 播面
播面 业务方需要发送超过10MB的大报文(如高清图片/大JSON)到Kafka,直接发送会被拒绝,架构上应该如何设计改造或调整参数?
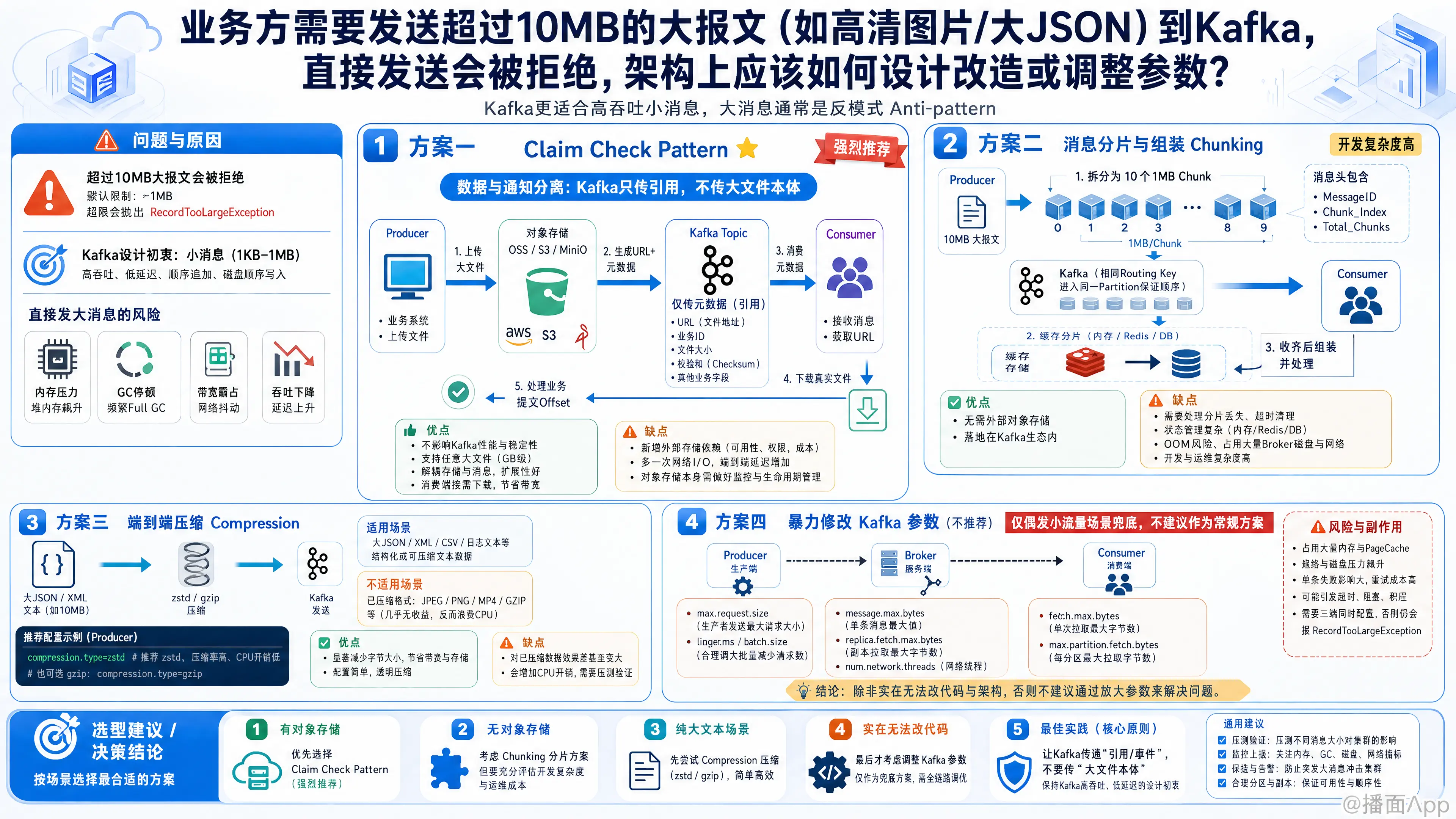
在Kafka中处理超过10MB的大报文(尤其是像高清图片、超大JSON这样的大文件),直接调整参数虽然可行,但通常被视为反模式(Anti-pattern),因为Kafka的设计初衷是处理高吞吐的小消息(通常在1KB - 1MB之间)。直接发送大消息会导致严重的内存压力、GC停顿、网络带宽霸占以及整体吞吐量急剧下降。
针对这个问题,业界有三种标准的架构改造方案和一种参数调整方案。以下是详细的架构设计与参数调整指南:
方案一:Claim Check Pattern(声明检查模式 / 引用模式)—— 【强烈推荐 🌟】
这是处理大报文最标准、最优雅的架构设计方案。核心思想是“将数据与通知分离”。
架构设计:
- 外部存储:引入对象存储(如阿里云OSS、AWS S3、MinIO)或分布式文件系统(HDFS、NAS)。
- Producer侧:
- 业务方在发送消息前,先将10MB+的图片或JSON上传到对象存储。
- 获取该文件的下载URL(或对象Key)。
- 将URL和相关元数据(如业务ID、文件大小、校验和)组装成一个很小的JSON(通常不到1KB),发送到Kafka。
- Consumer侧:
- 消费者从Kafka拉取这套包含URL的小消息。
- 解析URL,从对象存储中下载真实的图片或大JSON进行业务处理。
- 处理完成后提交Kafka Offset。
优点:完全不影响Kafka集群的性能和稳定性;支持任意大小的文件(GB级也没问题)。
缺点:引入了额外的存储依赖;增加了发送和消费的延迟(需要额外的网络I/O)。
方案二:消息分片与组装(Chunking)—— 【适合无外部存储的场景】
如果公司架构限制,绝对不允许引入外部对象存储,可以在应用层对大消息进行切片。
架构设计:
- Producer侧:
- 将10MB的报文在内存中拆分成10个1MB的小分片(Chunk)。
- 为每个分片生成相同的
MessageID,并附加Chunk_Index(当前分片序号)和Total_Chunks(总分片数)。 - 将这些分片以相同的
Routing Key(确保进入同一个Partition以保证顺序)发送到Kafka。
- Consumer侧:
- 消费者接收到分片后,将其暂存在本地内存或Redis/数据库中。
- 当检测到某个
MessageID的所有分片(0到9)都已到达时,进行拼接还原。 - 还原成完整大报文后再交由业务逻辑处理。
优点:无需引入对象存储;符合Kafka处理小消息的特性。
缺点:应用层开发复杂度极高;Consumer端需要处理状态(如何处理丢失的分片、如何清理超时未组装的分片);极端情况下可能导致Consumer内存溢出(OOM)。
方案三:端到端压缩(Compression)—— 【仅适用于大JSON/文本】
如果报文主要是大JSON或XML,通常具有极高的压缩比(可达 1/5 到 1/10)。
架构调整:
- 在Producer端开启强力压缩算法。Kafka支持
gzip,snappy,lz4,zstd。对于大文本,推荐使用zstd或gzip。 - 注意:这种方案对高清图片(JPEG/PNG)、视频等已经压缩过的数据无效,强行压缩只会消耗CPU而体积不会减小。
配置示例(Producer):
compression.type=zstd方案四:暴力修改Kafka参数(不推荐,但若必须这么做请参考)
如果业务线非常强势,拒绝改代码,且数据量不大(例如偶尔才有一条10MB的消息),可以通过修改Kafka全链路的参数来硬扛。
注意:必须同时修改 Broker、Producer 和 Consumer 的参数,否则会抛出 RecordTooLargeException 等错误。
1. Broker 端参数调整(server.properties)
需要重启Broker。假设我们要支持最大15MB(预留一些缓冲):
# 允许接收的最大消息大小 (单位: bytes) -> 15MB = 15728640
message.max.bytes=15728640
# 副本同步拉取的最大字节数 (必须 >= message.max.bytes,否则会导致副本无法同步!)
replica.fetch.max.bytes=157286402. Producer 端参数调整
# 允许发送的最大请求大小 (必须 >= Broker的message.max.bytes)
max.request.size=15728640
# 缓冲区内存大小(发送大消息时,32MB默认值可能不够,建议调大)
buffer.memory=67108864 # 64MB
# (可选) 增加请求超时时间,大消息网络传输较慢
request.timeout.ms=600003. Consumer 端参数调整
# 每个Partition返回的最大字节数 (必须 >= Broker的message.max.bytes)
max.partition.fetch.bytes=15728640
# 消费者一次Fetch请求的最大字节数 (通常设置得比max.partition.fetch.bytes大)
fetch.max.bytes=52428800 # 50MB
# (可选) 因为处理大消息耗时较长,增加心跳和会话超时时间防止Rebalance
session.timeout.ms=30000
max.poll.interval.ms=300000 此方案的致命隐患:
- 内存爆雷:Kafka Broker 在处理消息时按
message.max.bytes分配内存,大量大消息并发时极易导致 Broker OOM。 - 网络阻塞:10MB 的消息在传输时会独占网络连接,导致后面的小消息(如心跳、控制信息)被阻塞(Head-of-line blocking),进而引发 Consumer 频繁掉线和 Rebalance。
💡 总结与架构选型建议
| 业务场景 | 报文类型 | 推荐方案 | 说明 |
|---|---|---|---|
| 超大文件,高并发 | 高清图片、视频、PDF | 方案一:Claim Check (OSS+Kafka) | 最优解,彻底解决容量和性能问题。 |
| 超大文本报文 | 大JSON、XML (如批处理数据) | 方案三:Zstd 压缩 | 如果压缩后小于1MB,直接用此方案,改动成本最低。 |
| 内网环境,无对象存储 | 图片、日志块 | 方案二:消息分片 | 开发成本高,但不需要修改Kafka底层参数。 |
| 极少出现的大消息 | 偶尔产生的异常大JSON | 方案四:调大Kafka参数 | 仅限低频场景(如一天就几条),且上限不要超过15MB。 |
行动建议:
作为架构师,建议您强烈推动业务方采用 “方案一(OSS + Kafka)”。您可以向业务方说明:“Kafka 是高速公路(适合跑大量小汽车),不是铁路(不适合跑重载火车)。把大文件直接塞进 Kafka 会导致整个集群瘫痪,影响公司所有依赖 Kafka 的业务。”