 播面
播面 业务系统中有一个“账户余额”或“库存数量”字段,更新频率极高,在这个字段上建立索引会有什么隐患?
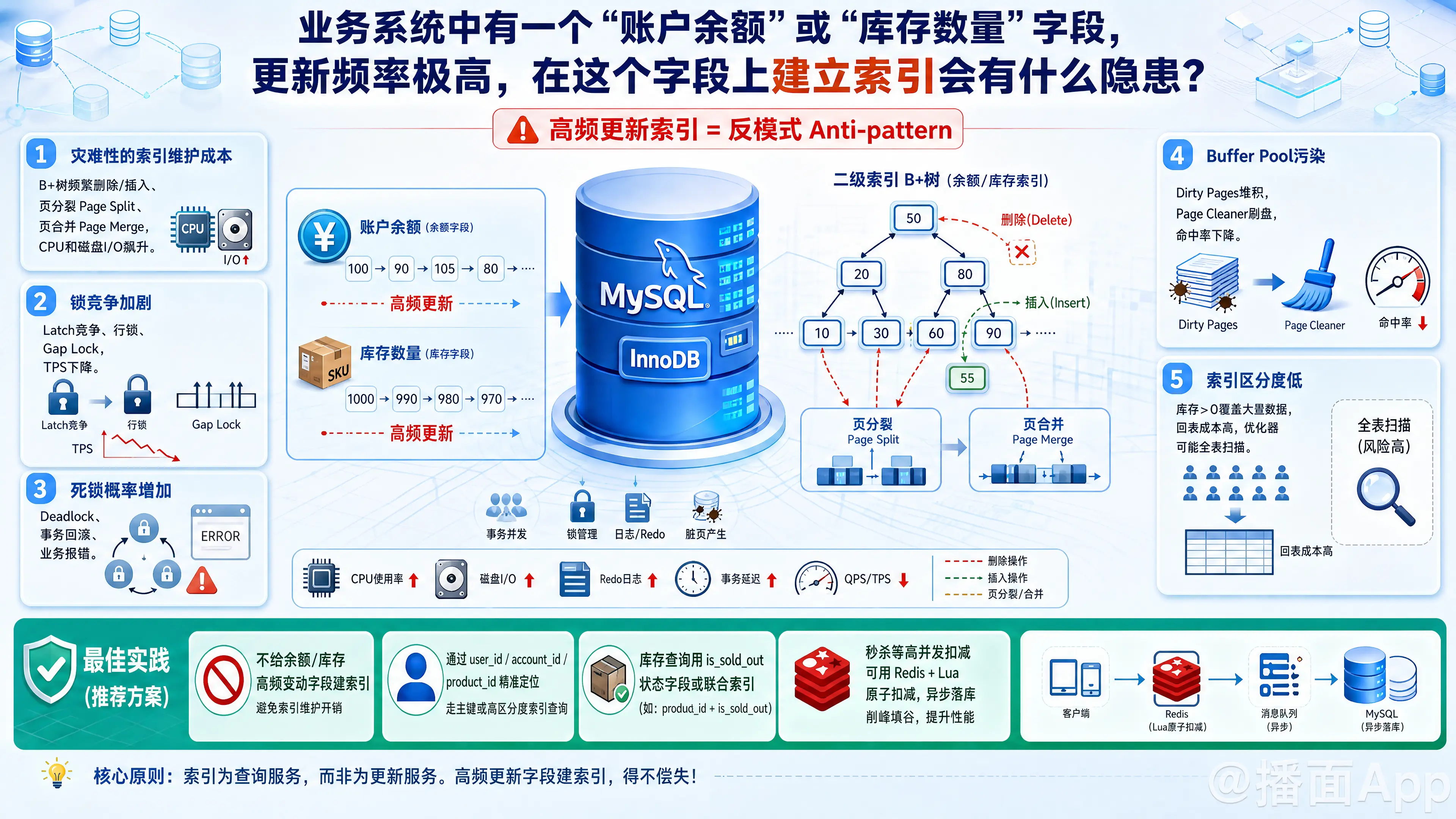
在MySQL(尤其是InnoDB存储引擎)的业务系统中,针对“账户余额”或“库存数量”这种更新频率极高的字段建立索引,是一个典型的反模式(Anti-pattern)。
这样做不仅对查询性能帮助极小,反而会引发严重的性能和并发问题。具体隐患主要体现在以下几个方面:
1. 灾难性的索引维护成本(B+树频繁重构)
- 原理:MySQL的二级索引(辅助索引)是通过B+树实现的。当你更新一个被索引的字段时,数据库不仅要更新聚簇索引(数据行本身),还要去更新对应的二级索引B+树。
- 隐患:余额或库存的更新通常是无序的(例如:100 -> 90 -> 105 -> 80)。在B+树中,这会导致对应索引项被频繁地删除和插入。这种高频的随机变动会引发大量的页分裂(Page Split)和页合并(Page Merge),消耗大量的CPU和磁盘I/O资源,导致整个Update语句的耗时成倍增加。
2. 锁竞争加剧与并发能力骤降
- 页级别锁(Latch)竞争:在InnoDB维护B+树结构(如进行页分裂)时,需要对索引页加Latch(一种底层的读写锁)。在高并发更新时,多个事务争抢同一个索引页的Latch,会导致严重的线程阻塞(Latch Contention),直接拖垮数据库的并发TPS。
- 行锁与间隙锁(Gap Lock):在可重复读(RR)隔离级别下,如果通过该索引进行范围查询或更新,MySQL可能会为了防止幻读而在索引上加上间隙锁。由于余额/库存值频繁变动,这些锁的范围也会频繁变动,极易造成大面积的阻塞。
3. 死锁概率显著增加
- 隐患:更新一条记录时,InnoDB需要先锁定聚簇索引,然后再去锁定并更新二级索引。在极高并发下,如果不同的事务以不同的顺序访问或修改数据,或者因为间隙锁的重叠,非常容易在二级索引的更新阶段触发死锁(Deadlock),导致事务回滚,业务报错。
4. Buffer Pool(缓冲池)污染,浪费内存
- 隐患:InnoDB会将经常访问的数据和索引页缓存在内存的 Buffer Pool 中。由于余额/库存索引被极高频地修改,这些二级索引页会变成大量的“脏页(Dirty Pages)”,占据了宝贵的内存空间。
- 后果:这不仅迫使后台线程(Page Cleaner)拼命刷脏页占用I/O,还会把真正有用的查询数据(如用户信息、商品详情)挤出 Buffer Pool,导致整体系统的读取命中率下降。
5. 极低的“索引区分度”,查询时大概率用不上
- 隐患:为什么要建索引?通常是为了快速检索。但是,我们极少会有这样的查询需求:“请找出余额正好是 123.45 的用户”。
- 范围查询失效:你可能会说,我想查询“库存 > 0”的商品。但是,在一个正常的电商系统中,“库存 > 0”的商品可能占了总数据量的 80% 以上。MySQL优化器在评估时,发现走二级索引还要进行大量的“回表”操作,成本太高,最终大概率会直接放弃使用该索引,选择全表扫描。建了索引也是白建。
💡 架构与业务层面的正确做法(最佳实践)
针对余额和库存字段,正确的处理方式如下:
- 坚决不加索引:直接去掉该字段上的索引。查询商品或账户时,一律通过
user_id、account_id或product_id(主键或唯一索引)去精准定位数据行。 - 状态字段分离(针对库存 > 0 的查询):
- 如果你确实需要高频查询“有货/无货”状态,不要用
WHERE inventory > 0。 - 应该增加一个状态字段,比如
is_sold_out(是否售罄,0-有货,1-无货)。当库存扣减到 0 的瞬间,将该字段更新为 1。 - 如果需要,可以在
is_sold_out上建索引,或者结合其他条件建立联合索引。
- 如果你确实需要高频查询“有货/无货”状态,不要用
- 高并发扣减优化:
- 缓存前置:极高并发的库存扣减(如秒杀),应该在 Redis 中利用 Lua 脚本进行原子扣减,然后再异步/批量落盘到 MySQL。
- 库存分桶(Slot):将一个热点商品的库存拆分成多条记录(如分成 10 个桶,每个桶 100 个库存),分散行锁的竞争。
- SQL合并/批量提交:在业务侧合并对同一账户/商品的频繁更新请求。