 播面
播面 在一张几千万记录的InnoDB表中,频繁需要执行 SELECT COUNT(*) 获取总数,性能很差,有什么替代方案或优化手段?
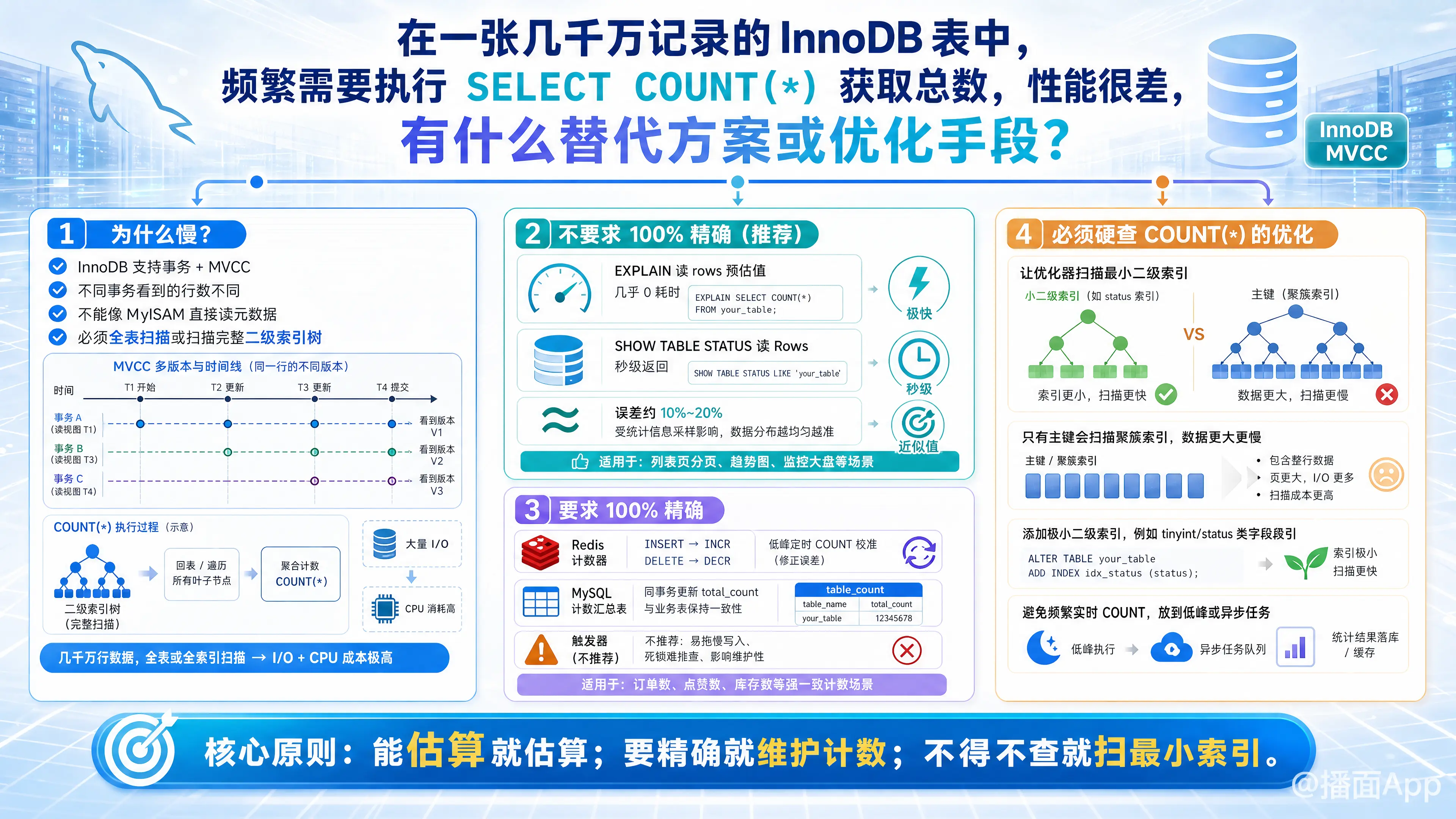
在 MySQL 的 InnoDB 存储引擎中,几千万级别的大表频繁执行 SELECT COUNT(*) 性能极差是一个经典的痛点。
为什么 InnoDB 的 COUNT(*) 这么慢?
与 MyISAM 引擎将表总行数缓存在元数据中不同,InnoDB 支持事务和多版本并发控制(MVCC)。在同一时刻,不同的事务看到的表行数可能是不同的。因此,InnoDB 不能简单地读一个缓存值,而是必须扫描全表(或扫描整个二级索引树)来逐行计算当前事务可见的行数。几千万行的扫描,必然带来巨大的磁盘 I/O 和 CPU 消耗。
针对这个问题,通常有以下几种替代方案或优化手段,需要根据你的业务对计数的精确度要求来选择:
方案一:业务不需要 100% 精确的总数(推荐)
如果你的场景是类似百度搜索结果的“为您找到相关结果约 10,000,000 个”,不需要绝对精确,可以使用以下秒级返回的方案:
1. 使用 EXPLAIN 获取预估值
通过 EXPLAIN 语句解析目标表,读取 rows 字段。这个值是 MySQL 优化器通过采样估算出来的,非常快。
EXPLAIN SELECT * FROM your_table;- 优点: 耗时几乎为 0。
- 缺点: 误差大概在 10% - 20% 左右。
2. 使用 SHOW TABLE STATUS
SHOW TABLE STATUS LIKE 'your_table';读取返回结果中的 Rows 字段,原理与 EXPLAIN 类似,也是统计信息的预估值。
方案二:业务需要 100% 精确的总数
如果你做的是财务系统、管理后台分页,必须严格知道精确的总数,可以采用以下方案:
1. 引入缓存(如 Redis)维护计数器(最常用)
将表的总数缓存在 Redis 中。
- 操作: 每次往 MySQL
INSERT一条记录时,Redis 执行INCR;每次DELETE一条记录时,Redis 执行DECR。 - 误差修正: 因为 MySQL 事务和 Redis 的更新不是强一致性的,极低概率会出现不一致。可以写一个定时任务(比如每天凌晨),执行一次真实的
SELECT COUNT(*)(尽量在业务低峰期),将准确的值刷入 Redis 校准。
2. 在 MySQL 中新建一张“计数汇总表”
如果不想引入外部缓存,可以在 MySQL 中建一张表专门存总数。
CREATE TABLE table_count_summary (
table_name VARCHAR(64) PRIMARY KEY,
total_count BIGINT NOT NULL DEFAULT 0
);- 操作: 在业务代码中,增删数据时,通过同一个数据库事务,同步更新这张表(
UPDATE table_count_summary SET total_count = total_count + 1 WHERE table_name = 'your_table')。 - 缺点: 高并发插入/删除时,这行汇总数据的行锁会成为系统的性能瓶颈。
3. 使用触发器(不推荐)
原理同上,只是把更新汇总表的逻辑写在 MySQL 触发器里。强烈不建议在千万级大表上使用触发器,会严重拖慢增删改的速度,且极难排查死锁问题。
方案三:必须硬查 COUNT(*) 时的优化手段
如果由于历史包袱,你只能硬查 SELECT COUNT(*),那么尽最大可能让它变快:
1. 确保 MySQL 扫描的是最小的二级索引
InnoDB 在执行 COUNT(*) 时,优化器会专门寻找树最小的非聚簇索引(二级索引)进行扫描。
- 如果你的表只有主键,它会扫描主键索引树(包含完整行数据,极其庞大,巨慢)。
- 优化方法: 给表添加一个极小的二级索引。例如针对一个
TINYINT类型的字段(如is_deleted或status)建索引。这样 MySQL 扫描这个微小索引树就能得出总数,速度会提升数倍。
2. 带条件的 COUNT 优化(COUNT(id) WHERE ...)
如果是带条件的查询,确保条件字段有覆盖索引(Covering Index)。比如 SELECT COUNT(id) FROM table WHERE status = 1,确保 (status) 或者 (status, id) 上有索引,避免回表。
补充一个误区: 经常有人争论
COUNT(*)、COUNT(1)和COUNT(id)哪个快。
在 MySQL 8.0/5.7 中,引擎层对COUNT(*)做了专门的深度优化,它的语义就是“统计行数”。性能排行通常是:COUNT(*)≈COUNT(1)>COUNT(id)。所以直接写COUNT(*)即可,不要自作聪明写COUNT(id)(这还要判断 id 是否为 NULL)。
方案四:从产品/交互层面解决(降维打击)
很多时候,技术上的难题可以通过改变产品交互来轻松化解:
1. 放弃传统分页,改用“无限滚动”(Cursor Pagination)
千万级数据让用户翻页到第 10 万页毫无意义。
- 改变交互: 像拉取微博、朋友圈一样,只提供“下一页”。
- 技术实现:
SELECT * FROM table WHERE id < last_max_id ORDER BY id DESC LIMIT 20;。完全不需要计算COUNT(*),查询速度永远是毫秒级。
2. 限制最大可查看页数
很多大厂的后台管理系统(包括 Elasticsearch 的默认行为)只允许用户查看前 10000 条结果。
当数据量大于 10000 时,页面显示 “共 10000+ 条记录”。这样你只需要 SELECT id FROM table LIMIT 10000, 1 判断有没有第 10001 条数据即可,完全跳过了全表 COUNT。
总结建议
- 如果能改交互:首选无限滚动或限制最大页数(方案四)。
- 如果只求大概数字:用
EXPLAIN(方案一)。 - 如果必须精准且高并发:用 Redis 计数器 + 凌晨定时校准(方案二)。
- 如果实在没有办法只能查 DB:建一个极小的二级索引供它扫描(方案三)。