 播面
播面 单表数据量千万级,业务代码中存在 LIMIT 1000000, 20 这样的分页查询,导致接口响应极慢,你会如何优化?
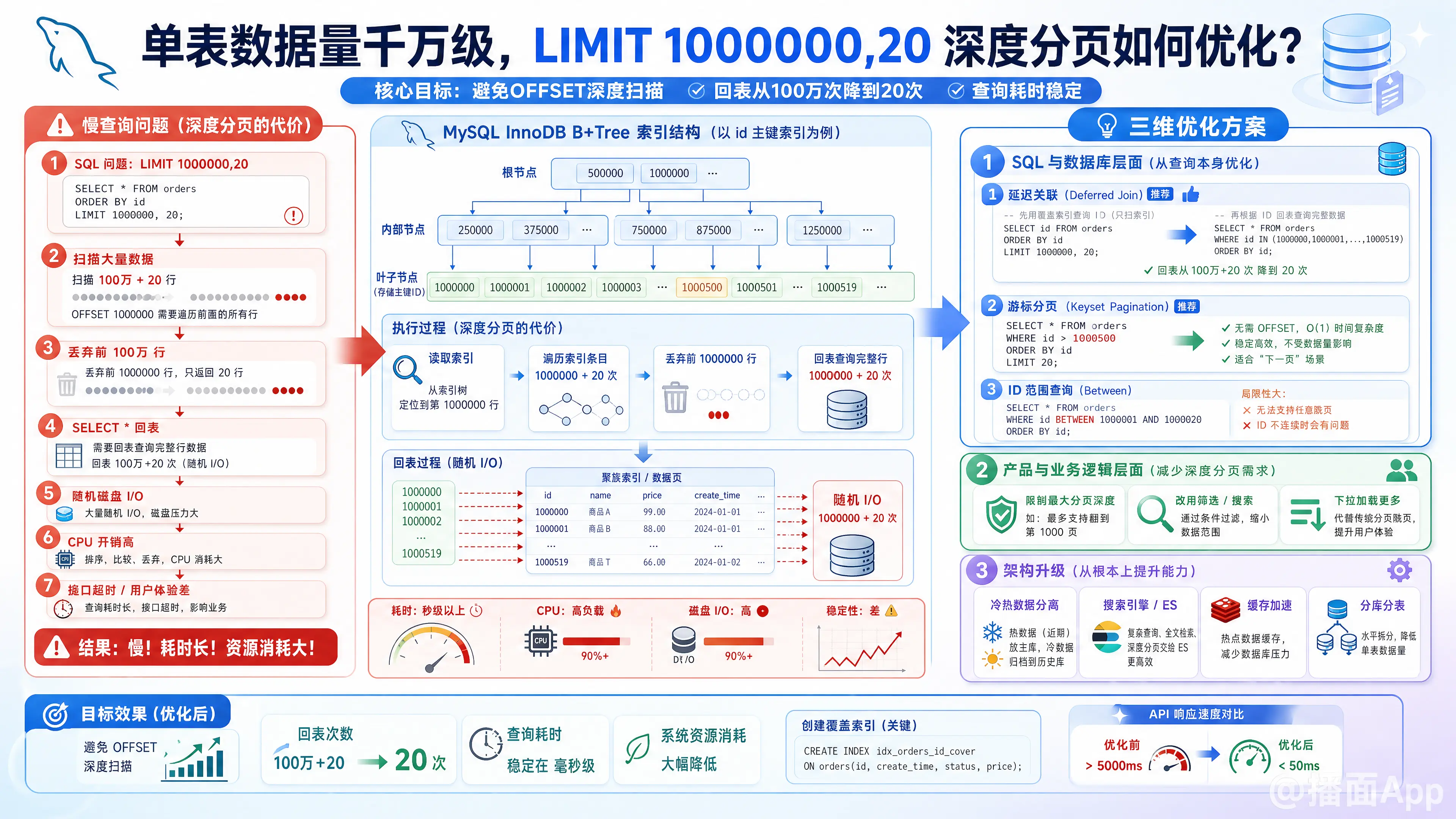
在MySQL单表千万级数据量的场景下,LIMIT 1000000, 20 这种查询被称为深度分页(Deep Pagination)。
为什么它会极慢?
MySQL的 LIMIT offset, rows 机制并不是直接跳到第 offset 行,而是会扫描 offset + rows 行数据,然后丢弃前 offset 行,返回最后 rows 行。
在 LIMIT 1000000, 20 的情况下,MySQL会读取100万零20条数据。如果查询包含了非索引列(需要SELECT *),还会触发100万次的回表(Bookmark Lookup)操作,导致产生海量的随机磁盘I/O和CPU开销,最终导致接口超时。
针对这个问题,作为后端开发/架构师,我会从以下三个维度(SQL优化、产品设计、架构升级)进行综合优化:
一、 SQL 与 数据库层面的优化(技术手段)
1. 延迟关联(Deferred Join)—— 推荐(适用于允许跳页)
利用覆盖索引(Covering Index)的特性,先在索引树上快速查出主键ID,然后再通过主键ID去回表查询完整的行记录。这样可以把100万次回表减少到只有20次回表。
- 优化前:sql
SELECT * FROM orders WHERE status = 1 ORDER BY create_time LIMIT 1000000, 20; - 优化后:sql
SELECT t1.* FROM orders t1 INNER JOIN ( SELECT id FROM orders WHERE status = 1 ORDER BY create_time LIMIT 1000000, 20 ) t2 ON t1.id = t2.id; - 效果: 子查询
SELECT id会直接走二级索引,不需要回表,速度极快。外层查询做JOIN时,只需要根据20个ID去聚簇索引查数据,性能成百上千倍提升。
2. 游标分页 / 标签记录法(Keyset Pagination)—— 强烈推荐(适用于不支持跳页,只能上一页/下一页)
如果业务场景是类似App的“下拉加载更多”,用户不需要直接跳转到第50000页,那么可以通过记录上一页最后一条数据的ID(或排序字段)来进行查询。
- 优化后:sql
-- 假设上一页最后一条记录的ID是 1000500 SELECT * FROM orders WHERE status = 1 AND id > 1000500 ORDER BY id ASC LIMIT 20; - 效果: 这种写法利用了B+树的特性,直接从给定的ID开始向后扫描20行,完美避开了
OFFSET,无论翻到多少页,查询时间基本恒定(O(1)级别)。 - 注意: 排序字段必须有索引,且最好是连续唯一的(如自增ID或带有唯一性的时间戳)。
3. ID范围查询(Between...And)—— 局限性大
如果能保证主键ID是绝对连续的(中间没有被删除的记录),可以直接计算出ID范围。
- 优化后:
SELECT * FROM table WHERE id BETWEEN 1000000 AND 1000020; - 缺点: 真实业务中数据基本都有物理删除或事务回滚,ID很难绝对连续,这种方法极易导致每页返回的数据量不足20条,一般不推荐。
二、 产品与业务逻辑优化(降维打击)
很多时候,技术上的难题可以通过改变产品交互来轻易解决。我们需要反思:用户真的需要看第5万页的数据吗?
1. 限制最大分页深度
几乎没有任何真实用户会一页一页翻到第5万页。如果是爬虫或恶意请求,反而会拖垮数据库。
- 方案: 限制用户最多只能翻看前 100 页(即前2000条数据)。如果找不到想要的数据,强制要求用户输入更精确的搜索条件。
- 参考: 百度、谷歌、淘宝等顶级产品,搜索结果无论有多少,通常也只允许用户看前几十页。
2. 更改交互方式为“下拉加载更多”
将PC端的传统分页(带有页码 1, 2, 3...100)改为移动端常见的“无限下拉加载”。
- 方案: 这种交互天然契合前面提到的“游标分页(Keyset Pagination)”。后端每次只需要接收
last_id即可,彻底根除深度分页问题。
三、 架构层面的优化(长远之计)
如果业务确实需要复杂的条件筛选,且数据量持续膨胀,MySQL本身就不再适合做这种事了。
1. 引入搜索引擎(Elasticsearch)
对于千万级甚至亿级数据量的多维查询和分页,应该把查询职责转移给专门的搜索引擎。
- 方案: 通过 Canal 或 Logstash 将 MySQL 的数据实时同步到 Elasticsearch。业务代码中的查询走 ES,ES原生支持复杂的查询,并且可以通过
search_after机制完美解决深度分页问题。
2. 冷热数据分离
表里有千万级数据,但可能80%都是一两年前的历史数据,用户极少查询。
- 方案: 定时将半年或一年前的已完结数据迁移到历史表(归档表)。保持主表(热表)的数据量在几百万以内,从根本上缓解查询压力。
总结与我的执行策略
如果我在实际工作中遇到这个问题,我会按以下顺序处理:
- 快速止血:立刻审查代码,如果是爬虫攻击导致的极端
OFFSET,先在网关层或业务层对page_num做限制(比如最大允许100页)。 - 短期方案:如果不改动产品交互,使用 延迟关联(Deferred Join) 修改SQL,当天即可上线解决接口超时问题。
- 沟通协调:与产品经理沟通,评估是否可以去掉具体页码跳转,改为游标(上一页/下一页/下拉)的交互模式,从而采用性能最高的
id > last_id方案。 - 长期规划:如果该查询不仅分页深,还带有各种复杂的组合筛选,我会申请排期引入 Elasticsearch 将查询与存储解耦。