 播面
播面 Kafka事务(Transactions)主要是为了解决什么场景的问题?
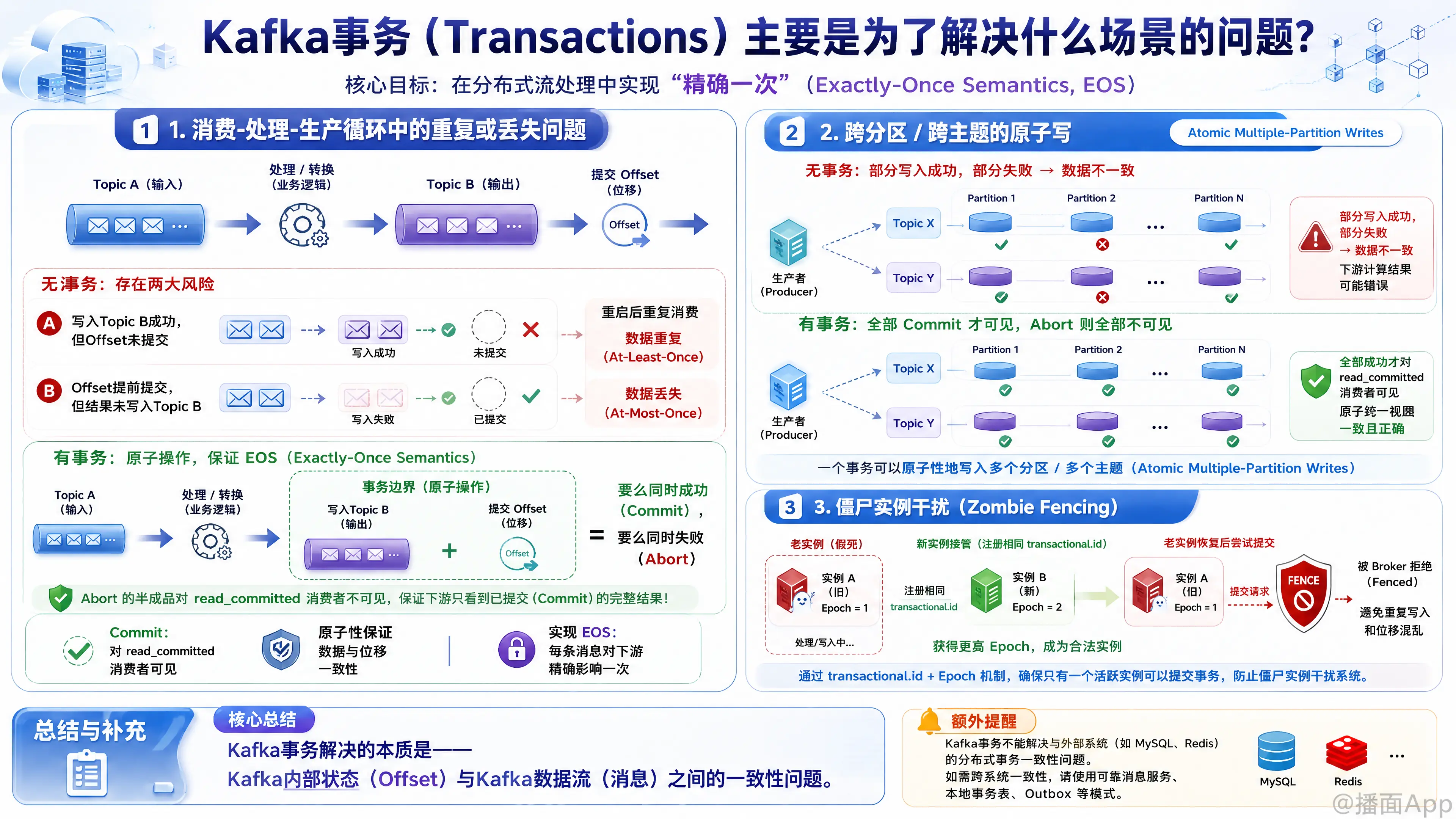
Kafka 引入事务(Transactions)机制,主要是为了在分布式流处理环境中实现 “精确一次”(Exactly-Once Semantics, EOS) 语义。
具体来说,Kafka 事务主要是为了解决以下 三大核心场景/问题:
1. 核心场景:消费-处理-生产(Consume-Transform-Produce)循环中的数据重复或丢失问题
这是 Kafka 事务被设计出来的最主要目的。在流处理应用(如 Kafka Streams, Flink)中,最常见的模式是:
- 从 Topic A(输入主题)读取消息。
- 在内存中处理/转换这些消息。
- 将结果写入 Topic B(输出主题)。
- 提交 Topic A 的消费位移(Offset)。
没有事务时面临的问题:
- 应用在步骤 3 和 4 之间崩溃:结果已经写入 Topic B,但 offset 没有提交。应用重启后,会重新从旧的 offset 拉取消息,再次处理并写入 Topic B,导致 数据重复(至少一次语义,At-Least-Once)。
- 应用在步骤 2 和 3 之间崩溃(但提前自动提交了位移):消息没写到 Topic B,但位移已经推进,导致 数据丢失(至多一次语义,At-Most-Once)。
Kafka事务的解决方式:
Kafka 事务允许将 “生产消息到 Topic B” 和 “提交 Topic A 的消费位移” 这两个操作捆绑成一个原子操作。要么两者同时成功,要么同时失败。如果应用崩溃,未完成的事务会被中止(Abort),下游配置了 read_committed 的消费者不会看到这些“半成品”数据,重启后的应用会重新读取并正确处理,从而实现真正的“精确一次”。
2. 场景二:跨分区 / 跨主题的原子写(Atomic Multiple-Partition Writes)
在某些业务场景下,一个生产者需要同时向多个不同的 Topic 或同一个 Topic 的多个 Partition 发送多条消息,并且要求这些消息具备一致性。
没有事务时面临的问题:
生产者向 Partition 1 发送成功,但向 Partition 2 发送时网络异常或 Broker 宕机。此时,系统中存在部分成功的数据,破坏了业务的原子性。
Kafka事务的解决方式:
开启事务后,生产者向多个 Partition 发送的所有消息,要么全部对消费者可见(Commit),要么全部不可见(Abort)。这保证了多分区写入的原子性。
3. 场景三:僵尸实例干扰(Zombie Fencing)
在分布式系统中,由于网络抖动或 GC 停顿,某个流处理实例可能会“假死”。此时,集群管理器(如 Kubernetes 或 YARN)可能会启动一个新的实例来接管它的工作。
没有事务时面临的问题:
如果那个“假死”的老实例(僵尸实例)突然苏醒,它和新实例会同时向同一个 Topic 写入数据,并且同时提交位移,导致数据混乱和严重重复。
Kafka事务的解决方式:
Kafka 事务强制要求每个事务生产者配置一个唯一的 transactional.id。
- Kafka 会为这个 ID 分配一个递增的纪元号(Epoch)。
- 当新实例启动并使用相同的
transactional.id注册时,它的 Epoch 会增加。 - 当老实例(僵尸)苏醒后尝试提交写入时,Kafka Broker 发现它的 Epoch 比当前记录的小,就会直接拒绝(Fence)它的请求,从而完美隔离了僵尸实例。
总结与补充
Kafka 事务解决的本质是: Kafka 内部状态(位移)和 Kafka 数据流(消息)之间的一致性问题。
需要注意,Kafka 事务“不能”解决什么问题:
- 不解决与外部系统的分布式事务:如果你从 Kafka 消费数据,然后写入 MySQL 或 Redis,Kafka 事务无法保证 Kafka 位移和 MySQL 写入的强一致性(这需要两阶段提交 2PC 或外部系统的幂等性设计)。
- 不是数据库级别的事务:它不支持隔离级别中的“可重复读”或“串行化”,它主要是为了防止消费者读到未提交或失败的流处理中间数据(仅提供
read_committed和read_uncommitted两种隔离级别)。
一句话概括:
Kafka 事务是为了让流处理框架(或业务代码)在 “读取Kafka -> 处理 -> 写入Kafka” 这个闭环中,无论面对什么宕机情况,都能保证数据不丢、不重、不错乱。