 播面
播面 生产环境某个大状态任务的 Checkpoint 耗时过长,甚至经常因为超时导致失败,你会从哪些维度排查并优化?
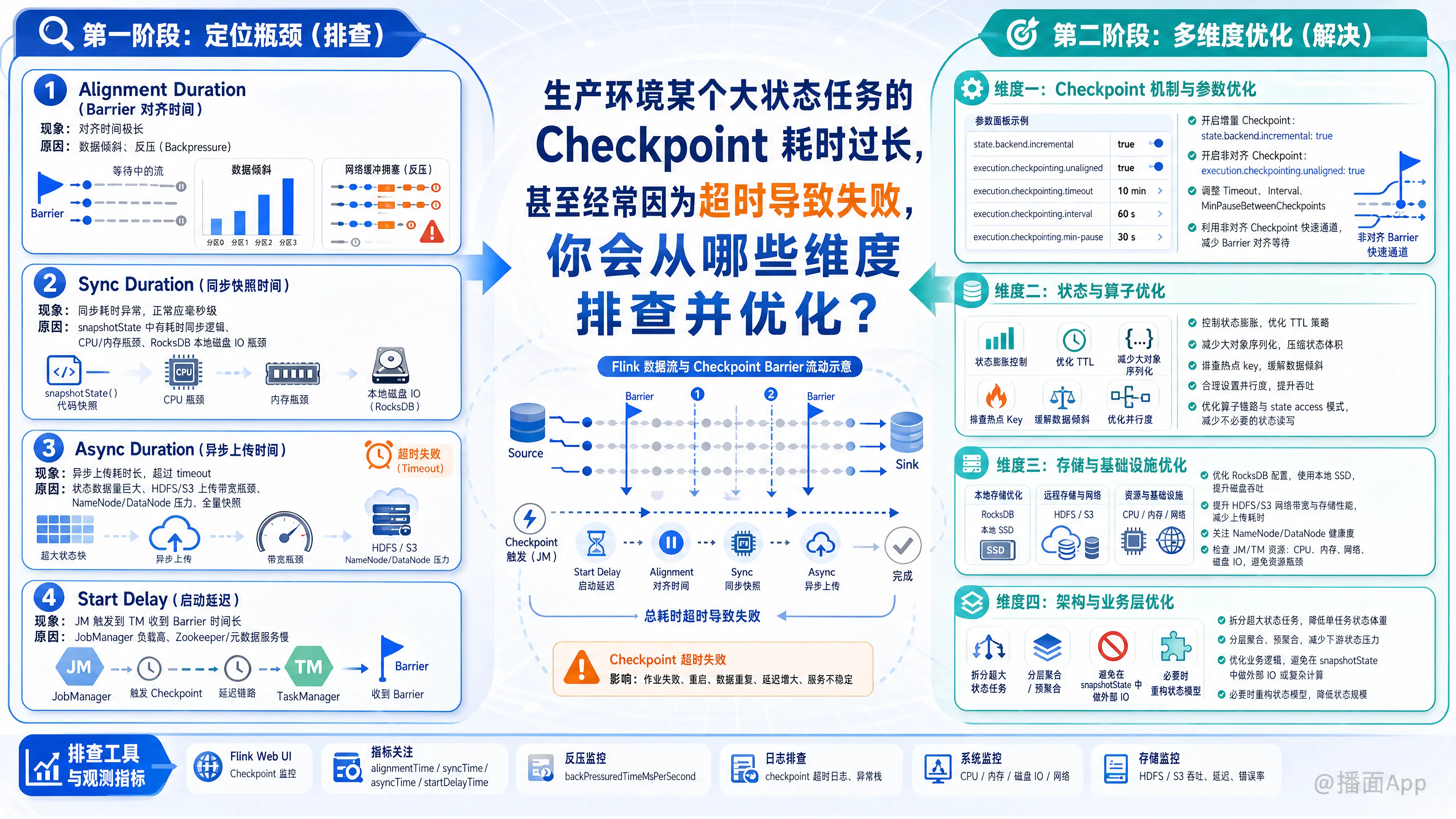
在生产环境中,Flink 大状态任务的 Checkpoint(CP)耗时过长或超时失败是一个非常经典且复杂的问题。排查和优化需要一套系统性的方法论。
作为一个有经验的开发者,我会从 “定位瓶颈(排查)” 和 “多维度优化(解决)” 两个大方向来处理这个问题。
第一阶段:定位瓶颈(通过 Flink Web UI 与监控排查)
Checkpoint 的整个生命周期可以拆分为多个阶段,第一步必须通过 Flink Web UI 的 Checkpoints -> History -> 具体某次 CP 查看详情,找出耗时最长的环节。
1. 排查 Alignment Duration(Barrier 对齐时间)
- 现象:对齐时间极长。
- 原因:
- 数据倾斜:某些 Subtask 处理极慢,导致其他 Subtask 一直在等待它的 Barrier。
- 反压(Backpressure):下游算子处理能力不足,导致 Barrier 随数据流被堵在网络缓冲区中,无法顺畅传递。
2. 排查 Sync Duration(同步快照时间)
- 现象:同步耗时超过几秒甚至几十秒(正常应在毫秒级别)。
- 原因:
- 主线程被阻塞:在
snapshotState方法中写了耗时的同步逻辑(如外部系统 IO 操作)。 - CPU 或 内存瓶颈:序列化/反序列化大对象极其耗费 CPU;如果是 RocksDB,可能是本地磁盘 IO 瓶颈导致卡顿。
- 主线程被阻塞:在
3. 排查 Async Duration(异步上传时间)
- 现象:异步耗时长,甚至超过设定的 timeout 时间。
- 原因:
- 状态极其庞大:单次 Checkpoint 数据量(Checkpointed Data Size)达到了几十 GB 甚至 TB 级。
- 网络或分布式存储瓶颈:上传状态到 HDFS/S3 的带宽被打满,或者 HDFS NameNode 响应慢、DataNode 负载过高。
- 全量快照:未使用增量 Checkpoint,每次都在全量上传。
4. 排查 Start Delay(启动延迟)
- 现象:JobManager 触发 CP 到 TaskManager 实际收到 Barrier 的时间很长。
- 原因:JobManager 负载过高,或者 Zookeeper/外部元数据服务响应慢。
第二阶段:多维度优化策略
根据上述排查出的瓶颈节点,我会从以下 4 个维度进行针对性优化:
维度一:Flink Checkpoint 机制与参数优化(见效最快)
- 开启增量 Checkpoint(必选项):
- 对于大状态任务,必须使用 RocksDB 且开启增量 CP:
state.backend.incremental: true。
- 对于大状态任务,必须使用 RocksDB 且开启增量 CP:
- 开启非对齐 Checkpoint(Unaligned Checkpoints):
- 如果瓶颈在 Alignment 阶段(反压严重),开启非对齐 CP 可以在 Barrier 到达时直接越过正在处理的数据,极大地缓解反压导致的 CP 超时。
- 参数:
execution.checkpointing.unaligned: true(注意:这会增加状态大小和恢复时间,但在高吞吐大状态下是救命稻草)。
- 调整 Checkpoint 触发间隔与超时时间:
- 如果 CP 耗时确实需要 5 分钟,而你的 Timeout 设为 3 分钟,必然失败。适当调大 Timeout 时间。
- 增大触发间隔(Interval):避免上一个 CP 刚做完,下一个马上开始,导致系统一直在做快照而影响业务吞吐。
- 设置
MinPauseBetweenCheckpoints:强制要求两次 CP 之间有最小间隔,让系统有时间处理业务数据。
维度二:RocksDB 状态后端调优(针对大状态核心)
大状态任务通常使用 RocksDB,如果配置不当会导致严重的本地 IO 瓶颈。
- 使用多目录/SSD 提升本地 IO:
- RocksDB 在工作时频繁进行本地磁盘的读写和 Compaction。强烈建议配置 SSD 盘。
- 配置多个本地目录分散 IO 压力:
state.backend.rocksdb.localdir: /data1/flink,/data2/flink。
- 增加后台线程数:
- 加快 RocksDB 的 Flush 和 Compaction 速度:
state.backend.rocksdb.thread.num(默认 1,建议调大到 4 或 8)。
- 加快 RocksDB 的 Flush 和 Compaction 速度:
- 内存管理调优:
- 如果是托管内存(Managed Memory)不足,适当调大 TaskManager 的
taskmanager.memory.managed.fraction比例。 - 如果有条件,可以通过开启 Write Buffer、Block Cache 等高级参数优化 RocksDB 的读写性能。
- 如果是托管内存(Managed Memory)不足,适当调大 TaskManager 的
维度三:业务逻辑与状态结构优化(治本之策)
状态为什么会大?很多时候是业务代码写得不够优雅。
- 设置状态的 TTL(生命周期):
- 最常见的问题:只往 State 里写,从来不清理。必须为 State 配置 TTL,自动清理过期数据。
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.days(1))...
- 优化数据结构:
- 避免在
ValueState中放一个巨大的List或Map。如果只更新 List 中的一个元素,会导致整个巨大的 List 被反序列化和序列化。 - 正确做法:使用
MapState或ListState,Flink 引擎底层(RocksDB)会有更好的追加和局部更新优化。
- 避免在
- 解决数据倾斜:
- 如果发现个别 Subtask 状态特别大,排查 Key 分布。
- 打散倾斜的 Key:增加随机前缀(Salting),采用“局部聚合 + 全局聚合”的两阶段聚合模式。
维度四:外部系统与硬件资源优化
- 提升 HDFS/S3 写入性能:
- 如果是 Async 阶段慢,且网络监控显示带宽未满,排查 HDFS。可能是 NameNode RPC 延迟高,或者写入的 DataNode 磁盘满载。
- 考虑调整 HDFS 客户端并发写参数,或换用更快的分布式存储。
- 网络与 CPU 资源:
- 扩容 TaskManager 的 CPU 核数,提升序列化/反序列化速度。
- 检查跨机房/跨可用区部署导致的网络长延迟问题。
总结排查路径(口诀):
先看 UI 找瓶颈 -> 对齐慢查倾斜反压开 UAC -> 同步慢查CPU磁盘换 SSD -> 异步慢查网络存储开增量 -> 状态大查业务代码加 TTL。 按照这个路径,基本能解决 99% 的 Flink Checkpoint 超时问题。