 播面
播面 Kafka的网络模型中,Network Threads和IO Threads分别负责什么工作?
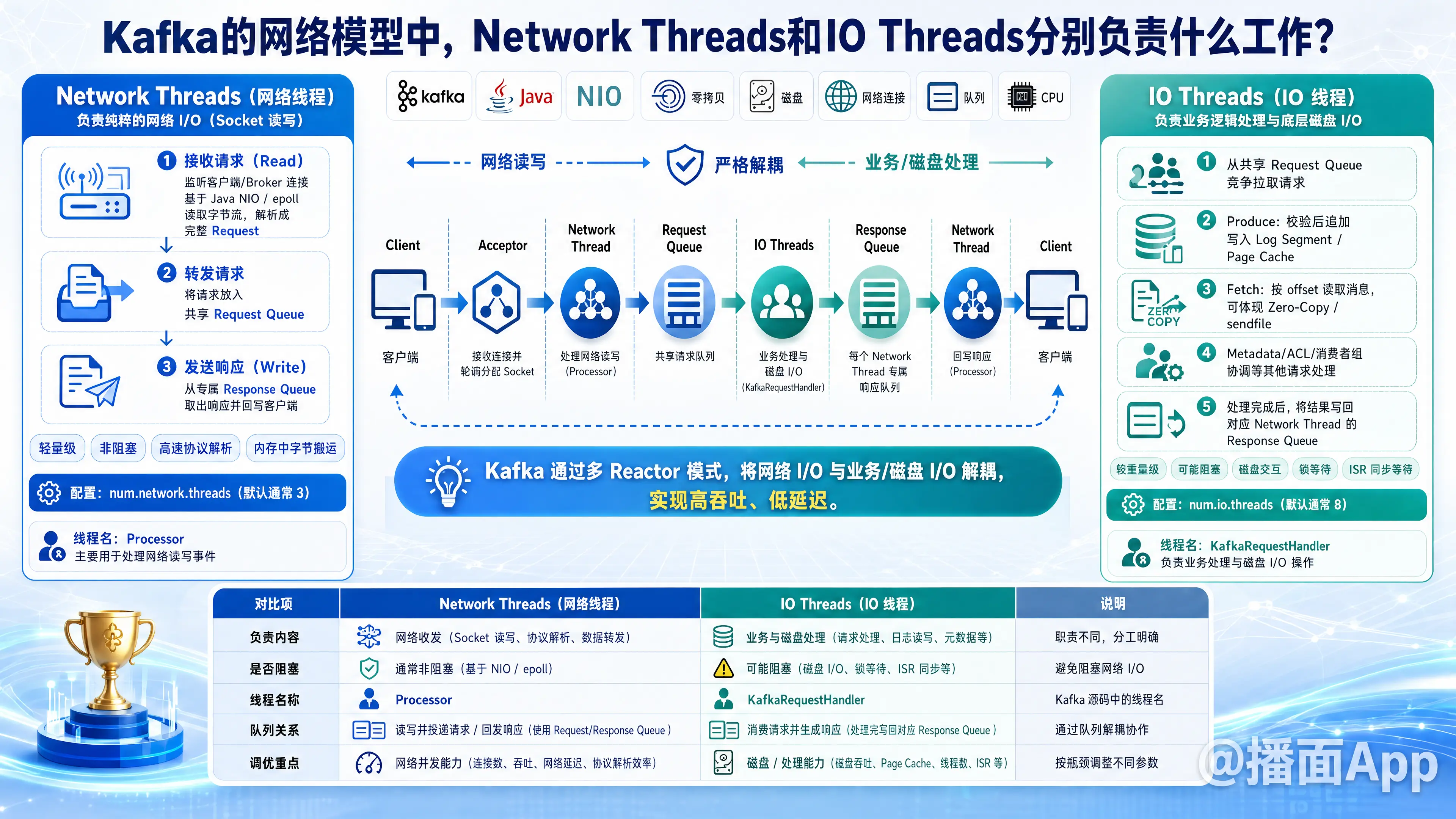
在 Kafka 的网络模型中,Network Threads(网络线程) 和 IO Threads(IO 线程/工作线程) 扮演着完全不同但相互配合的角色。
Kafka 的网络模型基于 多主从 Reactor 模式(Multi-Reactor Pattern) 设计。为了实现高吞吐量和低延迟,Kafka 将“网络数据的读写”和“实际的业务/磁盘处理”进行了严格的解耦,这就分别对应了这两种线程。
以下是它们各自的具体职责和工作机制:
1. Network Threads(网络线程)
核心职责:负责纯粹的网络 I/O 操作(Socket 的读写),不涉及任何复杂的业务逻辑或磁盘读写。
在 Kafka 源码中,它们通常被称为 Processor 线程。
- 接收请求(Read): 使用 Java NIO(非阻塞 IO,如 epoll),监听客户端或其他 Broker 发来的网络连接。当 Socket 中有数据可读时,它将字节流读取出来,解析成一个完整的 Kafka 请求(Request)。
- 转发请求: 将解析好的完整请求,放入一个全局共享的 请求队列(Request Queue) 中,等待 IO 线程来处理。
- 发送响应(Write): 每个 Network Thread 都有自己专属的 响应队列(Response Queue)。当 IO 线程处理完请求后,会将结果放入这个响应队列。Network Thread 会不断轮询自己的响应队列,取出响应数据,并通过 Socket 发送回客户端。
- 特点: 非常轻量级、速度极快、非阻塞。因为它们只在内存中处理字节的搬运和简单的协议解析。
- 配置参数:
num.network.threads(默认值通常是 3,生产环境可根据 CPU 核数和网络并发量适当调大)。
2. IO Threads(IO 线程)
核心职责:负责真正的业务逻辑处理和底层的磁盘 I/O 操作。
在 Kafka 源码中,它们通常被称为 KafkaRequestHandler 线程。
- 获取任务: 它们作为一个线程池,不断地从共享的 请求队列(Request Queue) 中竞争拉取请求。
- 处理业务逻辑(核心):
- 如果是 Produce(生产)请求: IO 线程负责验证请求,并将消息数据追加写入到本地磁盘的日志文件(Log Segment)中(通常是写入操作系统的 Page Cache)。
- 如果是 Fetch(消费)请求: IO 线程负责根据 offset 从磁盘(或 Page Cache)中读取消息数据(通常利用 Zero-Copy 零拷贝技术
sendfile)。 - 如果是 Metadata(元数据)等其他请求: 处理集群状态的查询、ACL 权限校验、消费者组的协调等。
- 返回结果: IO 线程处理完业务逻辑并生成响应结果后,会根据请求原本是由哪个 Network Thread 接收的,将响应放入对应 Network Thread 的 响应队列(Response Queue) 中。
- 特点: 较重量级、可能会阻塞。因为它们需要与磁盘打交道(即使有 Page Cache,也可能发生缺页中断),或者需要等待锁、等待 ISR 副本同步等。
- 配置参数:
num.io.threads(默认值通常是 8,建议至少设置为磁盘数量的倍数,因为主要瓶颈通常在磁盘)。
3. 它们是如何协同工作的?(完整请求流程)
为了更好理解,我们可以看一个客户端请求在 Kafka 内部流转的完整生命周期:
- 建立连接: 客户端发起连接,Kafka 的
Acceptor线程接收连接,并将该 Socket 连接轮询分配给某一个 Network Thread。 - 接收数据: Network Thread 监听到 Socket 有数据,读取并拼装成完整的 Request。
- 入队: Network Thread 将 Request 放入全局共享的
Request Queue。 - 处理业务: 某一个空闲的 IO Thread 从
Request Queue取出该请求,执行磁盘读写(如把消息存入磁盘)。 - 生成响应: IO Thread 处理完毕,生成 Response,并将其放入当初接收该请求的那个 Network Thread 的
Response Queue中。 - 发送数据: 该 Network Thread 从自己的
Response Queue取出 Response,通过 Socket 发送给客户端。
4. 为什么要这样拆分?(架构设计的意义)
Kafka 这样设计的核心目的是 防止阻塞,最大化吞吐量:
- 网络与磁盘速度不匹配: 网络传输速度和磁盘读写速度差异巨大。如果放在一个线程里做,当磁盘发生阻塞(例如磁盘高负载、刷盘)时,该线程就无法接收新的网络请求,导致网络连接堆积甚至超时。
- 职责分离: Network Thread 专注于快速的 NIO 读写,保证网络连接的高效运转;IO Thread 专注于重度计算和磁盘操作。即使所有的 IO Thread 都被磁盘读写短暂阻塞,Network Thread 依然能快速接收新请求并放入队列(起到削峰填谷的作用)。