 播面
播面 如果发现Broker节点的出入带宽经常被打满,在不增加物理机器的前提下,如何通过调整Producer的压缩算法(如LZ4、ZSTD)来缓解网络瓶颈?
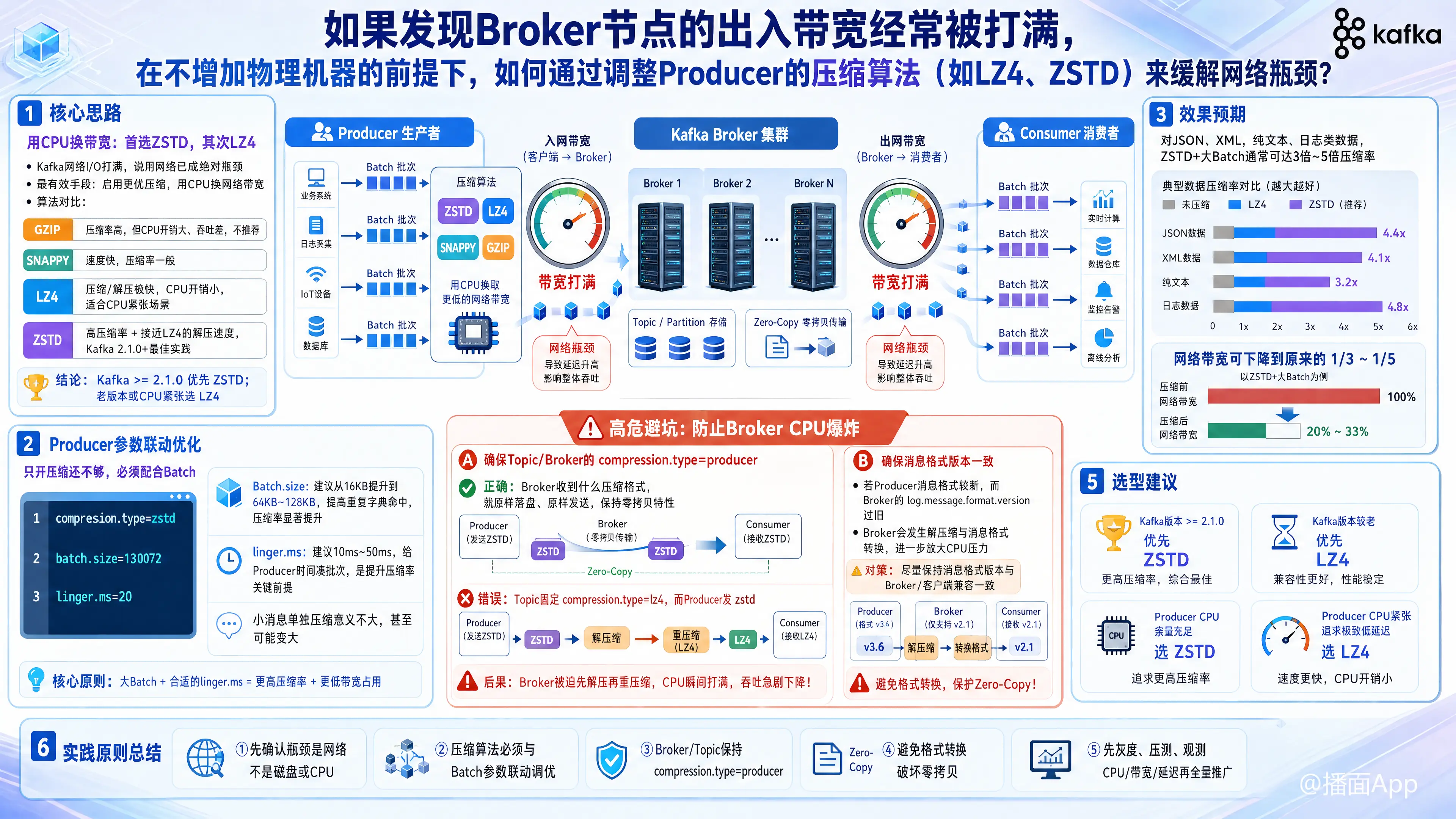
在不增加物理机器的前提下,Kafka Broker 出现网络出入带宽打满的情况,通常意味着网络 I/O 已经成为系统的绝对瓶颈。此时,用 CPU 资源换取网络带宽(即开启或升级压缩算法)是最典型且最有效的破局手段。
以下是通过调整 Producer 压缩算法(重点围绕 LZ4 和 ZSTD)来缓解网络瓶颈的完整实施方案和避坑指南:
一、 核心思路:为什么选 LZ4 或 ZSTD?
在 Kafka 支持的压缩算法中(GZIP, Snappy, LZ4, ZSTD):
- GZIP:压缩率最高,但极度消耗 CPU,吞吐量极差,通常不推荐。
- Snappy:Google 出品,速度快,但压缩率表现中规中矩。
- LZ4:极高的压缩和解压速度,CPU 额外开销小,压缩率适中。适合 CPU 资源也相对紧张的场景。
- ZSTD (Zstandard):Facebook 出品,当前 Kafka 的最佳实践(需 Kafka 2.1.0+)。它提供了类似 GZIP 的高压缩率,同时拥有接近 LZ4 的解压速度。
结论:如果你的 Kafka 版本 >= 2.1.0,首选 ZSTD;如果版本较老或 Producer 端 CPU 非常紧张,选 LZ4。
二、 Producer 端参数调整实战
单单设置开启压缩是不够的,压缩算法的效率高度依赖于微批处理(Batching)。压缩单个小消息毫无意义,甚至会使得消息变大。必须配合以下参数联动调整:
# 1. 开启压缩算法 (推荐 zstd 或 lz4)
compression.type=zstd
# 2. 增加批次大小 (默认 16384 bytes 即 16KB,建议调大到 64KB - 128KB)
# 批次越大,压缩算法能找到的重复字典越多,压缩率成倍提升!
batch.size=131072
# 3. 增加等待时间 (默认 0ms,建议改为 10ms - 50ms)
# 允许 Producer 等待毫秒级的时间来凑齐一个 Batch,这是提高压缩率的关键前提
linger.ms=20效果预期:对于 JSON、XML、纯文本或包含大量重复字段的日志数据,ZSTD + 大 Batch 通常能达到 3倍到5倍 的压缩率。这意味着 Broker 的入网和出网带宽将直接下降到原来的 1/3 到 1/5。
三、 ⚠️ 极度危险的坑:防止 Broker 端 CPU 爆炸
在调整 Producer 压缩算法时,最容易引发灾难的地方是破坏了 Kafka 的“零拷贝”(Zero-Copy)特性,导致 Broker 被迫进行解压和重压缩。
为了确保 Broker 只做单纯的网络流转发,必须保证以下两点:
1. 确保 Topic / Broker 级别的配置为 producer
检查 Broker 端或 Topic 端的 compression.type 配置项。
- 正确做法:设置 Topic 的
compression.type=producer(这是默认值)。这意味着 Broker 收到什么压缩格式,就原封不动地存进磁盘,Consumer 消费时也原样发送。 - 错误做法:Topic 设置了固定的压缩格式(如
compression.type=lz4),而 Producer 使用了zstd。此时 Broker 收到 ZSTD 消息后,必须消耗大量 CPU 先解压,再用 LZ4 压缩存入磁盘。这会让 Broker 的 CPU 瞬间被打满,集群崩溃。
2. 确保消息格式(Message Format / Magic Value)一致
如果 Producer 发送的是 v2 版本的消息格式,而 Broker 配置的 log.message.format.version 是老版本(如 0.10.x 对应的 v1),Broker 为了兼容老版本,也会被迫进行解压缩和消息格式转换。
- 对策:尽量保持客户端(Producer/Consumer)版本与 Broker 版本一致,或升级客户端。
四、 Consumer 端的注意事项
网络带宽降下来了,压力会部分转移到 Consumer 的 CPU 上,因为 Consumer 需要负责解压缩。
- 解压开销:ZSTD 和 LZ4 的解压速度极快(通常在 GB/s 级别),大多数情况下 Consumer 的 CPU 完全能够承受。
- 监控:调整后,务必观察 Consumer 所在机器的 CPU 使用率以及 Consumer 的消费延迟(Lag)。如果 Consumer CPU 成为新瓶颈,可以考虑横向扩展 Consumer 实例。
五、 补充排查思路(除了压缩还能做什么?)
如果压缩率已经很高,带宽依然打满,建议排查以下问题:
- 检查数据类型是否可压缩:
如果你的 Payload 已经是加密后的数据、或者是图片/视频等二进制流,再开启 LZ4/ZSTD 几乎没有压缩效果,只会白费 CPU。 - 出网带宽通常远大于入网带宽(Fan-out 效应):
Broker 的出带宽打满往往是因为一个 Topic 有多个 Consumer Group 订阅。检查是否有废弃的 Consumer Group 依然在疯狂拉取数据。 - 精简消息体(Schema Registry):
如果消息体中包含大量的 JSON Key(例如{"userId": 123, "userName": "Alice"}),可以引入 Avro 或 Protobuf,结合 Confluent Schema Registry,将自描述信息剥离,消息体积通常能再缩小一半。 - 调整 Replica Fetch 速率:
如果是 Broker 节点间的数据复制(Replica Fetch)占用了太多带宽,可以在业务低峰期适当限流:replica.fetch.max.bytes。