(最主要的副作用)
- 原因:传统的对齐 Checkpoint 只保存算子内部的 State。而 UAC 为了保证 Exactly-Once,必须把输入缓冲区(Input Buffers)和输出缓冲区(Output Buffers)中积压的大量数据也作为状态的一部分写入到分布式存储(如 HDFS/S3)中。
- 影响:在严重背压下,缓冲区通常是满载的。如果你的并发度很高,或者网络 Buffer 配置得很大,每次 Checkpoint 可能会额外增加 GB 级别的数据量。这会导致存储成本增加。
2. 磁盘 I/O 和网络带宽的瞬间压力增大
- 原因:因为 Checkpoint 的体积变大了,TaskManager 需要将大量的缓冲区数据序列化并异步上传到 State Backend(分布式文件系统)。
- 影响:这会占用本就可能因为背压而紧张的网络带宽,并对底层存储系统造成 I/O 尖峰。如果底层的 HDFS/S3 响应变慢,反而可能进一步影响 TaskManager 的性能。
3. 故障恢复(Recovery)时间变长
- 原因:当作业失败重启并从 UAC 恢复时,Flink 不仅要恢复算子状态,还要把庞大的缓冲区数据重新填充回 Input/Output Buffer 中。
- 影响:这会导致作业启动后的初始化阶段变长(RTO 增加)。并且在恢复初期,由于 Buffer 瞬间被填满,作业可能会立刻再次进入背压状态,出现一个“启动慢、处理慢”的冷启动期。
4. 无法根本解决业务延迟(治标不治本)
- 影响:UAC 只是保证了在极端背压下 Checkpoint 依然能成功,从而保证了容错性。但是,背压依然存在。你的数据处理延迟依然很高,算子依然跑不动。如果没有从根本上解决背压(如增加资源、解决数据倾斜、优化慢 Sink 等),业务的 SLA(如数据实时性)依然是无法满足的。
5. 对部分特性的兼容性限制(视 Flink 版本而定)
- 在早期版本中,UAC 与某些特性(如并发 Savepoint、Broadcast State 的某些场景、或者 Iteration 迭代计算)存在兼容性问题。不过 Flink 1.15 及以上版本对这些限制已经做了大量修复和完善。
给你的优化建议(如何减轻 UAC 的副作用)
如果你决定开启 UAC,强烈建议搭配以下配置一起使用,以达到“既能扛住背压,又尽量减少副作用”的完美状态:
💡 绝招 1:开启 Aligned Checkpoint Timeout(对齐超时退化机制)
强烈推荐。不要一上来就强制全局使用 UAC。
配置 execution.checkpointing.aligned-checkpoint-timeout(例如设为 10s 或 30s)。
- 效果:Flink 每次 Checkpoint 开始时,依然尝试使用无副作用的 Aligned Checkpoint。如果背压不严重,10秒内对齐成功了,就不产生额外开销;如果背压严重,10秒内 Barrier 还没对齐,Flink 会自动切换为 Unaligned Checkpoint,让 Barrier 插队通过。
- 这完美结合了两者的优点。
💡 绝招 2:开启 Buffer Debloating(缓冲区去胀)
从 Flink 1.14 开始引入的抗背压神器。
配置 taskmanager.network.memory.buffer-debloat.enabled: true。
- 效果:它会根据算子当前的处理速度,动态缩小网络缓冲区的大小(保证 Buffer 里只存放比如 1 秒内能处理完的数据量)。
- 对 UAC 的意义:因为 Buffer 被动态缩小了,即使开启 UAC 保存 Channel State,被插队的数据量也会呈指数级下降,彻底解决了 UAC 导致状态体积暴增和恢复慢的问题。
总结
开启 UAC 就像是给拥堵的高速公路开启了“应急车道让救护车(Barrier)先走”,代价是救护车必须把沿途堵车的车牌号(Buffer 数据)全记下来。
副作用主要是:状态变大、I/O 增加、恢复变慢。
最佳实践:Unaligned Checkpoint Timeout + Buffer Debloating 组合拳,并且一定要去排查造成背压的根本原因(如代码逻辑慢、Sink 端阻塞、数据倾斜等)。