 播面
播面 业务逻辑变更,需要给现有的 Flink 拓扑中增加或者删除某个算子,如何保证重启后原本的 State 数据能够正确映射并恢复?
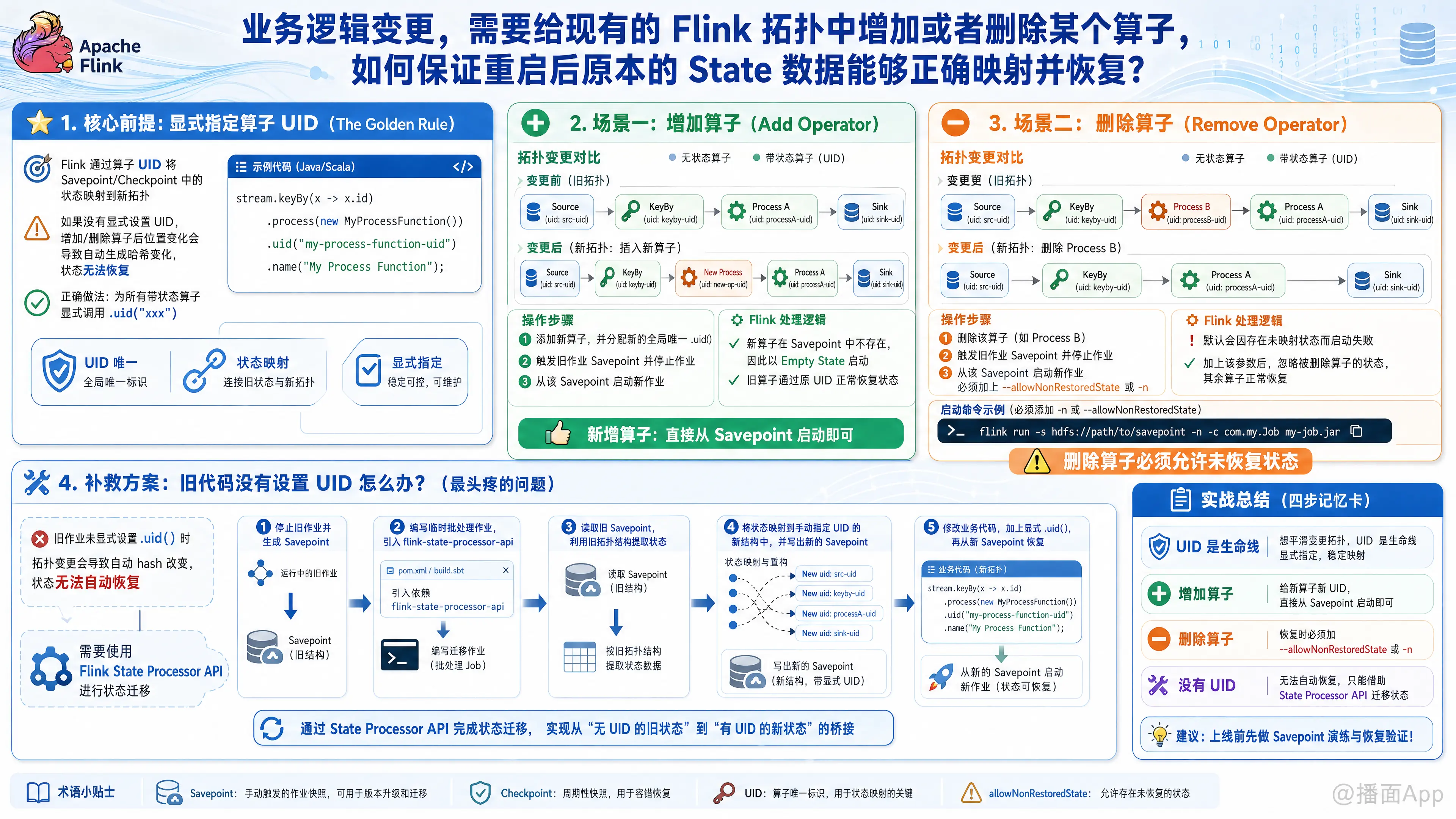
在 Flink 中,业务逻辑变更导致拓扑结构改变(增加或删除算子)是生产环境中的常见需求。为了保证重启后原本的 State 数据能够正确映射并恢复,核心在于 算子标识(Operator UID) 的管理以及 启动参数 的配合。
以下是完整的解决方案和实操指南:
1. 核心前提:显式指定算子 UID(The Golden Rule)
Flink 是通过算子的 UID 来将 Savepoint/Checkpoint 中的状态数据映射到新拓扑中的算子上的。
- 如果没有显式设置 UID:Flink 会根据算子在拓扑中的位置自动生成哈希值作为 UID。一旦你增加或删除算子,后续所有算子的位置发生变化,自动生成的 UID 随之改变,导致状态完全无法恢复。
- 正确做法:在开发时,必须为所有带有状态的算子显式调用
.uid("xxx")。
java
// 示例:规范的写法
stream.keyBy(x -> x.id)
.process(new MyProcessFunction())
.uid("my-process-function-uid") // 必须指定唯一的 UID
.name("My Process Function");2. 场景一:增加算子 (Add Operator)
假设你在原有的拓扑中插入了一个新的算子。
- 操作步骤:
- 在代码中添加新算子,并 务必为其分配一个全新的、全局唯一的
.uid()。 - 触发一次旧作业的 Savepoint 并停止作业。
- 从该 Savepoint 启动新作业。
- 在代码中添加新算子,并 务必为其分配一个全新的、全局唯一的
- Flink 的处理逻辑:
Flink 读取 Savepoint 时,发现新算子的 UID 在 Savepoint 中不存在。此时,Flink 会正常启动,并将新算子的初始状态视为空(Empty State)。原有算子通过旧的 UID 正确认领自己的状态。 - 注意事项:无特殊要求,直接从 Savepoint 启动即可。
3. 场景二:删除算子 (Remove Operator)
假设你从代码中删除了某个带有状态的算子。
- 操作步骤:
- 在代码中删除该算子。
- 触发一次旧作业的 Savepoint 并停止作业。
- 从该 Savepoint 启动新作业,必须加上
--allowNonRestoredState(或-n) 参数。
- Flink 的处理逻辑:
默认情况下,Flink 为了防止用户意外丢失状态,如果 Savepoint 中存在某个 UID 的状态,但在新拓扑中找不到对应的算子,作业启动会报错并失败。
加上--allowNonRestoredState参数后,Flink 会忽略 Savepoint 中无法映射的状态(即被删除算子的状态),原有保留的算子依然通过 UID 正常恢复状态。 - 启动命令示例:bash
flink run -s hdfs://path/to/savepoint -n -c com.my.Job my-job.jar
4. 补救方案:如果旧代码没有设置 UID 怎么办?
这是生产环境中最头疼的问题。如果旧作业没有显式设置 .uid(),增加或删除算子会导致拓扑哈希改变,状态无法自动恢复。你需要使用 Flink State Processor API 进行状态迁移。
- 补救步骤:
- 停止旧作业并生成 Savepoint。
- 编写一个临时的 Flink 批处理作业,引入
flink-state-processor-api依赖。 - 读取旧的 Savepoint,利用旧的拓扑结构(自动生成的 hash)提取出状态。
- 将提取出的状态,映射到手动指定了 UID 的新结构中,并写入一个新的 Savepoint。
- 修改业务代码,加上显式的
.uid(),然后从上一步生成的“新 Savepoint”启动作业。
5. 其他重要注意事项(避坑指南)
- 算子链(Operator Chaining)的影响:
算子链的改变(例如使用了.disableChaining())通常不会影响状态恢复,前提是你为每个状态算子分配了独立的 UID。 - 最大并行度(Max Parallelism)不可变:
修改拓扑时,千万不要改变作业或算子的最大并行度(Max Parallelism)(注意:不是并行度 Parallelism,而是 Max Parallelism)。Keyed State 的数据是根据 Max Parallelism 划分 Key Group 的,一旦改变,Savepoint 将完全作废。 - 状态数据结构(Schema)的变更:
如果你不仅增加了算子,还修改了原有算子中 State 的数据结构(例如给 POJO 增加了一个字段),你需要确保 Flink 的序列化器支持 Schema Evolution(通常只要使用的是标准的 POJO 或 Avro,并且没有改变原有字段的类型,Flink 就能自动兼容)。
总结 Checklist:
- 检查所有有状态的算子是否都有显式的
.uid()。 - 新增算子必须配置未被使用过的新 UID。
- 删除算子重启时,命令行加上
-n或--allowNonRestoredState。 - 确保未修改
Max Parallelism配置。