 播面
播面 一个状态达到几十 GB 的 Flink 任务挂掉后,通过 Checkpoint 重启需要花费十分钟甚至更久,如何优化状态恢复速度?
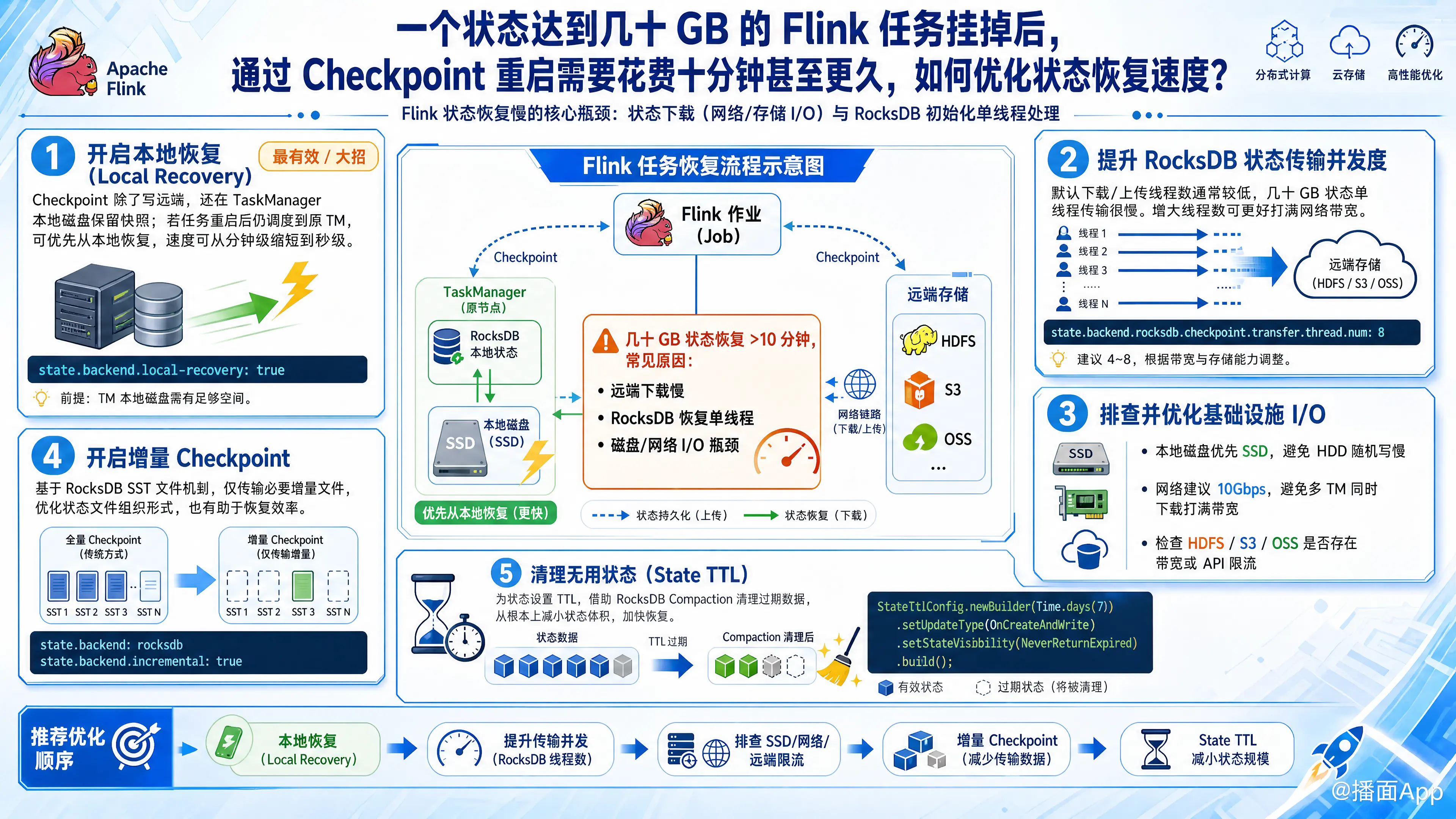
几十 GB 的状态在 Flink 中属于中等规模,恢复时间长达 10 分钟以上,通常是因为状态下载(网络/存储 I/O 瓶颈)或 RocksDB 初始化单线程处理导致的。
要优化状态恢复速度,可以从以下几个维度进行系统性调优。按照见效快慢和重要程度,建议采取以下措施:
1. 开启本地恢复(Local Recovery)—— 最有效的“大招”
原理:默认情况下,Flink 任务挂掉重启时,TaskManager (TM) 会从远端分布式存储(如 HDFS、S3)重新下载所有几十 GB 的状态文件,这会消耗大量网络带宽和时间。开启本地恢复后,每次 Checkpoint 除了写到远端,还会在 TM 本地磁盘保留一份快照。如果任务只是短暂崩溃(如代码逻辑异常、OOM),且被调度回原来的 TM 节点,Flink 会优先直接从本地磁盘加载状态,速度可以从几十分钟缩短到秒级。
配置方法:
# 开启本地恢复
state.backend.local-recovery: true注意:这要求你的 TaskManager 有足够的本地磁盘空间来存储至少一份完整的本地 Checkpoint。
2. 提升 RocksDB 状态传输的并发度
原理:默认情况下,RocksDB 在恢复状态时,从 HDFS/S3 下载文件是单线程的。对于几十 GB 的数据,单线程下载和文件句柄操作非常慢。增加传输线程数可以显著打满网络带宽,加快下载速度。
配置方法:
# 增加 RocksDB 状态下载和上传的线程数(默认是 1,建议设置为 4 到 8)
state.backend.rocksdb.checkpoint.transfer.thread.num: 83. 硬件与基础设施层面的排查与优化
如果开启了多线程下载依然很慢,需要检查底层的 I/O 瓶颈:
- 本地磁盘必须是 SSD:RocksDB 高度依赖本地磁盘 I/O。如果 TaskManager 使用的是普通机械硬盘(HDD),状态恢复时的随机写和合并操作会极其缓慢。
- 网络带宽:检查 TM 节点所在机器的网络带宽。如果多台 TM 同时从 HDFS 下载数据,可能会打满千兆网卡。建议使用万兆(10Gbps)网络。
- 远端存储限流:如果你的 Checkpoint 存在阿里云 OSS 或 AWS S3,检查是否触发了 API 频控或带宽限流。
4. 确保开启了增量 Checkpoint
原理:虽然增量 Checkpoint 主要优化的是“做 Checkpoint”的速度,但它也会影响状态文件的组织形式。开启增量后,底层基于 RocksDB 的 SST 文件机制,恢复时只需拉取必要的文件,而不是每次都处理一个巨大的全量文件。
配置方法:
# Flink 1.13+ 推荐配置
state.backend: rocksdb
state.backend.incremental: true5. 清理无用状态(设置 State TTL)
几十 GB 的状态中,是否有大量已经过期、永远不会再被访问的历史数据?
- 优化:为状态设置 TTL(Time-To-Live)。Flink 开启 TTL 后,会在 RocksDB 压缩(Compaction)时自动清理过期数据,从根本上减小状态体积,从而加快恢复速度。
- 代码示例:
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.days(7)) // 例如保留 7 天
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupInRocksdbCompactFilter(1000) // 开启 RocksDB 压缩时清理
.build();6. 避免在恢复时发生 Rescale(改变并发度)
如果你的任务重启是因为修改了代码并改变了并行度(Parallelism),那么 Flink 在恢复时无法直接原样加载状态,而是需要重新分配 Key-Group,重新合并和切分 RocksDB 的 SST 文件。这个过程(Rescaling)极其耗时。
- 建议:非必要不要在状态巨大的任务上频繁修改并行度。
- 预分配:在第一次建任务时,合理设置
pipeline.max-parallelism(最大并行度)。最大并行度一旦确定不能更改,它决定了状态切分的最小粒度(KeyGroup 的数量)。
7. 使用更新的技术:Changelog State Backend (Flink 1.15+)
如果你使用的是较新的 Flink 版本,可以尝试开启 通用增量 Checkpoint (Changelog State Backend)。
原理:它将状态变更不断写入到高可用的分布式日志中(类似 Kafka),大大缩短了 Checkpoint 的时间。在恢复时,它可以提供更细粒度的恢复机制,减少状态后处理的开销。
配置方法:
state.backend.changelog.enabled: true💡 总结与操作建议(Action Item)
如果你希望马上看到效果,请按以下步骤修改 flink-conf.yaml 并重启任务:
- 确认已开启增量:
state.backend.incremental: true - 开启多线程传输(见效极快):
state.backend.rocksdb.checkpoint.transfer.thread.num: 8 - 开启本地恢复(大幅降低非节点宕机导致的重启时间):
state.backend.local-recovery: true - 确认 TaskManager 的磁盘配置的是 SSD。
通常做完这几步,几十 GB 的状态恢复时间可以从 10 分钟以上压缩到 1~2 分钟以内甚至几十秒。