 播面
播面 电商订单列表页有十几个筛选条件(时间、状态、用户ID、金额等),用户可能随意组合查询,如何设计索引来应对这种场景?
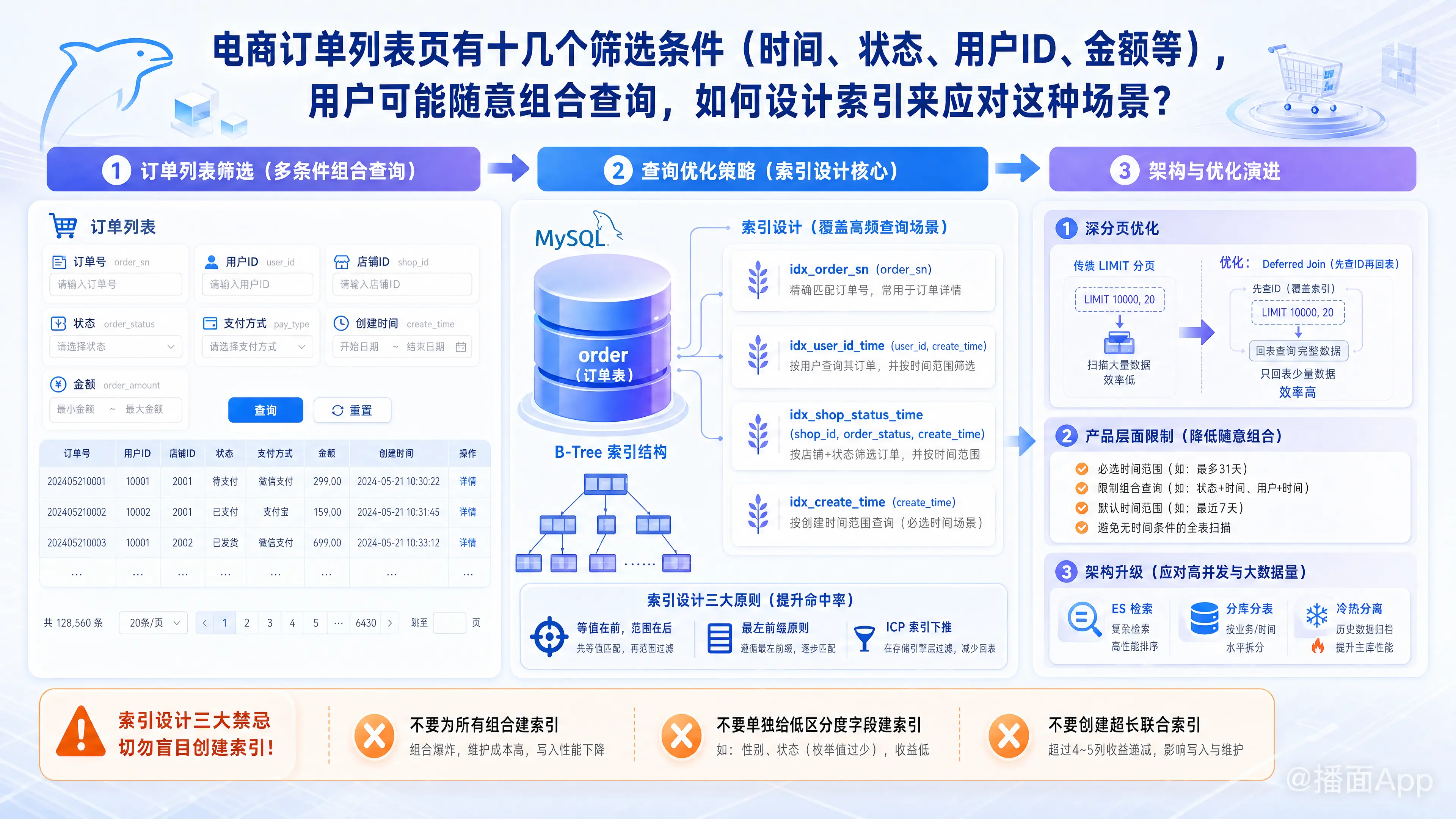
在电商系统中,订单列表页面临着十几个筛选条件(如订单号、用户ID、店铺ID、订单状态、支付方式、创建时间、订单金额等)且允许用户随意组合的场景。
这是传统关系型数据库(MySQL)最头疼的问题之一。因为MySQL通常一次查询只能使用一个索引(虽然有Index Merge,但效率并不总是理想),且组合索引必须遵循最左前缀法则。不可能为所有组合创建数百个索引,那会导致写入性能崩溃。
要应对这种场景,必须从MySQL索引设计优化、产品交互限制以及架构演进三个维度来综合解决。
第一步:MySQL 纯数据库层面的索引设计策略
在数据量未达到海量(例如单表几百万以内)时,可以通过精心设计几个核心的联合索引来覆盖 80% 以上的常见查询。
1. 字段分类与特征分析
首先,将所有的筛选条件进行分类:
- 高频且高区分度(精准查询):
order_sn(订单号)、user_id(买家ID)、shop_id(卖家ID)、phone(手机号)。 - 高频但低区分度(枚举类):
order_status(状态)、pay_type(支付方式)。 - 范围查询:
create_time(下单时间)、pay_time(支付时间)、order_amount(金额)。
2. 索引设计的三大黄金法则
- 等值查询在前,范围查询在后: 联合索引中,必须把
=或IN的条件放在前面,把>,<,BETWEEN放在最后。因为遇到范围查询后,索引的后续字段就会失效。 - 高频条件放最左侧: 遵循最左前缀法则。
- 利用索引下推(ICP): 即使某些字段在联合索引的范围查询之后失效,MySQL 5.6+ 也会利用索引下推在引擎层过滤数据,减少回表次数。
3. 具体的索引设计方案推荐
针对电商场景,我们通常不能满足所有“随意组合”,而是去命中核心路径。建议创建以下几个索引:
- 索引 A(精准单号匹配):
UNIQUE KEY idx_order_sn (order_sn)- 应对: 用户直接搜订单号。只要有订单号,其他条件直接忽略。
- 索引 B(C端买家视角核心索引):
KEY idx_user_id_time (user_id, create_time)- 应对: 用户查看自己的订单。哪怕他附加了“状态=已发货”,通过
user_id过滤后的数据量已经很小了,即使回表或者用索引下推过滤状态也极快。
- 应对: 用户查看自己的订单。哪怕他附加了“状态=已发货”,通过
- 索引 C(B端卖家视角核心联合索引 - 重点):
KEY idx_shop_status_time (shop_id, order_status, create_time)- 应对: 商家查自己的订单。
- 为什么这么排?
shop_id是等值,order_status通常也是等值(或者 IN),create_time是范围查询。这个索引能完美应对“某店铺某状态在某时间段的订单”。
- 索引 D(通用时间检索):
KEY idx_create_time (create_time)- 应对: 运营后台没有输入具体用户和店铺,只是筛选昨天的大额订单。此时可以通过时间范围先圈定一批数据。
千万不要做的操作:
- 不要给
order_status、pay_type这种只有几个值的字段单独建索引,毫无意义,MySQL优化器会直接选择全表扫描。 - 不要建超过 5 个字段的超级联合索引,维护成本太高。
第二步:深分页问题优化(Limit 10000, 20)
随意组合查询往往伴随着分页。当组合条件只能命中时间范围等较弱的索引时,翻到很靠后的页码会产生“深分页”性能灾难。
解决方案:延迟关联(Deferred Join)
不要直接 SELECT *,而是先通过索引查出主键,再 Join 原表获取所有字段。
sql
-- 慢查询:回表大量无用数据
SELECT * FROM orders WHERE create_time > '2023-01-01' AND order_amount > 100 LIMIT 100000, 20;
-- 优化后:利用覆盖索引先查主键,再关联查询
SELECT o.* FROM orders o
INNER JOIN (
SELECT id FROM orders
WHERE create_time > '2023-01-01' AND order_amount > 100
LIMIT 100000, 20
) AS tmp ON o.id = tmp.id;第三步:产品与交互层面的限制(兜底策略)
永远不要完全信任用户的“随意组合”,技术解决不了的,可以通过产品交互来限制,这在业界非常普遍(包括淘宝、京东后台)。
- 强制时间窗口限制: 任何多条件组合查询,必须带上时间范围(例如限制查询跨度最多 30 天或 90 天)。这就保证了即使其他索引失效,
idx_create_time也能把数据量锁死在一个月的数据范围内。 - 默认条件互斥: 如果输入了订单号(精确搜索),前端直接清空或禁用时间、状态等其他筛选项。
- 限制最大分页数: 例如只允许查看前 100 页。如果需要更靠后的数据,提示用户增加更详细的筛选条件或使用导出功能。
第四步:架构演进(终极解决方案)
当订单表数据量突破千万,或者查询条件真的变幻莫测、包含各种模糊搜索(LIKE '%商品名称%')时,纯 MySQL 已经无法解决这个问题了。此时必须引入外部组件:
1. 引入 Elasticsearch (ES) —— 业界标配
- 原理: ES 基于倒排索引,天然支持多维度的随意组合查询。你可以在 ES 里对订单的十几个字段全部建立索引,查询速度都是毫秒级。
- 架构: MySQL 作为数据的主存储(Source of Truth)负责事务和写入。通过中间件(如 Canal, Maxwell, 或 Flink CDC)监听 MySQL 的 Binlog,将订单数据的变更近实时(延迟一般在秒级)同步到 ES 中。
- 查询: 列表页的复杂查询请求直接打给 ES,ES 返回订单主键 ID 或直接返回列表数据。
2. 冷热数据分离
很多时候查询慢是因为表里堆积了太多老数据。
- 将 3 个月或半年前的已完结订单,迁移到历史表(
orders_history)或归档到大数据平台(如 Hive, ClickHouse)。 - 热表保持在几百万量级,此时即使 MySQL 走不完美的索引,性能也是可接受的。
总结
面对这种场景,你的解决思路应该按照以下优先级逐步递进:
- 产品评估: 加上“强制时间范围”过滤,限制最大分页深度。
- MySQL优化: 建立
(user_id, create_time)、(shop_id, status, create_time)等 3-4 个高频联合索引,保证等值字段在前,范围字段在后。 - SQL优化: 深分页查询使用“延迟关联”避免大量回表。
- 架构升级: 如果数据量极大、组合过于复杂,不要再死磕 MySQL,通过 Binlog 同步数据至 Elasticsearch 解决。