 播面
播面 Dubbo底层网络通信机制
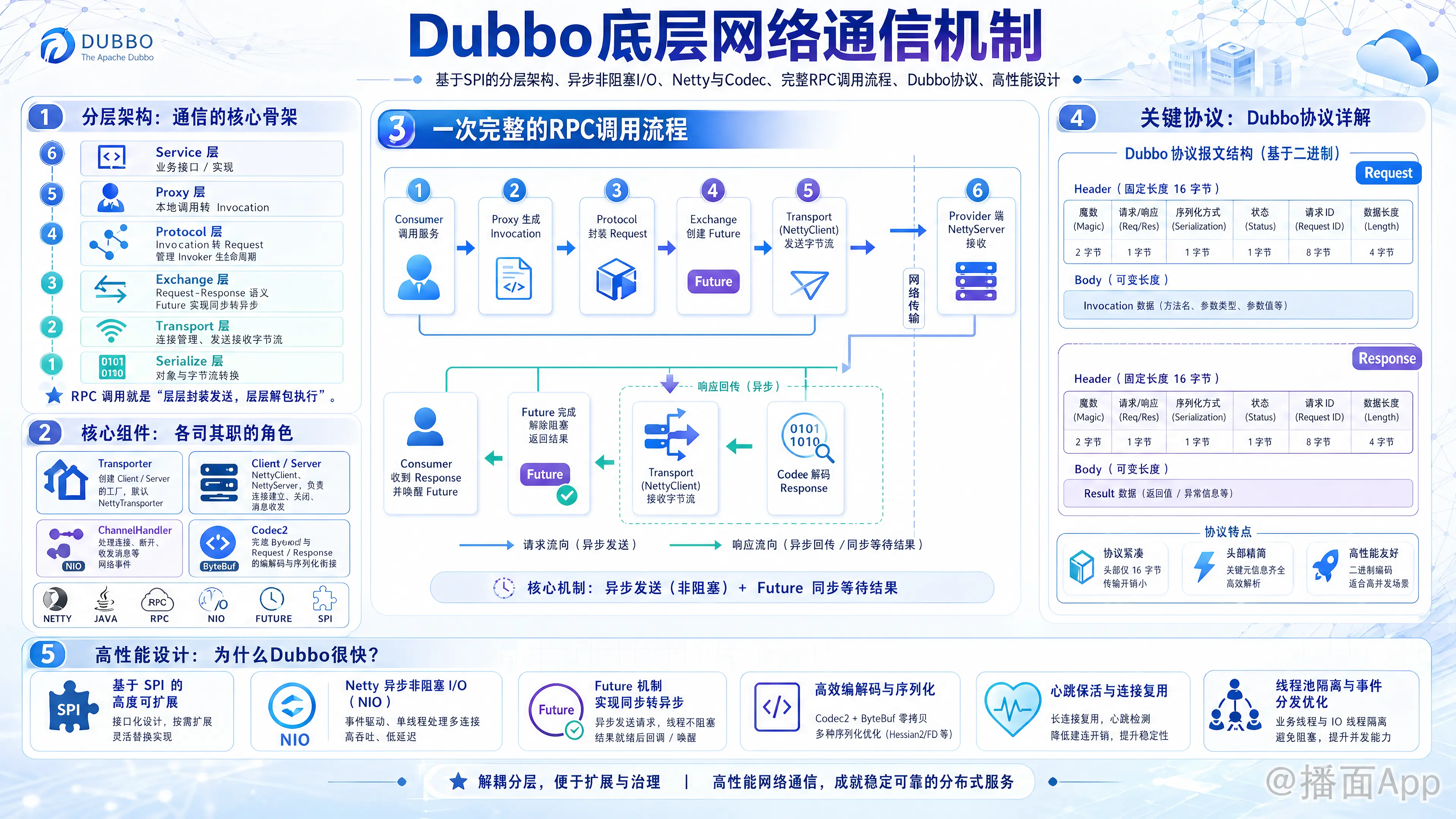
深入剖析 Dubbo 底层网络通信:基于 SPI 的分层架构、异步非阻塞 I/O 模型、核心组件(Netty、Codec)、完整的 RPC 调用流程、精简的 Dubbo 协议以及心跳、线程池隔离等高性能设计。
我们来深入剖析一下 Dubbo 底层的网络通信机制。这是一个非常核心且有深度的话题,理解它有助于我们更好地使用和排查 Dubbo 相关的问题。
Dubbo 的网络通信可以总结为:一个基于 SPI(Service Provider Interface)高度可扩展的、分层的、异步非阻塞的 RPC 通信模型。
我会从以下几个方面来详细拆解:
- 分层架构:通信的核心骨架
- 核心组件:各司其职的“角色”
- 一次完整的 RPC 调用流程
- 关键协议:Dubbo 协议详解
- 高性能设计:为什么 Dubbo 很快?
1. 分层架构:通信的核心骨架
Dubbo 的设计哲学之一就是分层,将复杂的网络通信过程清晰地解耦。从上到下,与网络通信直接相关的核心层次如下:
- Service 层 (业务层):这是我们最熟悉的层,就是我们定义的接口(Interface)和实现(Implementation)。
- Proxy 层 (代理层):为业务接口生成代理类,将本地的方法调用转换为远程的
Invocation对象。这是 RPC 的起点。 - Protocol 层 (协议层):封装 RPC 调用,管理
Invoker的生命周期。它将代理层的Invocation转换为一个Request对象,并发起远程调用。这是 Dubbo 协议、gRPC 协议、Triple 协议等发挥作用的地方。 - Exchange 层 (信息交换层):在传输层之上,封装了 Request-Response 的语义模型。它将底层的异步通信转换为同步/异步的调用模式(通过
Future机制)。这是 Dubbo 同步转异步的关键。 - Transport 层 (网络传输层):这是最底层的网络 I/O 部分,负责建立连接、断开连接、发送和接收二进制数据流。它只关心“连接”和“字节流”,不关心业务数据是什么。
- Serialize 层 (序列化层):负责将 Java 对象(如
Invocation、Result)与网络传输的字节流进行相互转换。
总结:一个 RPC 调用,就是数据从上层层层封装,通过 Transport 层发送出去;接收方则从 Transport 层接收数据,层层解包,最终执行业务逻辑。
2. 核心组件:各司其职的“角色”
在上述分层中,有几个关键的接口和实现类,它们是整个通信过程的主角。
Transporter(网络传输扩展点):- 职责:创建
Client和Server的工厂。 - 默认实现:
NettyTransporter。Dubbo 默认使用 Netty 作为其底层的网络通信框架。也可以配置为 Mina、Grizzly 等。 - 配置:
<dubbo:protocol transporter="netty4" />
- 职责:创建
Client/Server(传输端点):- 职责:封装了连接的建立、关闭和消息的发送/接收等底层操作。
- 实现:
NettyClient和NettyServer。
ChannelHandler(消息处理器):- 职责:处理网络事件,如连接、断开、接收到消息、发送消息等。Dubbo 在 Netty 的 Handler 基础上做了一层自己的封装。
Codec2(编解码器):- 职责:负责将网络字节流(ByteBuf)与 Dubbo 的
Request/Response对象进行相互转换。它包含了序列化和 Dubbo 协议头的处理。 - 实现:
DubboCodec。
- 职责:负责将网络字节流(ByteBuf)与 Dubbo 的
Dispatcher(线程派发器):- 职责:控制消息由 I/O 线程转交给哪个线程池来处理。这是保证 I/O 线程不被业务逻辑阻塞的关键。
- 策略:
all(默认): 所有消息(请求、响应、连接、心跳)都派发到业务线程池。direct: 不派发,直接在 I/O 线程上执行。(风险高,仅用于超短时任务)message: 只有请求和响应消息派发到业务线程池。execution: 只有请求消息派发到业务线程池。connection: 同一连接上的消息保证有序地在业务线程池中执行。
- 配置:
<dubbo:protocol dispatcher="message" />
ThreadPool(线程池):- 职责:执行业务逻辑,避免 I/O 线程被长时间占用。
- 实现:
FixedThreadPool(固定大小),CachedThreadPool(缓存) 等。 - 配置:
<dubbo:protocol threadpool="fixed" threads="100" />
3. 一次完整的 RPC 调用流程
让我们把这些组件串起来,看看一次 Consumer 到 Provider 的调用是如何发生的。
Consumer 端(发起调用)
- 业务调用:应用代码调用代理对象的方法(例如
userService.getUser(1))。 - 代理拦截:
Proxy层的代理逻辑拦截该调用,将其封装成一个Invocation对象,包含了方法名、参数类型、参数值等信息。 - 路由与负载均衡:
Cluster层根据路由规则和负载均衡策略,选择一个具体的Invoker(代表一个 Provider 实例)。 - 协议调用:
Protocol层(如DubboProtocol)的Invoker被调用。它会获取一个ExchangeClient。 - 信息交换:
ExchangeClient将Invocation包装成一个Request对象,并为其分配一个全局唯一的 ID (例如requestId=1)。 - 同步转异步:
ExchangeClient创建一个DefaultFuture对象,并将其存入一个全局的Map<long, DefaultFuture>中(key是requestId)。然后它会调用底层Client发送请求。如果调用是同步的,当前业务线程会调用future.get()进行等待。 - 编码与序列化:
Codec开始工作。它首先使用Serialization(如 Hessian2) 将Request对象序列化成字节数组(payload)。 - 协议编码:然后,
Codec按照 Dubbo 协议的格式,将协议头(魔数、请求 ID、payload长度等)和序列化后的payload组装成一个完整的二进制数据包。 - 网络发送:
Transport层(如NettyClient)将编码后的ByteBuf写入到 TCP 连接的Channel中,发送给 Provider。
Provider 端(处理请求)
- 网络接收:
NettyServer的 I/O 线程从Channel接收到二进制数据。 - 协议解码:
Codec读取数据流,首先解析出 Dubbo 协议头,确认是一个合法的 Dubbo 请求,并获取到payload的长度。 - 反序列化:当接收到完整的
payload后,Codec使用指定的Serialization方式(协议头中指定)将其反序列化成一个Request对象。 - 线程派发:
NettyServer的Handler接收到Request对象后,通过Dispatcher将其派发给后端的业务线程池 (ThreadPool)。这一步非常关键,它将 I/O 线程解放出来,使其能继续处理其他连接的 I/O 事件。 - 查找并执行:业务线程根据
Request中的接口名、方法名、参数等信息,找到对应的Exporter和业务实现类,并通过反射调用真实的方法。 - 返回结果:业务方法执行完毕,返回结果或抛出异常。
- 打包响应:这个结果被封装成一个
Response对象,其中包含了原始的requestId。 - 编码发送:
Response对象经历与请求类似的逆过程(序列化 -> 协议编码),由NettyServer通过Channel发送回 Consumer。
Consumer 端(接收响应)
- 网络接收与解码:
NettyClient的 I/O 线程接收到响应数据,并由Codec解码/反序列化成Response对象。 - 匹配 Future:
ExchangeClient的Handler根据Response中的requestId,从全局Map中找到之前存储的DefaultFuture。 - 唤醒线程:
Handler将Response的结果设置到Future中,并调用future.signal()唤醒正在future.get()上等待的业务线程。 - 返回结果:业务线程被唤醒,从
Future中获取到最终结果,并将其返回给最初的应用调用处。
至此,一次完整的 RPC 调用闭环。
4. 关键协议:Dubbo 协议详解
Dubbo 默认的 dubbo 协议是一个二进制协议,设计得非常紧凑高效。其数据包结构如下:
+------------------------------------------------------------------------------------+
| 2-byte Magic | 1-byte Flags | 1-byte Status | 8-byte Request ID |
+------------------------------------------------------------------------------------+
| 4-byte Data Length |
+------------------------------------------------------------------------------------+
| |
| Payload (Variable Length) |
| |
+------------------------------------------------------------------------------------+- Magic (16 bits): 魔数,
0xdabb,用于快速判断数据包是否是 Dubbo 协议,防止处理脏数据。 - Flags (8 bits): 标志位。
- 第 7 位: 请求/响应标志 (1=Request, 0=Response)。
- 第 6 位: 双向/单向标志 (1=TwoWay, 0=OneWay)。只有 TwoWay 的请求才会期待响应。
- 第 5 位: 事件标志 (1=Event, 0=Normal)。用于心跳等事件消息。
- 后 4 位: 序列化器 ID (e.g., 2=Hessian2, 6=Protobuf)。
- Status (8 bits): 状态码,仅在响应时有效 (e.g., 20=OK, 50=SERVER_TIMEOUT)。
- Request ID (64 bits): 请求的唯一标识,用于将响应与请求进行匹配。
- Data Length (32 bits):
Payload的长度,即序列化后的业务数据的字节数。 - Payload (Variable): 经过序列化框架处理后的数据,如
Invocation或Result的字节流。
这个协议设计得非常精妙,通过一个固定的 16 字节头部,就可以承载 RPC 调用的所有元信息。
5. 高性能设计:为什么 Dubbo 很快?
Dubbo 的高性能得益于其底层通信设计的多个方面:
- 异步非阻塞 I/O:基于 Netty 等 NIO 框架,使用少数 I/O 线程(通常是 CPU 核数 * 2)就可以管理成千上万的连接,避免了传统 BIO 模型下线程数量爆炸的问题。
- 连接复用与连接池:Consumer 与 Provider 之间默认建立长连接,并且可以配置多个连接 (
connections属性),所有请求都通过这些长连接进行传输,避免了频繁 TCP 建立和关闭的开销。 - 高效的序列化框架:默认使用 Hessian2,它是一种性能和压缩率都非常出色的二进制序列化协议。同时支持 Protobuf、Kryo 等更高性能的序列化方案。
- 精简的协议设计:Dubbo 协议头固定为 16 字节,非常紧凑,减少了网络传输的额外开销。
- 线程池隔离:通过
Dispatcher和ThreadPool将 I/O 线程与业务执行线程隔离,防止耗时的业务逻辑阻塞 I/O,保证了系统的高吞吐量。 - 心跳机制:客户端和服务器之间会定时发送心跳包,用于检测连接是否存活。这可以及时剔除“假死”的连接,避免请求发送到无效连接上导致超时。
总而言之,Dubbo 的底层网络通信是一个精心设计、高度抽象、可插拔且性能卓越的系统。它将复杂的网络细节完美地隐藏起来,让开发者可以像调用本地方法一样进行远程服务调用。